
目錄
一、開門見山,探究網頁結構
二、確定思路
1.拿到頁面源代碼/響應
2.編寫正則,提取頁面數據
3.保存數據
三、步驟詳解
1.初步爬取
2.繞過反爬
3.編寫正則表達式與正則匹配
4.翻頁爬取
5.注意點

Hello,我是蔣星熠Jaxonic!
在浩瀚無垠的技術宇宙中,我是一名執着的星際旅人,用代碼繪製探索的軌跡。
每一個算法都是我點燃的推進器,每一行代碼都是我航行的星圖。
每一次性能優化都是我的天文望遠鏡,每一次架構設計都是我的引力彈弓。
在數字世界的協奏曲中,我既是作曲家也是首席樂手。讓我們攜手,在二進制星河中譜寫屬於極客的壯麗詩篇!
一、開門見山,探究網頁結構
在爬取之前我們要確定需要的數據究竟是在頁面源代碼裏,還是不在頁面源代碼裏(是不是一次性全加載進來的),如果頁面源代碼裏沒有想要的數據,説明還有其它請求獲取的數據。
讓我們打開頁面:
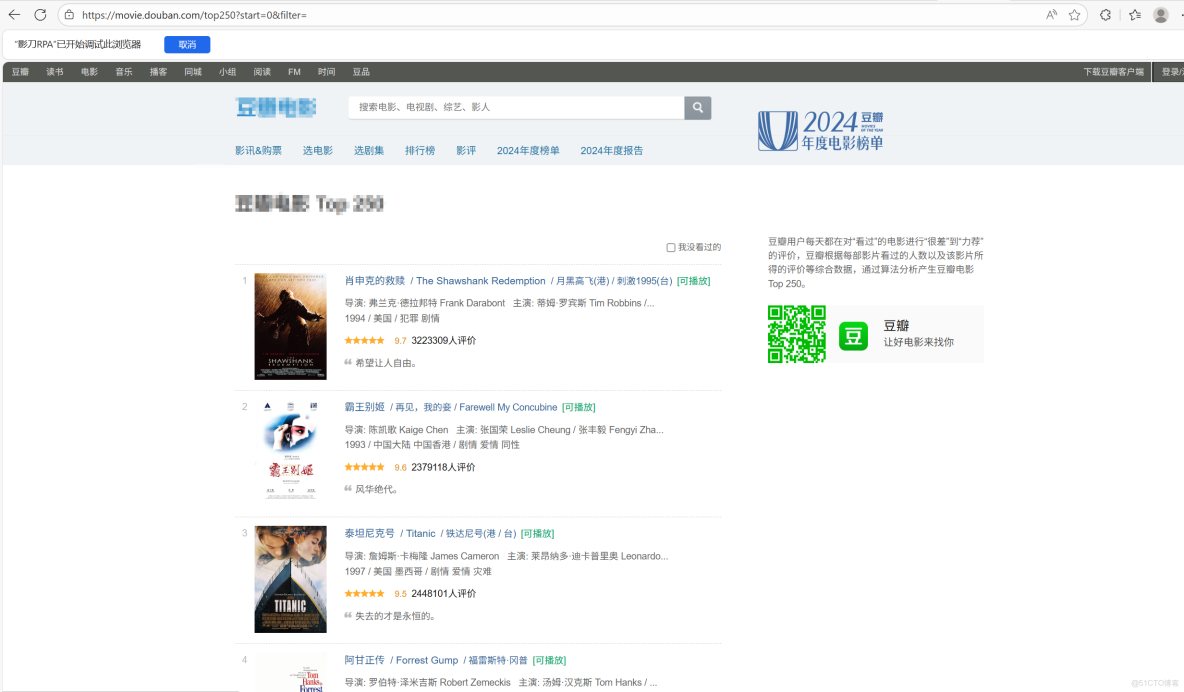
右鍵查看頁面源代碼,Ctrl+/頁面搜索關鍵詞:肖申克
可以看到這時候我們需要的數據是都在頁面源代碼裏的,驗證了我們的想法:該頁面數據是一次性全加載進來的,因此得到以下思路。
二、確定思路
1.拿到頁面源代碼/響應
2.編寫正則,提取頁面數據
3.保存數據
三、步驟詳解
1.初步爬取
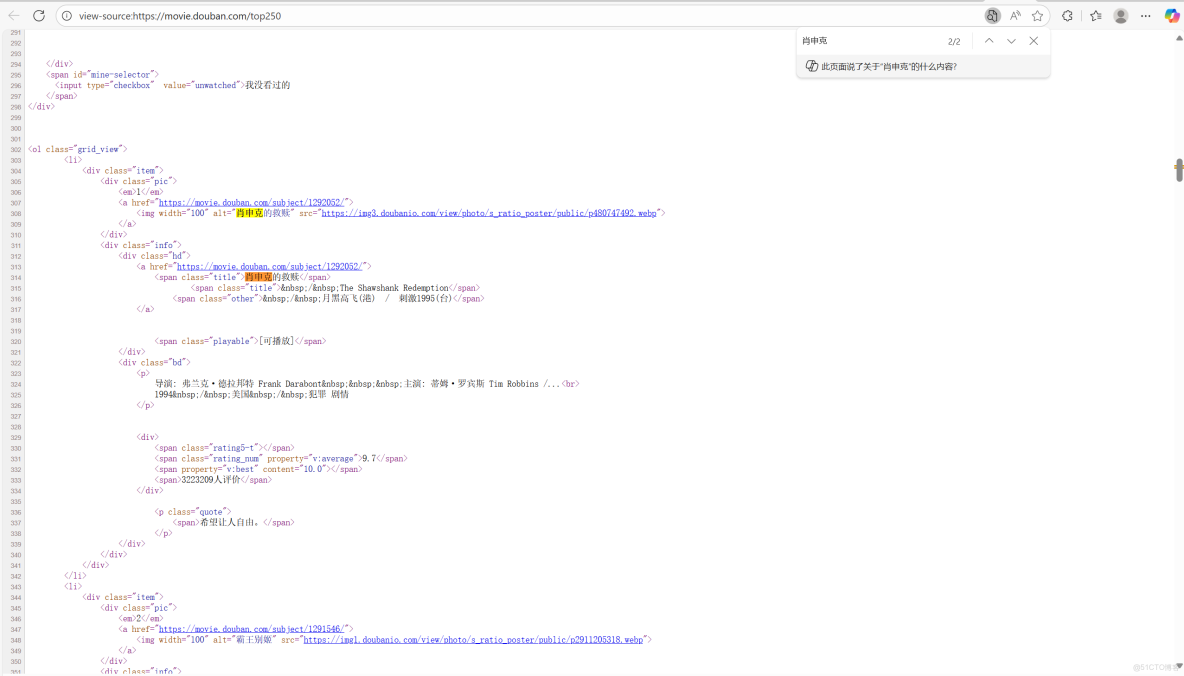
1.1 確定請求方式
接下來按F12,進入開發者工具看看怎麼個事兒,發現有個Top250(這個就是第一頁的頁面url鏈接,即響應就是頁面源代碼)
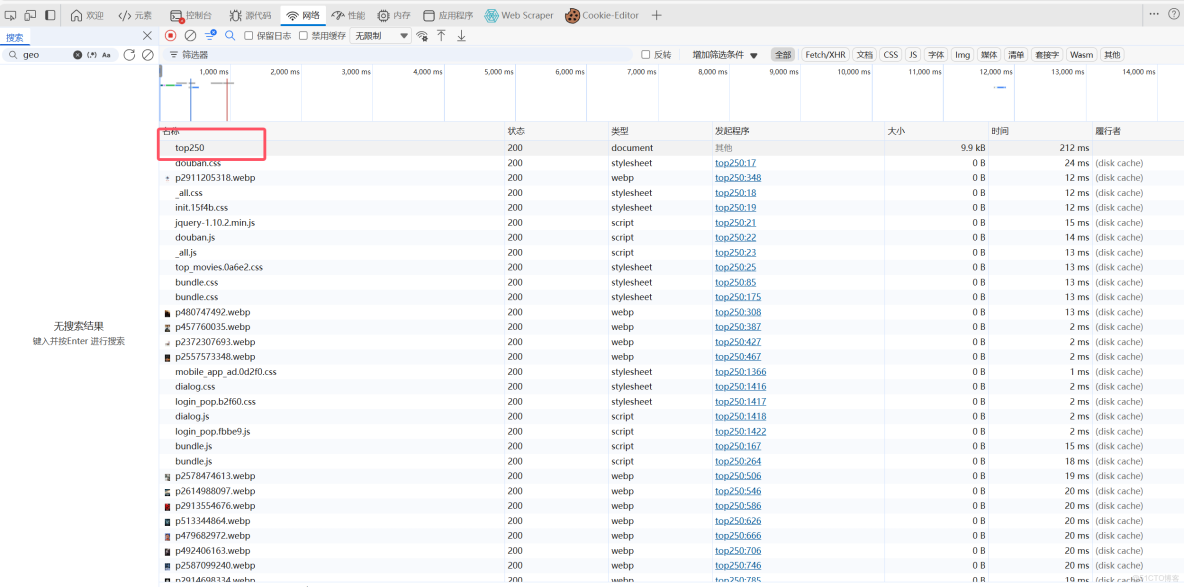
1.2 引入request模塊
發現這裏的請求是Get,因此引入request模塊,導入request.get(頁面鏈接)
import requests
url="https://movie.douban.com/top250"
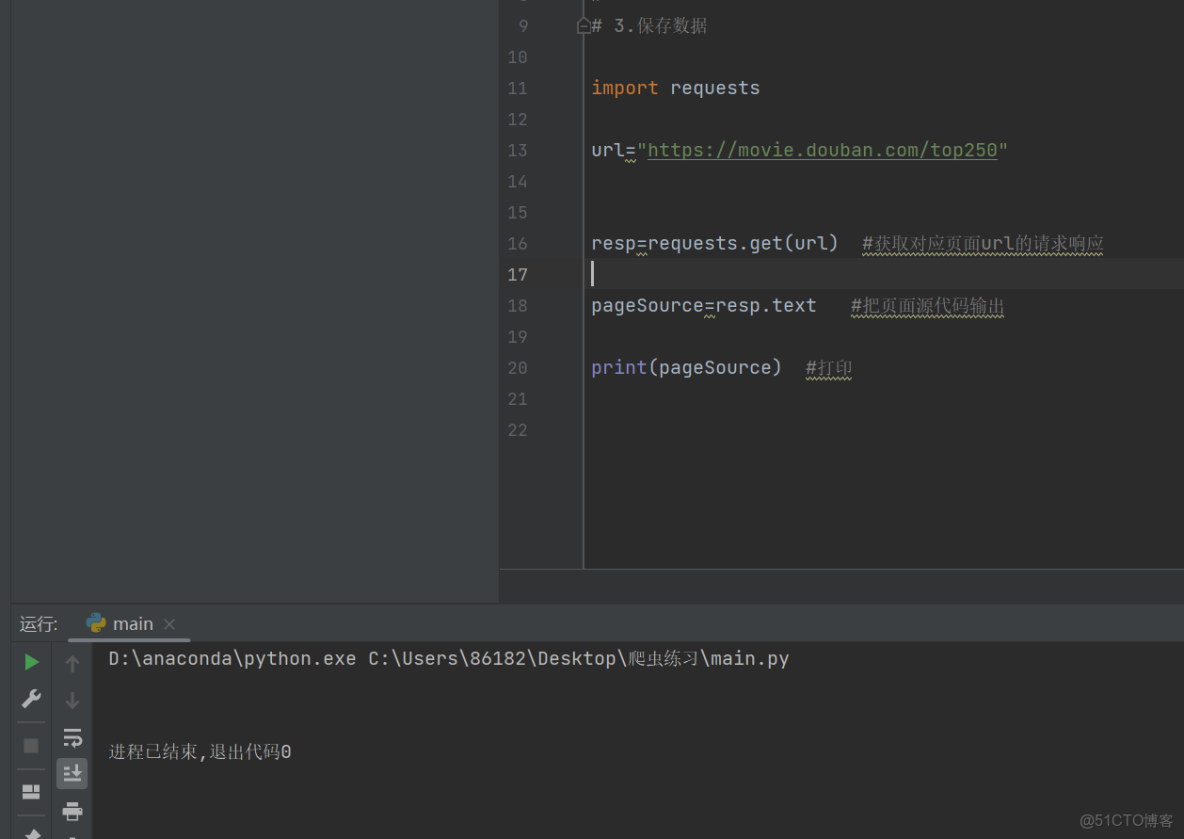
resp=requests.get(url) #獲取對應頁面url的請求響應
pageSource=resp.text #把頁面源代碼輸出
print(pageSource) #打印這時候運行發現結果是空的:
2.繞過反爬
2.1 加入請求頭
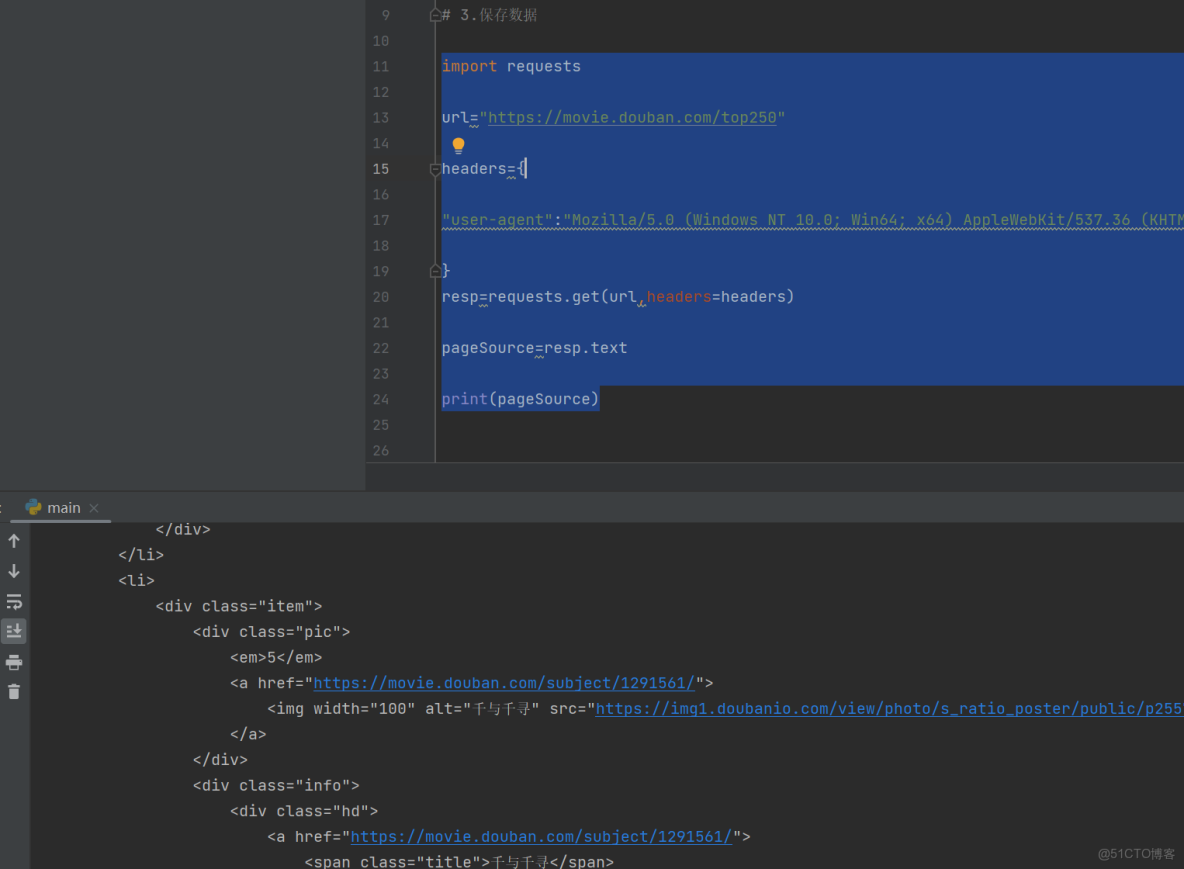
説明缺少一個反爬的驗證,瀏覽器自動攔截了,這時候需要加一個請求頭
import requests
url="https://movie.douban.com/top250"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"
}
resp=requests.get(url,headers=headers)
pageSource=resp.text
print(pageSource)這樣就可以了:
3.編寫正則表達式與正則匹配
3.1 編寫正則表達式
接下來就需要進行數據分離:
引入re模塊,編寫正則表達式:
首先從標題開始提取,從<div >為開頭,目標是第二個框裏的文字內容,這時候需要用到惰性匹配:.*?

3.2 對比表格
特性
.*(貪婪).*?(非貪婪/懶惰)核心原則匹配儘可能多的字符匹配儘可能少的字符別名貪婪模式非貪婪模式、懶惰模式、最小匹配模式回溯行為先吃到尾,再往回找吃一個看一次,滿足就停示例文本Hello "World" and "Universe"Hello "World" and "Universe"正則".*"".*?"匹配結果一個結果:"World" and "Universe"兩個結果:"World"和"Universe"適用場景匹配大塊的、從開始標誌到結束標誌之間的所有內容匹配多個、成對標籤/引號之間的單個內容 這裏樣例的惰性匹配的結果是兩個結果的額原因是開啓了全局模式沒有
g標誌:
- 引擎在找到第一個匹配項後就停止。
有
g標誌:
- 引擎在找到第一個匹配項後,會從上次匹配結束的位置開始,繼續尋找下一個匹配項。
但是這裏還有一個坑,那就是.在匹配的時候是跳過所有非換行符的內容
而re.S可以讓正則表達式中的.匹配換行符
#編寫正則表達式
re.compile(r'
.*?(?P.*?)',re.S)3.3 進行正則匹配
接下來進行正則匹配:
#進行正則匹配
result=obj.finditer(pageSource)
for item in result:
print(item.group("name"))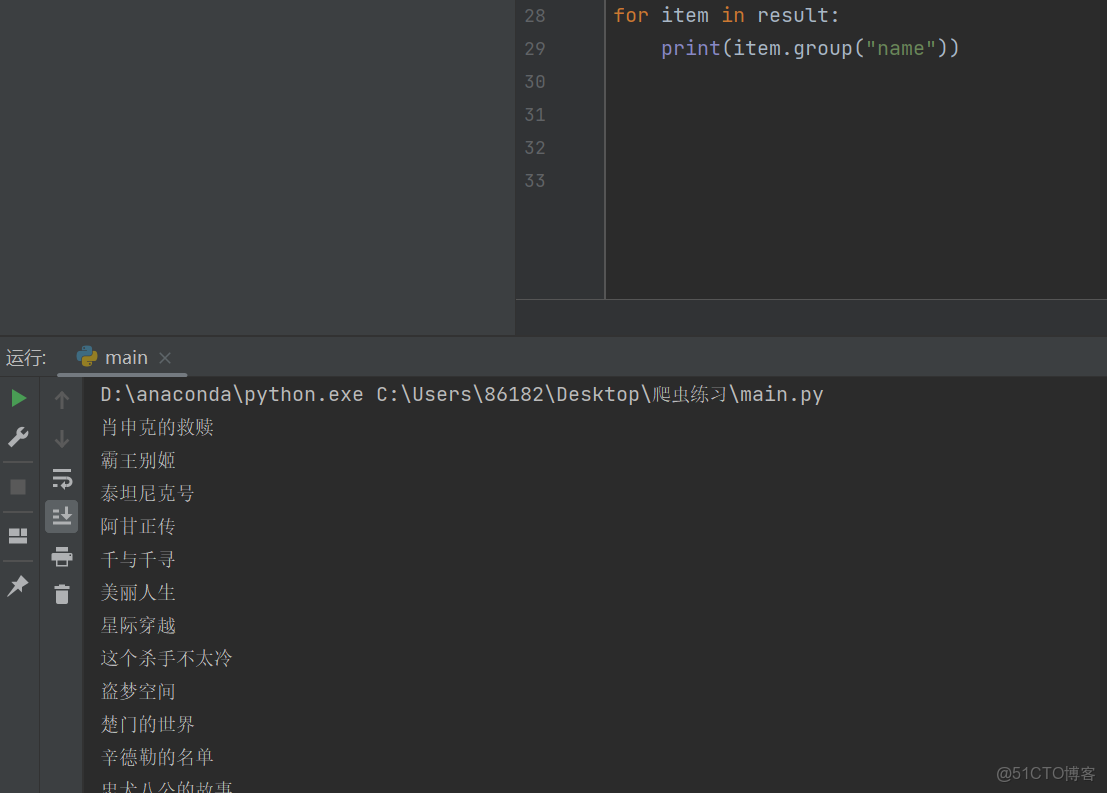
然後根據上面的規則對源代碼進行匹配:
#編寫正則表達式
obj=re.compile(r'
.*?(?P.*?).*?
'
r'.*?
.*?導演: (?P.*?) '
r'.*?
(?P.*?) .*?(?P.*?)'
r'.*?(?P.*?)人評價',re.S)
#進行正則匹配
result=obj.finditer(pageSource)
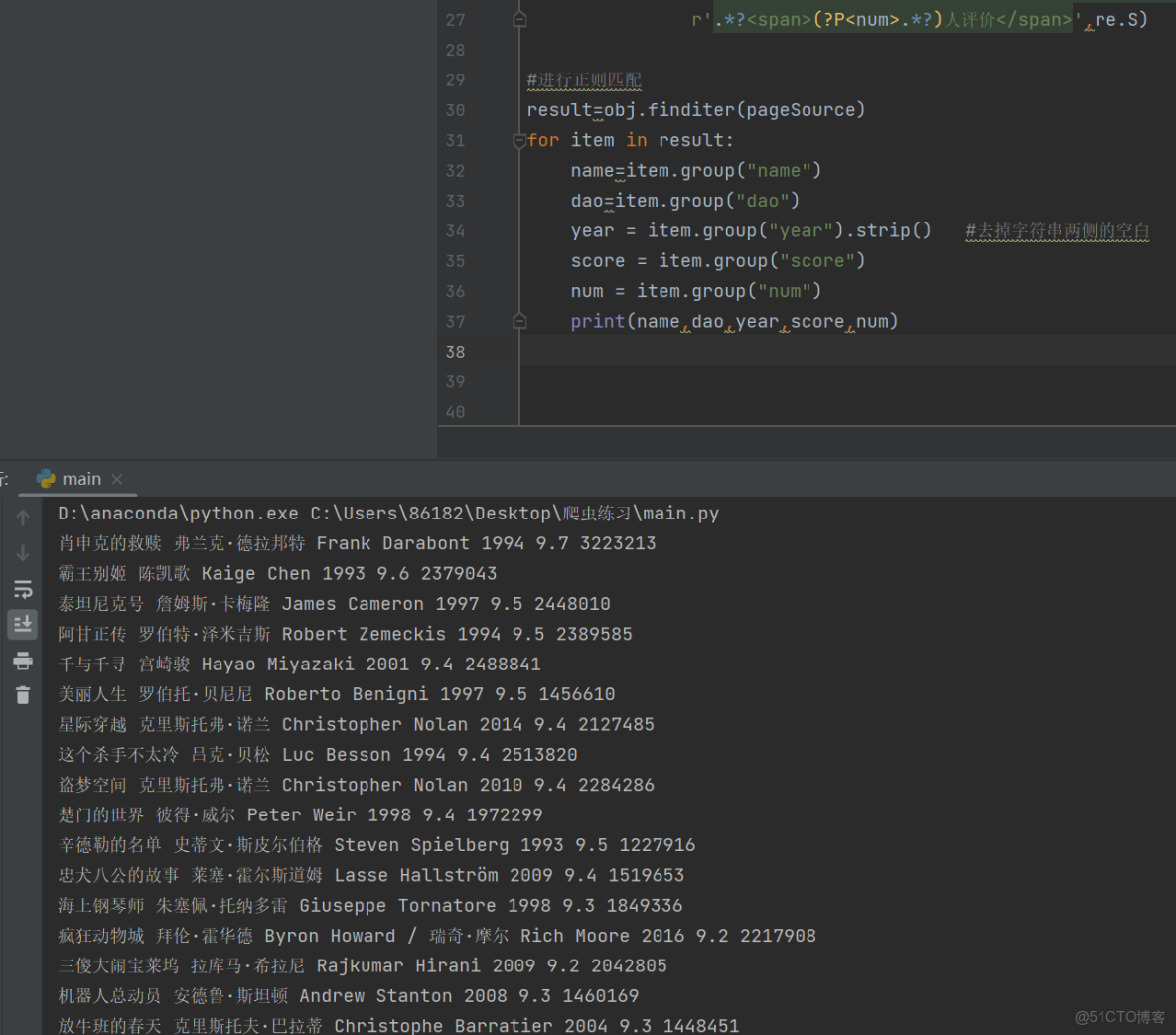
for item in result:
name=item.group("name")
dao=item.group("dao")
year = item.group("year").strip() #去掉字符串兩側的空白
score = item.group("score")
num = item.group("num")
print(name,dao,year,score,num)得到了結果:
3.4 保存文件
接下來保存為文件:
f=open("top250.csv",mode="w",encoding='utf-8')導出數據:
f.write(f"{name}{dao}{year}{score}{num}\n")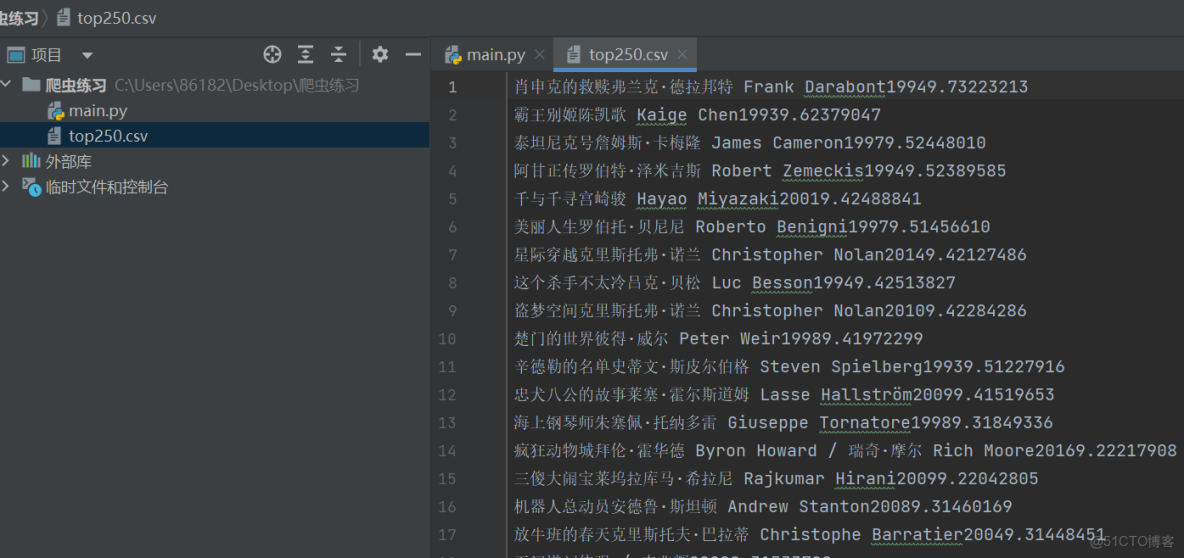
爬取一頁的完整代碼:
# 思路:
#
# 1.拿到頁面源代碼
#
# 2.編寫正則,提取頁面數據
#
# 3.保存數據
import requests
import re
f=open("top250.csv",mode="w",encoding='utf-8')
url="https://movie.douban.com/top250"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"
}
resp=requests.get(url,headers=headers)
resp.encoding="utf-8" #解決亂碼問題
pageSource=resp.text
#編寫正則表達式
obj=re.compile(r'
.*?(?P.*?).*?
'
r'.*?
.*?導演: (?P.*?) '
r'.*?
(?P.*?) .*?(?P.*?)'
r'.*?(?P.*?)人評價',re.S)
#進行正則匹配
result=obj.finditer(pageSource)
for item in result:
name=item.group("name")
dao=item.group("dao")
year = item.group("year").strip() #去掉字符串兩側的空白
score = item.group("score")
num = item.group("num")
f.write(f"{name}{dao}{year}{score}{num}\n")
print(name,dao,year,score,num)
f.close()
resp.close()
print("豆瓣Top250提取完畢")這時候思考,現在的代碼只能爬取一頁的25條信息,如何爬取全部250條?
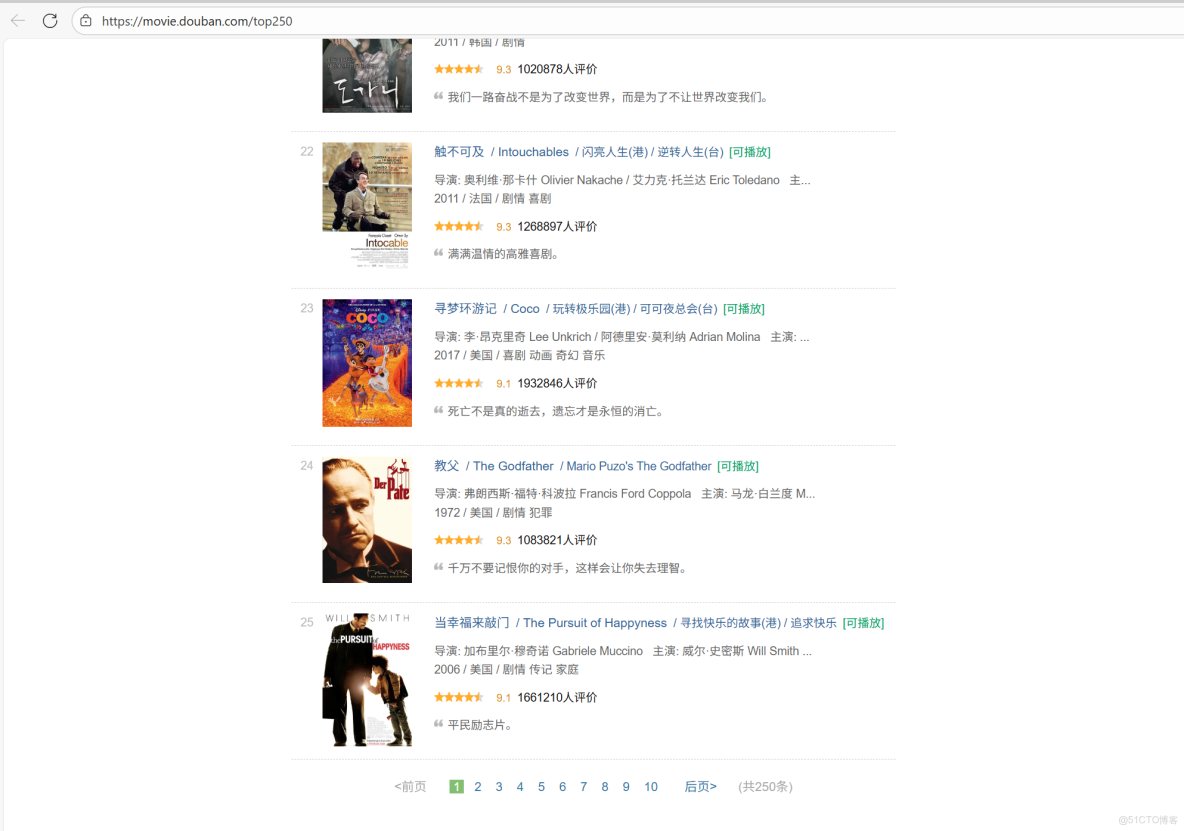
4.翻頁爬取
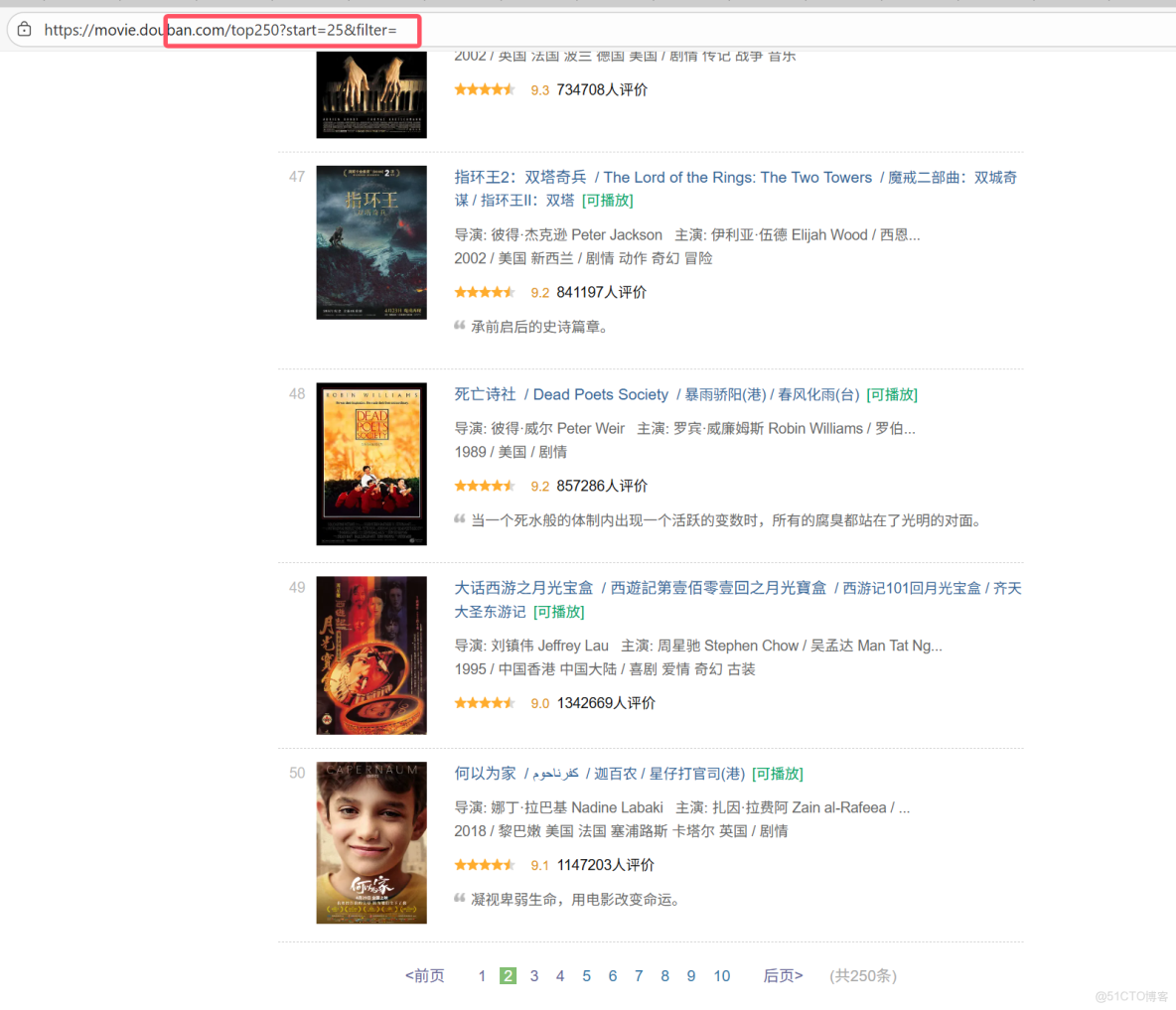
由於發現每跳轉一頁頁面url的start都會增加25,因此得出可以用while循環來爬取全部數據
start=(頁數-1)*25
四、完整代碼與注意點
1.完整代碼
# 思路:
#
# 1.拿到頁面源代碼
#
# 2.編寫正則,提取頁面數據
#
# 3.保存數據
import requests
import re
f=open("top250.csv",mode="w",encoding='utf-8')
#start=(頁數-1)*25
page=1
while page<=10:
url=f"https://movie.douban.com/top250?start={(page - 1) * 25}&filter="
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"
}
resp=requests.get(url,headers=headers)
resp.encoding="utf-8" #解決亂碼問題
pageSource=resp.text
#編寫正則表達式
obj=re.compile(r'
.*?(?P.*?).*?
'
r'.*?
.*?導演: (?P.*?) '
r'.*?
(?P.*?) .*?(?P.*?)'
r'.*?(?P.*?)人評價',re.S)
#進行正則匹配
result=obj.finditer(pageSource)
for item in result:
name=item.group("name")
dao=item.group("dao")
year = item.group("year").strip() #去掉字符串兩側的空白
score = item.group("score")
num = item.group("num")
f.write(f"{name}{dao}{year}{score}{num}\n")
print(name,dao,year,score,num)
print(f"第{page}頁爬取完成")
page = page + 1
f.close()
resp.close()
print("豆瓣Top250提取完畢")2.注意點
解釋一下
url=f"https://movie.douban.com/top250?start={(page - 1) * 25}&filter="這裏的f必須要加
不加 f 的情況:
url="https://movie.douban.com/top250?start={(page - 1) * 25}&filter="實際URL變成了:
https://movie.douban.com/top250?start={(page - 1) * 25}&filter=注意:{(page - 1) * 25} 被當作普通字符串,而不是要計算的表達式。無論 page 是多少,URL 始終是這個固定的字符串。
豆瓣服務器收到這個請求時,看到 start={(page - 1) * 25},它不知道這是什麼,通常會將其視為 start=0 或者忽略這個參數,所以每次都返回第一頁的數據。
五、結果展示
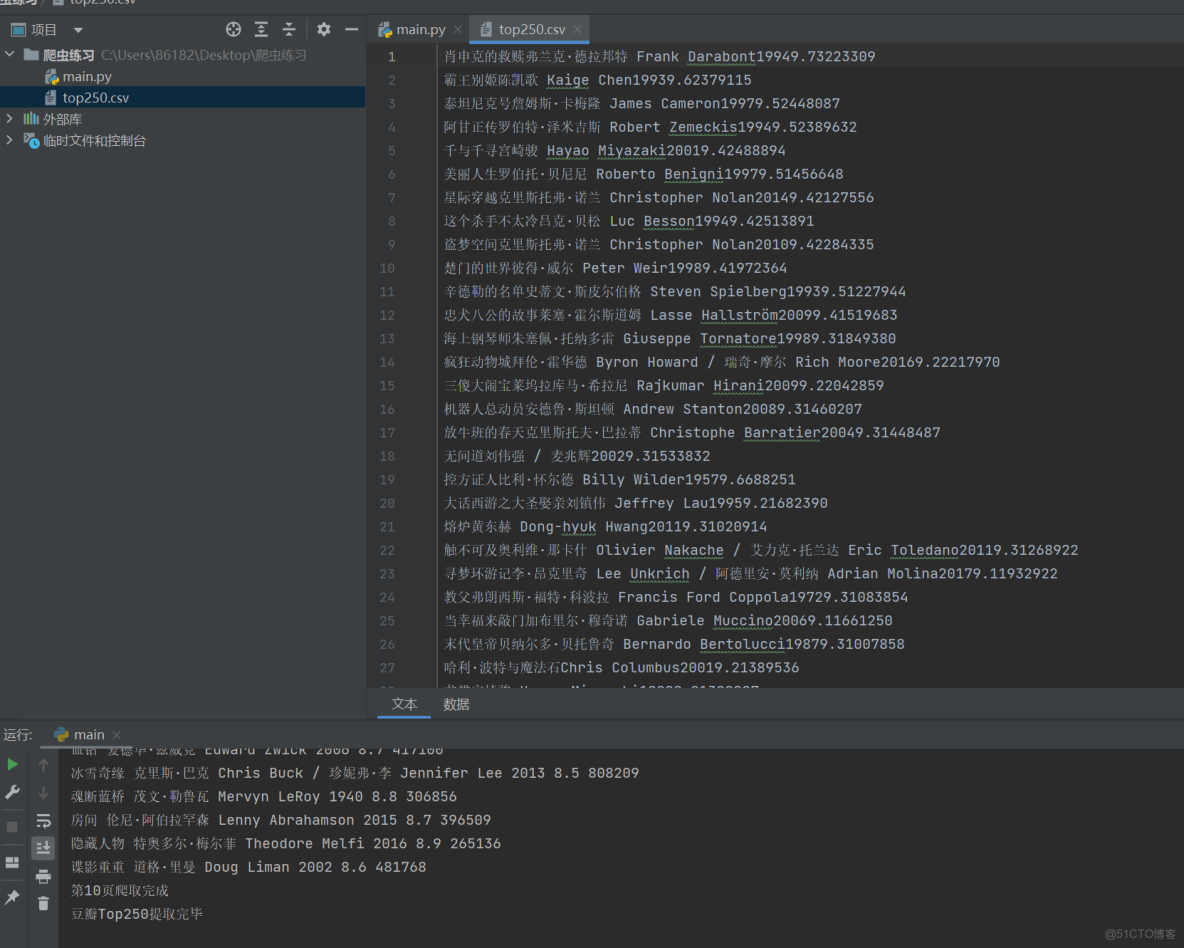
成功爬取250條數據~
■ 我是蔣星熠Jaxonic!如果這篇文章在你的技術成長路上留下了印記
■ 【關注】與我一起探索技術的無限可能,見證每一次突破
■ 【點贊】為優質技術內容點亮明燈,傳遞知識的力量
■ 【收藏】將精華內容珍藏,隨時回顧技術要點
■ 【評論】分享你的獨特見解,讓思維碰撞出智慧火花
■ 【投票】用你的選擇為技術社區貢獻一份力量
■ 技術路漫漫,讓我們攜手前行,在代碼的世界裏摘取屬於程序員的那片星辰大海!