
以下是一個關於HDFS操作的技術文章大綱,主題聚焦於三種客户端操作方式:命令行操作、網頁界面操作(通過9870端口)和Java代碼操作。
1. 引言
- 介紹Hadoop分佈式文件系統(HDFS)的基本概念和重要性。
- 概述三種操作方式:命令行(client1)、網頁界面(client2)和Java API(client3)。
- 説明文章目標:解析每種操作的具體步驟、優缺點,以及它們之間的互補關係。
2. 命令行操作(client1:HDFS命令行客户端)
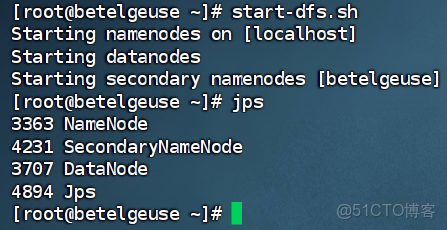
2.1 掌握HDFS相關進程的啓停管理命令
一鍵啓停:
HadoopHDFS組件內置了HDFS集羣的一鍵啓停腳本。
原理:在執行此腳本的機器上,啓動/關閉SecondaryNameNode,讀取core-site.xml內容(fs.defaultFS項),確認NameNode所在機器,啓動/關閉NameNode,讀取workers內容,確認DataNode所在機器,啓動/關閉全部DataNode
$HADOOP_HOME/sbin/start-dfs.sh,一鍵啓動HDFS集羣
$HADOOP_HOME/sbin/stop-dfs.sh,一鍵關閉HDFS集羣除了一鍵啓停外,也可以單獨控制進程的啓停
$HADOOP_HOME/sbin/hadoop-daemon.sh,此腳本可以單獨控制所在機器的進程的啓停
用法:hadoop-daemon.sh(start|status|stop)(namenode|secondarynamenode|datanode)
$HADOOP_HOME/bin/hdfs,此程序也可以用以單獨控制所在機器的進程的啓停
用法:hdfs--daemon(start|status|stop)(namenode|secondarynamenode|datanode)
2.2 HDFS文件系統操作命令
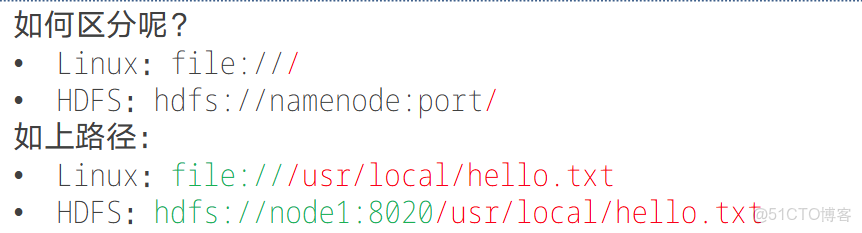
HDFS作為分佈式存儲的文件系統,有其對數據的路徑表達方式。•HDFS同Linux系統一樣,均是以/作為根目錄的組織形式。
在使用時,Linux 本地路徑與 HDFS 路徑形式雖有相似之處(如都可能呈現為/usr/local/hello.txt),但可通過協議頭區分,Linux 路徑對應file:///協議頭,HDFS 路徑對應hdfs://namenode:port/協議頭(例如hdfs://node1:8020/usr/local/hello.txt);且這些協議頭通常可省略,系統會根據參數需求自動識別是 Linux 路徑還是 HDFS 路徑,除非明確需要寫或不寫會出現 BUG,否則一般無需手動添加。
關於HDFS文件系統的操作命令,Hadoop提供了2套命令體系。用法完全一致,任選其一即可。
hadoop命令(老版本用法)
用法:hadoopfs[genericoptions]
hdfs命令(新版本用法)
用法:hdfsdfs[genericoptions]2.3創建 HDFS 目錄並驗證
創建命令
hadoop fs -mkdir -p /hdfs_demo/input
驗證命令
hadoop fs -ls /(-p選項表示遞歸創建父目錄,即使/hdfs_demo不存在也會自動創建)

2.4上傳本地文件到 HDFS
本地創建測試文件test.txt,內容為hello hdfs。
echo "hello hdfs" > test.txt上傳並驗證上傳結果
上傳
hadoop fs -put test.txt /hdfs_demo/input
驗證
hadoop fs -ls /hdfs_demo/input2.4查看 HDFS 文件內容
讀取並查看 HDFS 中文件的完整內容。
查看
hadoop fs -cat /hdfs_demo/input/test.txt2.5追加本地數據到 HDFS 文件
本地創建新文件append.txt,內容為append data。
創建
echo "append data" > append.txt
追加
hadoop fs -appendToFile append.txt /hdfs_demo/input/test.txt
驗證
hadoop fs -cat /hdfs_demo/input/test.txt2.6複製 HDFS 文件(含重命名)
複製文件並修改名稱,實現文件備份或重命名。
hadoop fs -cp /hdfs_demo/input/test.txt /hdfs_demo/input/test_copy.txt
hadoop fs -ls /hdfs_demo/input
2.7移動 HDFS 文件(含重命名)
命令作用:移動文件到新目錄,或直接重命名文件。
2.8下載 HDFS 文件到本地
命令作用:將 HDFS 文件下載到本地文件系統,用於本地分析或備份。
創建目標目錄
mkdir -p local_demo
下載命令
hadoop fs -get /hdfs_demo/input/test.txt local_demo/
驗證
ls local_demo/2.9刪除 HDFS 文件與目錄
命令作用:清理不再需要的 HDFS 文件和目錄,釋放存儲空間。刪除以後預期輸出中不再包含/hdfs_demo目錄
刪除文件命令
hadoop fs -rm /hdfs_demo/input/test_rename.txt
刪除目錄命令(需遞歸刪除)
hadoop fs -rm -r /hdfs_demo
驗證刪除結果:
hadoop fs -ls /3. 網頁界面操作(client2:通過9870端口的Web UI)
3.1訪問NameNode的Web界面
HDFS(Hadoop 分佈式文件系統)的 Web 管理界面默認路徑取決於 Hadoop 版本和集羣配置。 對於大多數 Hadoop 2.x 及早期版本,默認路徑為:
http://<namenode-host>:50070從 Hadoop 3.x 開始,默認端口調整為 9870,路徑變為:
http://<namenode-host>:9870這是因為 Hadoop 社區將部分舊端口重新規劃以避免衝突。其中 <namenode-host> 是 NameNode 節點的主機名或 IP 地址。
3.2驗證默認路徑的方法
3.2.1通過 HDFS 配置文件:
直接查看 HDFS 的核心配置文件 hdfs-site.xml,找到以下屬性:
<property>
<name>dfs.namenode.http-address</name>
<value>namenode-host:port</value>
</property>例如:
<value>master:50070</value> <!-- Hadoop 2.x -->
<value>master:9870</value> <!-- Hadoop 3.x -->3.2.2通過命令行工具
使用 Hadoop 自帶的命令行工具獲取 NameNode 的 Web 地址:
hadoop fs -getconf -confKey dfs.namenode.http-address輸出結果即為當前集羣的 Web UI 路徑,例如:
master:500703.2.3 也可以直接通過本機ip訪問
在終端中輸入ifconfig獲取本機ip地址,假設為192.168.142.131,則在瀏覽器中輸入
http://192.168.142.131:9870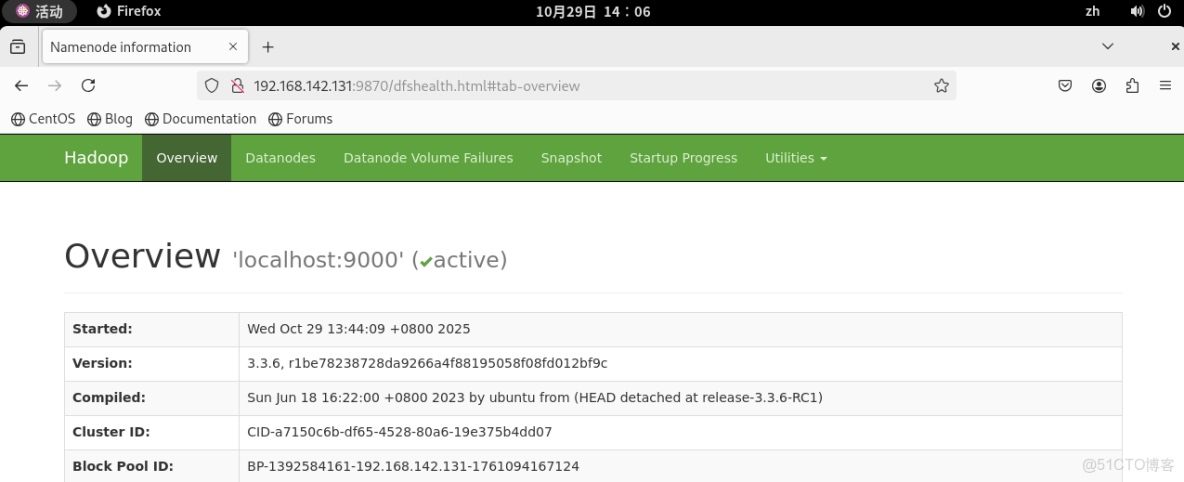
3.3 通過web來操作文件
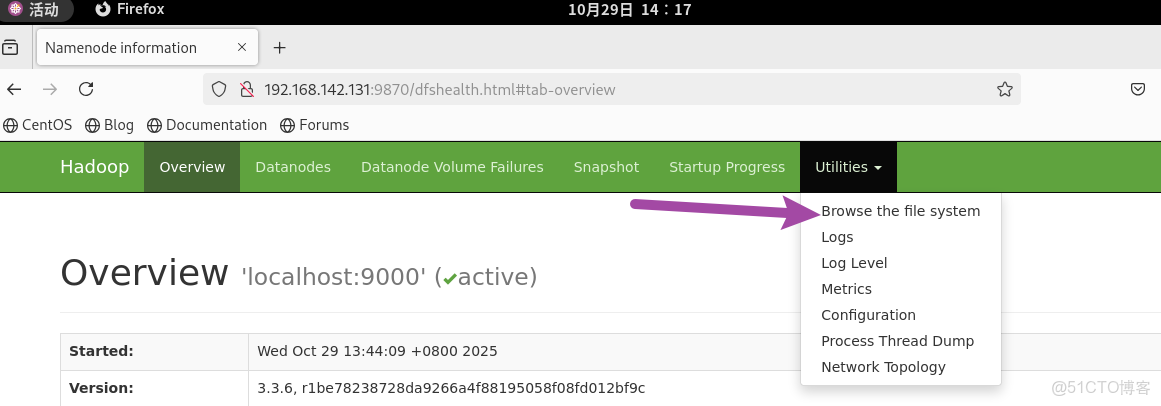
使用 WEB 瀏覽操作 HDFS 文件系統可能會遇到權限問題,這是因為 WEB 瀏覽器以匿名用户(dr.who)登錄,僅具有隻讀權限,多數操作無法執行。若要以特權用户在瀏覽器中操作,需在 core-site.xml 中配置相關內容並重啓集羣,但不推薦此做法;HDFS WEBUI 保持只讀權限用於簡單瀏覽即可,賦予高權限會帶來嚴重安全問題,造成數據泄露或丟失。
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value> <!-- 此處替換為你要賦予權限的特權用户名,如hadoop -->
</property>4. IDEA圖形操作(client3:Java API客户端)
4.1 概覽
在大數據開發中,HDFS 命令行操作雖靈活但不夠直觀。藉助 JetBrains 系列 IDE(如 DataGrip、IDEA、PyCharm)的 Big Data Tools 插件,我們可以在 Windows 本地以圖形化方式操作 Linux 虛擬機上的 HDFS 集羣。
4.2 準備工作(我們在之前的步驟已經啓動HDFS集羣)
運行環境:Windows 本地 運行 DataGrip,Linux 虛擬機 運行 HDFS 集羣。
通信方式:Windows 通過網絡訪問虛擬機的 HDFS 服務端口,實現圖形化操作。
臨時關閉虛擬機防火牆:systemctl stop firewalld
4.3 Windows 本地環境配置
為使 Big Data Tools 插件在 Windows 上正常工作,需配置 Hadoop 依賴環境。
解壓 Hadoop 安裝包:將 Hadoop 安裝包(如 hadoop-3.3.4.tar.gz)解壓到 Windows 本地路徑,例如 E:\hadoop-3.3.6。解壓的時候如果提示需要管理員,請按住shift然後再右鍵會出現以管理員身份解壓的提示
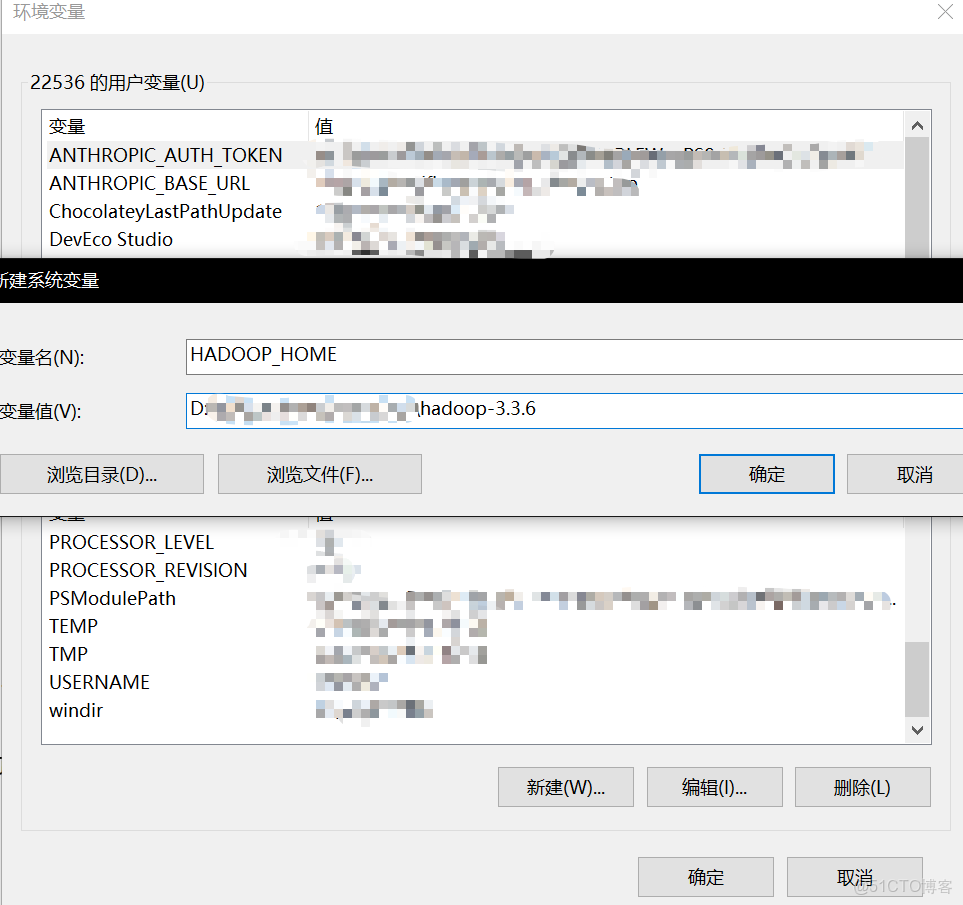
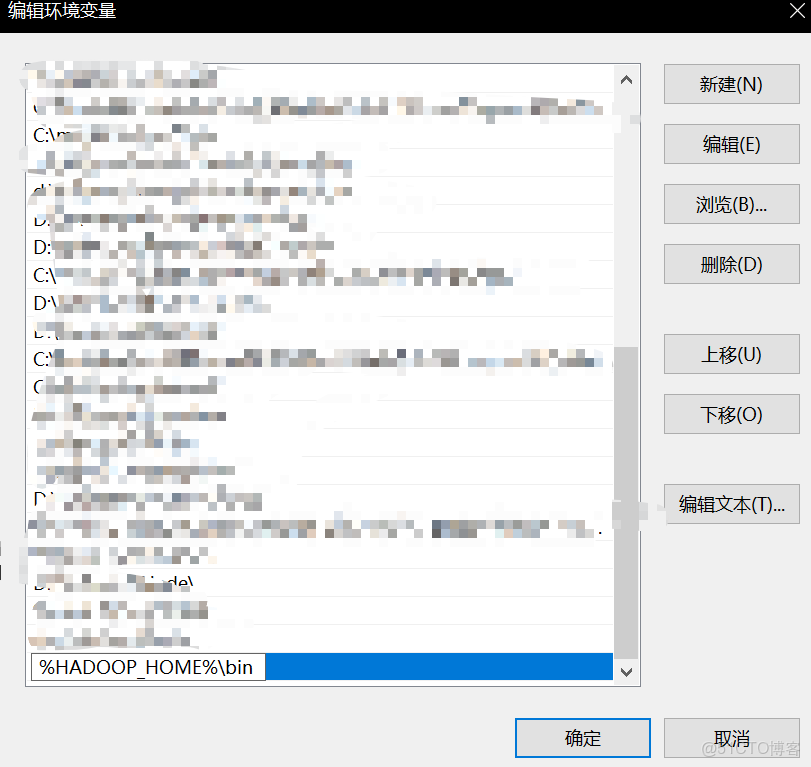
右鍵 “此電腦”→“屬性”→“高級系統設置”→“環境變量”。新建系統變量 HADOOP_HOME,值為 E:\hadoop-3.3.6(以自己電腦實際為準)。編輯Path 變量,添加 %HADOOP_HOME%\bin。
下載並放置依賴文件:下載 hadoop.dll 和 winutils.exe(地址:
https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/hadoop.dllhttps://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/winutils.exe
如果無法訪問請自行尋找鏡像下載),並將其放入 E:\hadoop-3.3.4\bin 目錄。
4.4 安裝並配置Big Data Tools插件
打開IDEA,在插件欄安裝Big Data Tools,然後重啓IDEA
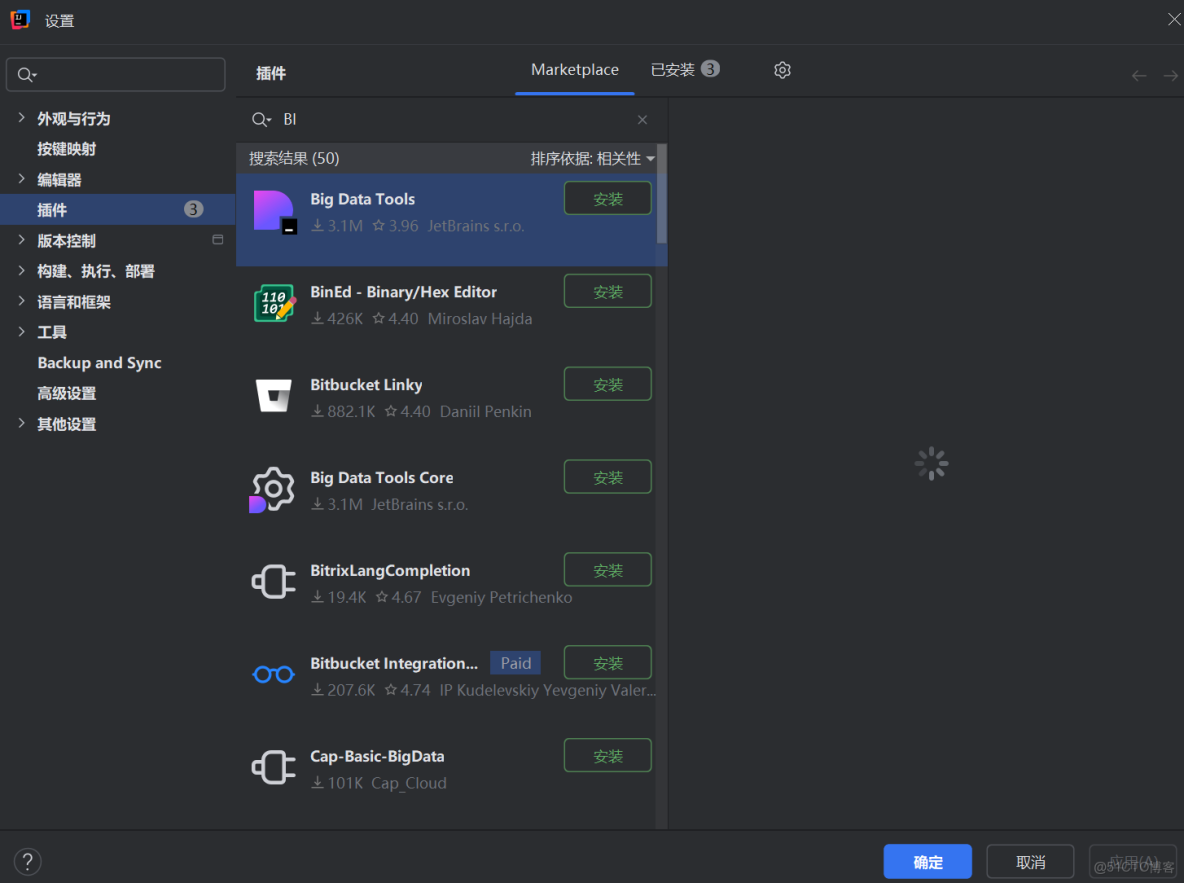
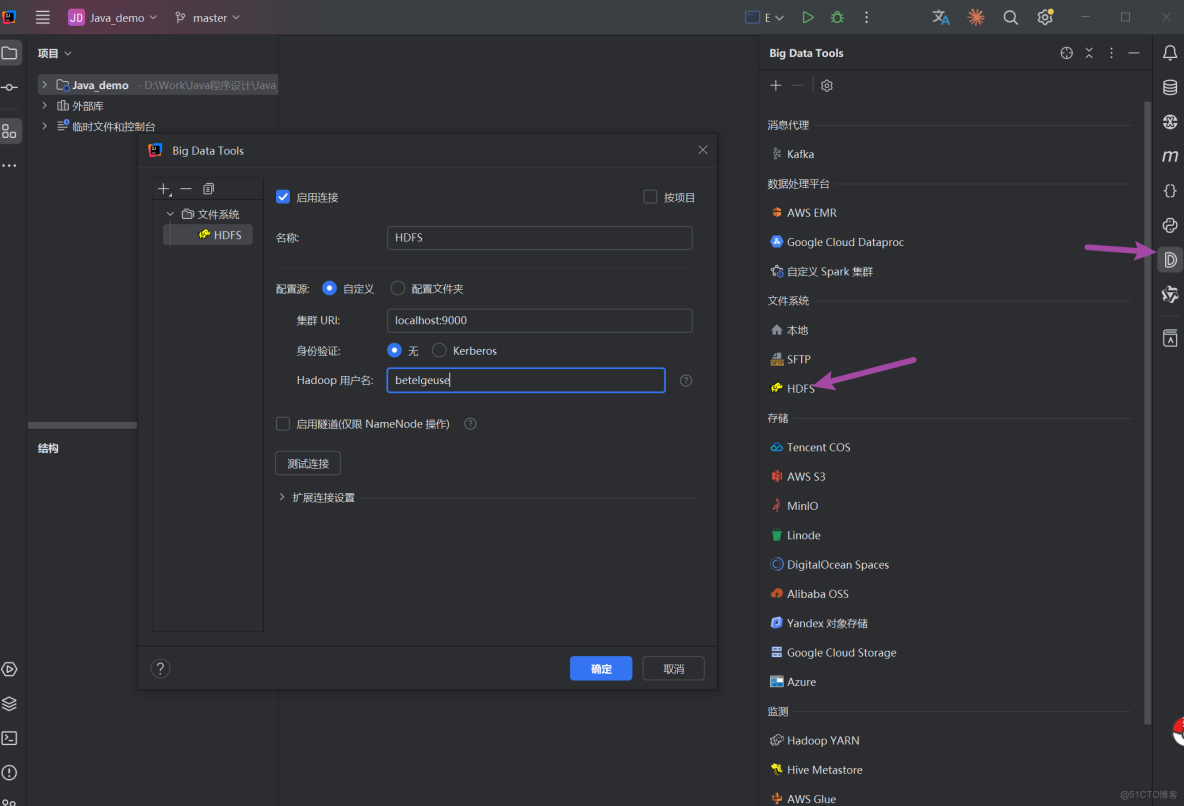
如果連接有問題,指定Windows上解壓的Hadoop安裝文件夾的etc/hadoop目錄也可以,會自動讀取配置文件連接上HDFS
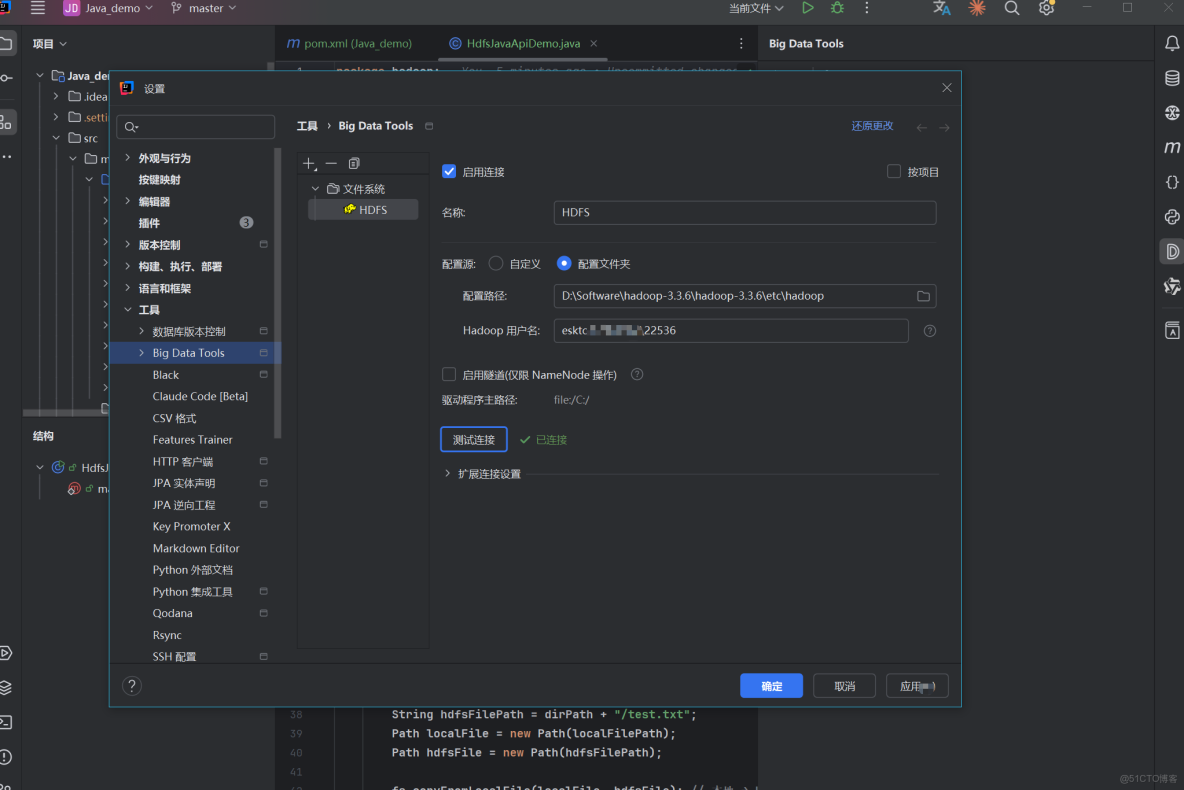
如果還是連不上:(
1.確認 hadoop.dll 和 winutils.exe 版本與 Hadoop 完全匹配
2.檢查並修復環境變量配置,確保之前的系統環境變量依據自己的路徑設置正確
3.將 hadoop.dll 複製到系統目錄(關鍵!)將 D:\Software\hadoop-3.3.6\hadoop-3.3.6\bin\hadoop.dll 複製到 C:\Windows\System32 目錄,解決系統級的本地庫加載問題。
5. 操作方式之間的聯繫與比較
- 功能互補:
- 命令行(client1)用於快速腳本執行,網頁(client2)用於監控,Java(client3)用於程序集成。
- 示例場景:通過命令行批量上傳數據,用網頁UI驗證狀態,Java代碼實現自動化處理。
- 優缺點比較:
- 效率:命令行最高,Java次之,網頁最低。
- 易用性:網頁最友好,命令行和Java需技術背景。
- 適用場景:命令行適合運維,網頁適合監控,Java代碼適合開發。
- 整合建議:在實際項目中,結合使用——例如,用Java構建應用,用命令行調試,用網頁監控集羣。
