
在模塊化RAG(Retrieval-Augmented Generation)設計中,各種操作模式通過模塊化的方式協同工作,形成了一個名為 RAG流 的工作流程。這個 RAG流 可以被視為由多個子函數組成的圖形結構。通過控制邏輯,這些子函數會按預定的順序執行,同時也能根據需求進行條件判斷、分支或循環。
這種模塊化特性讓RAG系統能夠靈活應對不同的應用場景,並且提升了系統的設計效率和擴展性。在分析現有的RAG方法時,我們可以看到,模塊化的結構使得RAG系統可以在處理複雜任務時更具適應性。
本章將詳細介紹幾種常見的 RAG模式,包括:
- 線性模式:在這個模式下,各個模塊按順序依次執行,每個步驟的輸出作為下一個步驟的輸入,適用於順序性較強的任務。
- 條件模式:根據特定的條件,選擇性地執行不同的模塊操作。這個模式能夠處理具有分支或選擇性的任務。
- 分支模式:與條件模式類似,但它更多地用於任務中涉及多個並行處理路徑的場景。
- 循環模式:當某些操作需要重複執行時,循環模式便會派上用場。它適合那些需要反覆處理相似任務的應用。
通過這些模式的結合,RAG系統不僅能夠高效地處理多樣化的任務需求,還可以在面對複雜任務時保持靈活性與擴展性。
1 線性模式
在 RAG系統 中,線性模式 是最簡單且最常見的工作流模式。其核心流程包括幾個主要模塊:預檢索(Pre-Retrieval)、檢索、後檢索(Post-Retrieval) 和 生成模塊。這些模塊按順序依次進行處理,如圖示。值得注意的是,當預檢索和檢索後處理模塊缺失時,線性模式會簡化為一種稱為 樸素檢索增強生成(Naive RAG) 的基本範式,僅包含檢索和生成過程。

為了提升生成的質量,常見的線性RAG流通過以下幾個步驟優化:
- 預檢索階段:這一階段引入了查詢變換模塊,通常採用查詢重寫或者隱式文檔擴展(HyDE)等操作符。通過這些變換,查詢能夠更好地適應檢索需求,提高檢索的相關性。
- 檢索階段:在這一階段,系統通過檢索工具(如BM25)從外部知識庫中獲取與重寫後的查詢高度相關的文檔或上下文信息。
- 後檢索階段:檢索結果進一步優化,通常通過排序模塊對檢索的結果進行調整,使得最終選出的文檔最能滿足生成需求。
- 生成模塊:最終,通過生成模型(例如GPT或T5等)處理優化後的文檔上下文,產生高質量的回答或生成內容。
一個典型的線性RAG流模式是:“重寫-檢索-閲讀(Rewrite-Retrieve-Read,RRR)”方法。該方法在預檢索階段引入了一個查詢重寫模塊。這個模塊基於 T5-large 模型的微調版本,並通過強化學習框架進行優化,將查詢重寫過程建模為 馬爾可夫決策過程(MDP)。
在這個過程中,查詢重寫模塊的輸出質量被視為獎勵信號,強化學習算法通過策略梯度方法來調整和優化生成的查詢,從而確保查詢更符合檢索任務的需求。這種方式提升了檢索的效率,並進一步改善了生成結果的效果。
在檢索階段,RRR方法使用了稀疏編碼模型(如BM25)進行檢索,從外部知識庫中獲取與重寫後的查詢相關的文檔,進一步增強了系統生成內容的準確性和可靠性。
通過這樣的設計,線性模式的RAG流不僅提高了生成質量,還能在實際應用中實現高效的知識提取和生成。
2 條件模式
條件模式 是一種靈活的 RAG流模式,其核心特點是在不同的條件下選擇不同的工作流,以便針對特定場景進行優化。這種模式的關鍵在於一個 路由模塊(Routing Module),該模塊根據輸入問題的特性動態選擇接下來的處理流程,如下圖所示。
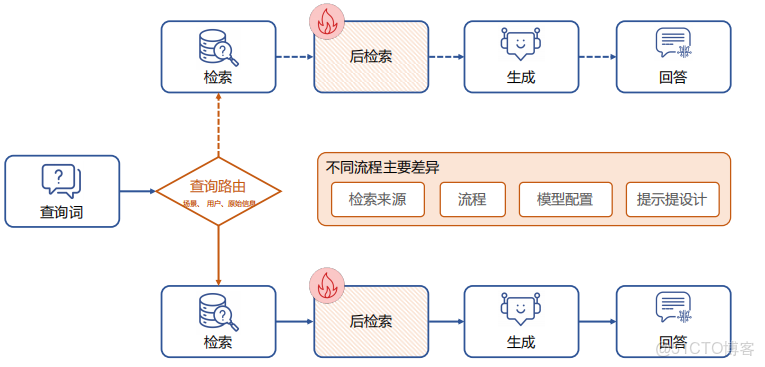
具體來説,當系統接收到不同類型的問題時,它會根據預設的條件或規則決定如何處理。例如,對於涉及嚴肅議題、政治話題或娛樂內容等不同類型的問題,系統會自動切換到不同的處理流程。這種動態路由機制顯著提升了系統處理多樣化任務的能力,使得系統能夠靈活應對各種複雜場景。
條件模式的分支流 主要體現在以下幾個方面:
- 檢索來源:系統會根據問題的性質選擇不同的檢索來源。例如,對於嚴肅問題,系統可能會選擇更可靠的、權威性的來源,而對於娛樂性問題,則可能選擇更多元或創意性的資料。
- 流程選擇:針對不同任務的需求,條件模式可能會調整流程的細節,控制模塊的順序、執行的操作,甚至是否進行一些後處理。
- 模型配置:不同類型的問題可能需要不同的模型配置。比如,嚴肅問題可能使用更精確、保守的模型,而娛樂類問題則可能使用更具創意性和生成自由度的模型。
- 提示設計:根據任務的性質,系統的提示設計(Prompt Design)也會有所不同。對於嚴肅問題,提示可能會更為規範和嚴格,而對於娛樂類問題,提示可能會更具開放性和靈活性。
舉個例子,對於嚴肅性較高的問題(如法律、健康、政治等),系統可能會選擇更加可靠的檢索來源,並對生成的內容設置嚴格的約束,確保信息的準確性和權威性。而對於娛樂類的問題(如電影、遊戲、搞笑等),系統則可以容忍更多的創意和不拘一格的生成,提供富有娛樂性和趣味性的回答。
通過這種方式,條件模式 能夠根據任務的需求動態調整 RAG 各個組件,確保生成的回答既符合場景需求,又保持高相關性和準確性。這種靈活性使得 條件模式 在處理多樣化、複雜性高的任務時具有顯著的優勢,能夠有效提升系統的適應能力和輸出質量。
3 分支模式
分支模式 是 RAG(Retrieval-Augmented Generation) 系統中一種增加結果多樣性和魯棒性的重要設計方式。它通過並行運行多個分支,來生成多樣化的結果,從而提升系統的性能和準確性。
具體來説,分支模式 在某個模塊中生成多個並行的分支,每個分支可以獨立執行相同或不同的 RAG流程。這些分支通常由多個處理模塊組成,每個模塊生成各自的結果。然後,這些分支的結果會通過一個 聚合函數 合併成一箇中間輸出結果。值得注意的是,合併後的結果不一定意味着流程的結束,它們還可以傳遞到後續模塊(如驗證模塊)進行進一步處理。整體流程從生成多個分支、獨立處理、到結果聚合,形成了一個完整的流水線。
與條件模式不同,分支模式 的特點在於同時並行運行多個分支,而不是從多個選項中選擇一個分支。這使得分支模式能夠同時從多個角度進行處理,生成更加豐富和多樣化的結果。
分支模式的結構類型
根據任務需求,分支模式 可以設計為不同的結構,通常分為兩種類型:
- 預檢索分支模式(Pre-Retrieval Branching)
這種模式通過生成多個子查詢並並行檢索,旨在提高檢索的全面性和生成結果的多樣性。具體流程是,首先通過查詢擴展模塊將初始查詢擴展為多個子查詢。每個子查詢然後通過檢索模塊獲取相關文檔,形成文檔集合。這些文檔和相應的子查詢一同送入生成模塊,產生多個答案集合。最終,所有生成的答案通過融合模塊進行整合,形成最終的結果。
這種模式的優勢在於,它能夠從多個角度挖掘潛在信息,增強生成結果的覆蓋度和準確性。它特別適用於需要廣泛搜索和多角度生成的任務。 - 後檢索分支模式(Post-Retrieval Branching)
該模式從單一查詢開始,首先通過檢索模塊獲取多個文檔塊。然後,每個文檔塊被獨立送入生成模塊進行處理,生成對應的結果集合。這些結果最終會通過合併模塊整合,形成最終輸出。
與預檢索分支模式不同,後檢索分支模式的特點在於,它通過單一查詢進行檢索,而並行生成則集中在對不同文檔塊的獨立處理上。這個模式非常適合那些需要從同一查詢結果中挖掘多角度信息的場景,能更好地利用檢索到的內容,提升生成結果的多樣性和質量。
分支模式的優勢
通過並行執行多個分支,分支模式能夠從多個角度生成和整合信息,極大地提升了系統的生成能力和結果質量。它特別適合於處理複雜場景和多任務需求,可以為不同的應用場景提供更加多樣和精準的答案。因此,分支模式在 多任務處理 和 複雜場景 中具有顯著的優勢。
4 循環模式
循環模式 是 RAG(Retrieval-Augmented Generation) 系統中一種重要的設計方式,其核心特點是檢索與生成步驟之間的相互依賴性。通過引入一個 調度模塊 來控制流程,循環模式確保系統可以根據任務需求在不同模塊之間重複執行某些操作。這使得循環模式可以不斷優化流程中的步驟,提升任務的最終效果。
循環模式的基本原理
循環模式可以抽象為一個 有向圖,圖中的節點代表系統中的各個模塊,邊則表示模塊之間的控制流或數據流。當某個模塊的輸出能夠返回到之前的模塊時,系統就形成了一個 循環結構。這樣的設計讓系統可以根據需要在某些步驟之間來回循環,以不斷優化結果,直到達到理想的效果。
判斷模塊
在循環模式中,判斷模塊(Judge Module) 起到了關鍵作用。它用於決定系統是否需要返回到前一個模塊,或者是否繼續向下執行。例如,在每一次生成或檢索之後,判斷模塊可以根據當前的輸出結果、歷史數據、查詢和檢索到的文檔來決定是否繼續迭代。如果決定返回,流程就會進行循環;如果決定不返回,流程則繼續向前執行。這樣,系統能夠根據當前任務的情況動態調整整個流程。
循環模式的類型
循環模式可以進一步細分為三種類型:迭代型循環模式、遞歸型循環模式 和 自適應型(主動型)循環模式。每種模式都適用於不同的場景,提供了靈活的處理方式。
- 迭代型循環模式
迭代型循環模式通過多次執行檢索和生成操作,在每次迭代中逐步優化結果。如下圖所示,在每一步迭代中,系統根據當前的查詢和之前的輸出結果來檢索相關文檔,然後使用這些文檔生成新的輸出。迭代過程通常會設置一個 最大迭代次數的限制,以避免出現無限循環。在每次迭代後,判斷模塊會根據當前的生成結果、歷史輸出、查詢和檢索到的文檔來決定是否繼續迭代。迭代型模式非常適合那些需要逐步收集信息並動態調整的任務,能夠逐漸完善對複雜問題的回答。 - 遞歸型循環模式
遞歸型循環模式則是一種具有明顯依賴性和層次性的檢索方式,如圖所示。每一步操作都依賴於前一步的輸出,並通過不斷深化檢索過程,逐步獲取更深入的信息。遞歸型模式通常遵循類似 樹狀結構 的模式,每次檢索會基於改寫後的查詢進一步展開,以精確定位所需的知識。遞歸型檢索具有明確的 退出機制,以確保在達到終止條件時流程停止,從而避免無限遞歸。此模式適用於需要分步推理或逐層分析的任務,能夠深入挖掘相關信息並生成高質量的回答。 - 自適應型(主動型)循環模式
自適應型循環模式是一種超越傳統被動檢索的方式,得益於大語言模型強大的能力。如圖9.16所示,自適應型模式的核心思想是通過智能體的方式動態調整檢索流程,主動決定何時進行檢索,何時終止流程並生成最終結果。這種模式與傳統的固定流程不同,具有更高的 靈活性 和 智能性。它能夠實時根據任務的需求調整策略,判斷最佳的執行路徑。自適應型檢索通常通過兩種方法來進一步細分:一是 基於提示 的方法,通過設計動態提示來引導模型的檢索;二是 基於指令微調 的方法,通過微調模型來實現更精準的檢索控制。自適應型模式特別適用於複雜任務或動態信息需求的場景,能夠提升檢索效率和生成質量。
循環模式的優勢
通過引入循環結構,循環模式 能夠讓系統在檢索與生成的過程中不斷優化,逐步提升任務的完成效果。無論是 迭代型 的逐步改進,還是 遞歸型 的深度推理,或是 自適應型 的智能控制,循環模式都為 RAG 系統提供了強大的靈活性和處理能力,能夠在面對複雜問題時進行更精確的調整和優化,從而提升生成結果的質量和準確性。