

編輯導讀:騰訊音樂娛樂集團作為中國在線音樂娛樂服務的領航者,旗下擁有 QQ 音樂、酷狗音樂、酷我音樂和全民 K 歌等眾多國民級移動音頻應用。每天,這些產品都會產生海量的用户行為和業務數據,為精準推薦、用户增長和商業化等核心業務提供着源源不斷的數據驅動力。在這一切背後,一個強大、穩定且高效的 Kafka 流系統是支撐其業務持續創新和發展的關鍵。 然而,隨着業務的飛速發展,傳統的自建 Kafka 集羣在運維複雜度和成本控制方面逐漸暴露出其侷限性。為了應對日益增長的數據洪流和對成本效益的極致追求,騰訊音樂運維團隊毅然開啓了對下一代 Kafka 解決方案的探索與實踐。
最終,他們選擇了基於雲原生架構的 AutoMQ。通過引入這一創新的解決方案,騰訊音樂不僅成功將成本降低了超過 50%,更通過其獨特的分區秒級遷移能力,極大地提升了集羣的擴縮容效率,顯著降低了原有 Kafka 的運維複雜度和負擔。本次技術升級,是繼其在數據倉庫領域成功實踐存算分離之後,在數據流處理領域的又一次重大突破。
本文將深入解讀騰訊音樂娛樂集團是如何利用 AutoMQ 的雲原生優勢,破解傳統 Kafka 的運維難題和成本瓶頸,並最終實現成本與效率雙贏的。希望他們在此過程中積累的寶貴經驗與最佳實踐,能為正在面臨相似挑戰的您提供有價值的參考和指導!
作者: 騰訊音樂 高級運維開發工程師 高盛遠
背景介紹
騰訊音樂娛樂集團是中國在線音樂娛樂服務開拓者,提供在線音樂和以音樂為核心的社交娛樂兩大服務。騰訊音樂娛樂在中國有着廣泛的用户基礎,擁有目前國內市場知名的移動音頻產品:QQ 音樂、酷狗音樂、酷我音樂、全民 K 歌、懶人聽書等產品。
技術架構
對於騰訊音樂這樣擁有海量用户的平台而言,高效的數據流動、處理與分析是發揮數據價值、支持業務飛速發展的基石。在整個數據體系中,Kafka 作為核心的數據基礎設施,扮演着至關重要的角色。它不僅是連接數據生產和消費的管道,更在可觀測體系、數據平台等建設中承擔着上下游解耦以及配合其他組件簡化流程的關鍵作用。Kafka 的引入,使得數據源和數據應用可以獨立地演進,無需關心對方的實現細節。同時,它支持業務方按需實時消費數據,靈活處理各類旁路處理邏輯,這對於支撐騰訊音樂多元化的業務場景和高速發展至關重要。
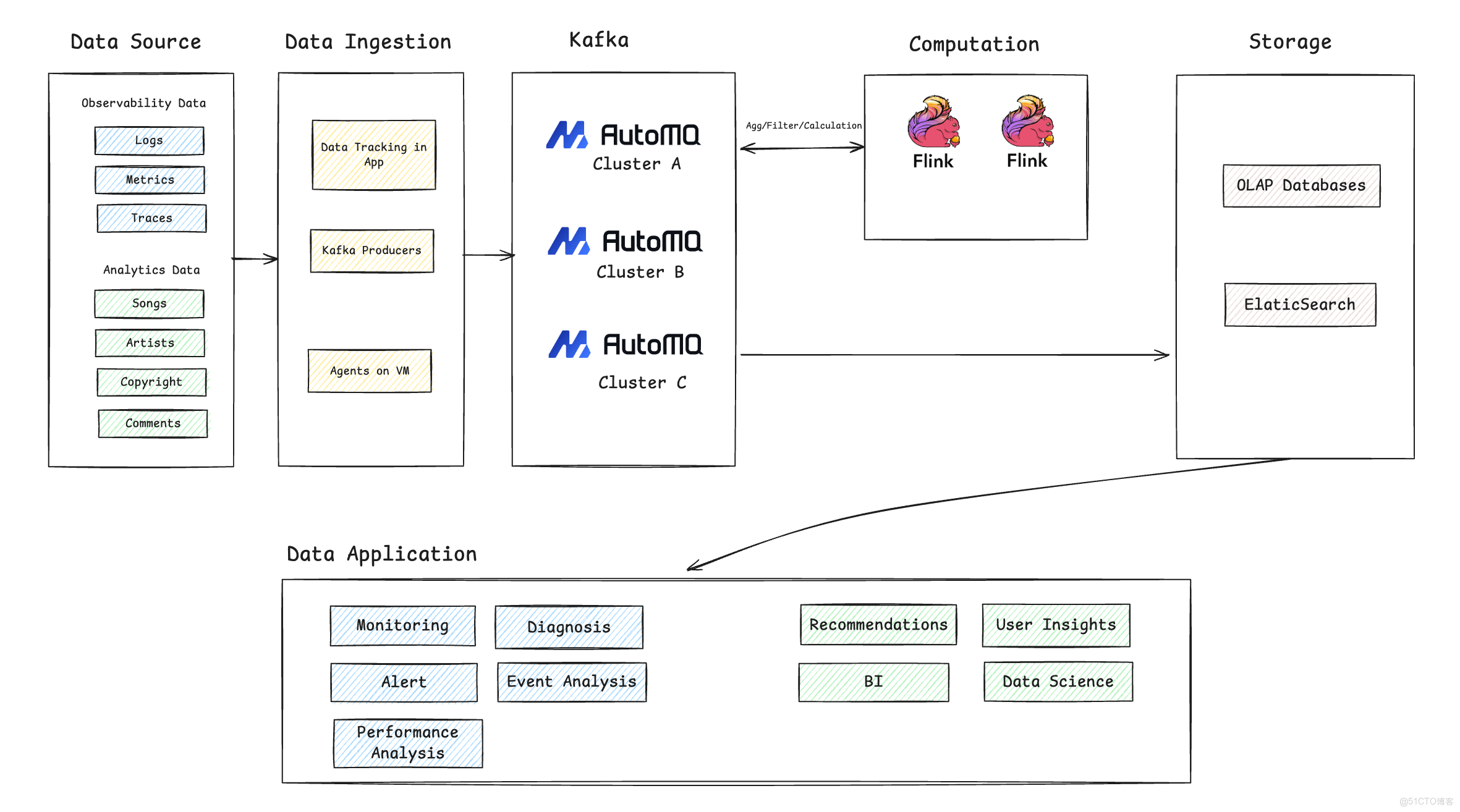
下圖清晰地展示了騰訊音樂基於 AutoMQ 構建的現代化實時數據流處理架構。整個數據流從數據源採集開始,經過數據接入、Kafka 流系統、實時計算、數據存儲,最終服務於上層的各類數據應用,具體流程如下:
- 數據源 (Data Source):數據源主要分為兩大類。第一類是可觀測性數據,包括服務運行產生的海量日誌、關鍵指標(Metrics)和 Trace 信息;第二類是分析數據,涵蓋了歌曲、藝術家、版權等業務元數據,以及用户的播放、評論等行為數據。
- 數據接入 (Data Ingestion):為了實現海量數據源數據的統一、高效接入,騰訊音樂內部的“數據通道”平台,作為所有業務方數據接入的統一入口。該平台底層封裝了業務埋點、Kafka Producers 等多種上報方式。其核心價值在於,在數據進入 AutoMQ 之前,平台會進行一系列的預處理,包括地域與業務區分、字段過濾、安全鑑權和智能分發。這一流程不僅確保了只有合規、準確的數據才能進入核心系統,也極大地提升了數據接入的效率和治理水平。不同類型的數據通過相應的組件進行採集和上報。例如,應用程序內部通過集成的 SDK 進行埋點追蹤,業務服務通過標準的 Kafka 生產者(Kafka Producers)上報數據,而部署在虛擬機上的 Agents 則負責採集各類系統的日誌和指標。
- 流系統 (Kafka):所有接入的數據統一匯入作為核心數據總線的 AutoMQ 集羣。在這裏,AutoMQ 承接了來自不同業務線的數據洪峯,為下游的實時計算和數據存儲提供高吞吐、低延遲的可靠數據流服務。通過部署多個 AutoMQ 集羣(如圖中的 Cluster A, B, C),可以實現業務隔離和精細化管理。
- 實時計算 (Computation):在數據寫入最終存儲之前,通常會經過一個可選的實時計算層。騰訊音樂使用 Flink 作為主流的計算引擎,對 Kafka 中的原始數據流進行實時的聚合、過濾和複雜計算。這一步是實現實時監控報警、數據清洗和預處理的關鍵。例如,Flink 作業會消費 AutoMQ 集羣 A 的數據,經過處理後再寫回,供其他服務使用。
- 數據存儲 (Storage):經過實時計算處理後,數據被寫入不同的存儲系統以滿足不同的查詢需求。一部分數據會流入 OLAP 數據庫,用於後續的交互式分析和 BI 報表;另一部分數據,尤其是日誌和追蹤數據,則會被寫入 Elasticsearch,以支持快速的搜索和問題定位。
- 數據應用 (Data Application):在架構的最上層,是直接面向業務和技術團隊的各類數據應用。這些應用大致可分為兩類:
- 可觀測性應用:基於實時數據流,構建強大的實時監控與告警、智能故障診斷、事件和性能分析,保障業務的穩定運行。
- 數據分析應用:利用處理後的數據,驅動上層業務決策,包括個性化推薦、用户洞察、商業智能(BI)分析和數據科學建模等,實現數據驅動的精細化運營。
Kafka 挑戰
隨着騰訊音樂旗下 QQ 音樂、酷狗音樂等多款應用的高速發展,數據規模呈指數級增長,作為數據流中樞的 Kafka 集羣也面臨着日益嚴峻的挑戰。這些挑戰主要集中在成本和運維兩個方面。
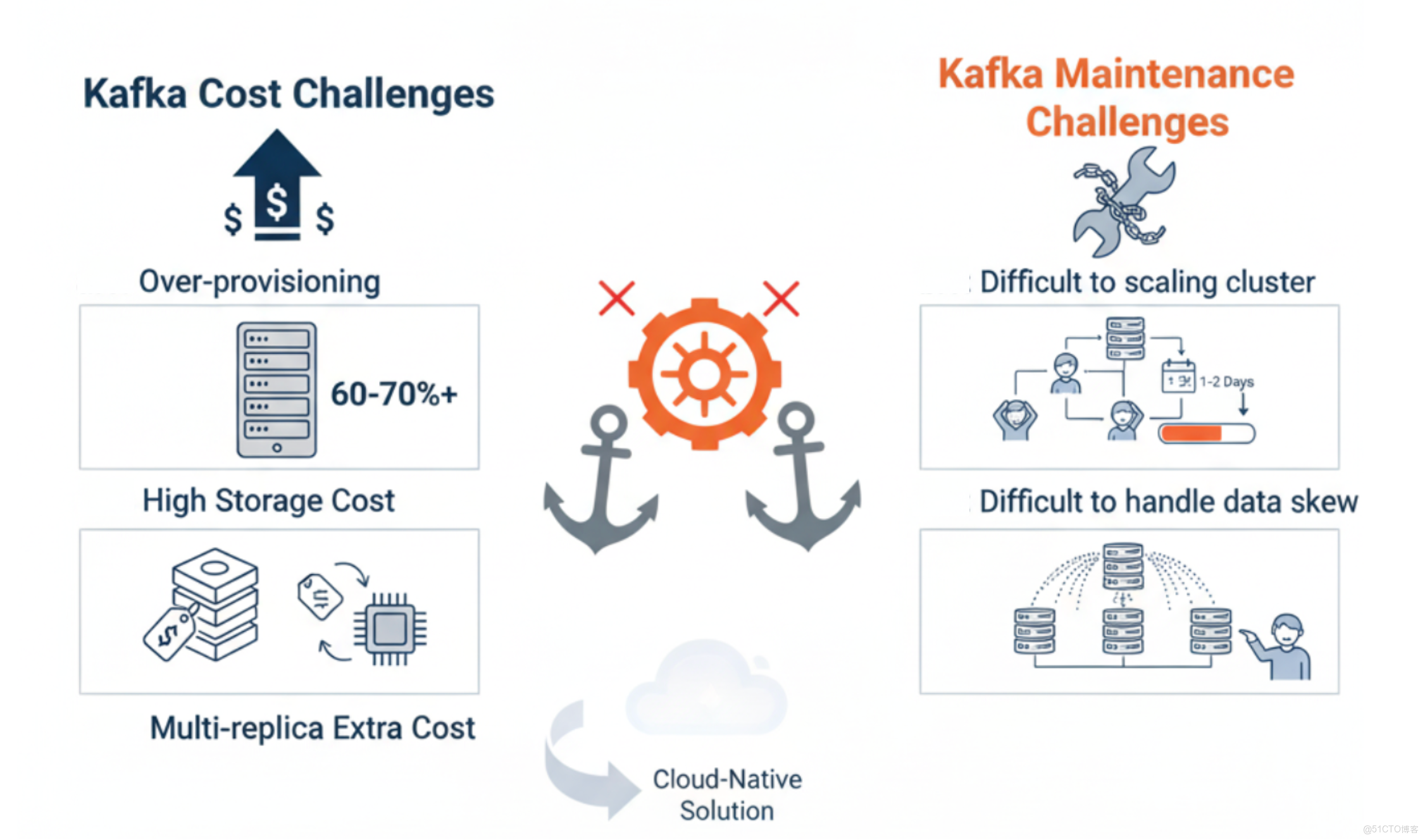
日益嚴峻的成本壓力
在騰訊音樂的業務體量下,Kafka 的成本問題變得尤為突出,主要體現在以下幾個方面:
- 資源預留成本高昂:由於 Kafka 存算一體的架構限制,集羣的計算和存儲資源必須同步擴展。為了從容應對業務流量的波峯,生產環境的資源預留水位通常需要保持在 30%~40% 甚至更高。這意味着有大量的服務器資源在大部分時間處於閒置狀態,造成了巨大的浪費。
- 存儲成本居高不下:為了保證數據的 TTL 時長和高併發下的讀寫性能,Kafka 的 Broker 節點通常需要配置多塊大容量的高性能本地磁盤。昂貴的存儲介質和大量的資源預留,共同推高了 Kafka 集羣的總體擁有成本(TCO)。
- 多副本機制帶來額外開銷:Kafka 內置的多副本機制雖然保障了數據的高可靠,但在進行分區數據同步時,會對 Broker 節點的 CPU 產生額外的開銷。這不僅增加了資源消耗,也對機型的規格提出了更高的要求,間接導致了硬件成本的上升。
運維成本高
在傳統 Kafka 架構下,運維團隊面臨着巨大挑戰,尤其是在集羣的彈性伸縮和日常維護方面。
- 擴縮容操作“傷筋動骨”:隨着業務發展,集羣擴縮容是家常便飯。然而,Kafka 的擴縮容流程卻較為繁瑣和漫長。業務方首先需要提交擴容申請並等待審核,業務運維團隊會等到業務低峯期才執行操作,以避免影響線上服務。擴縮容過程中最耗時的是 Kafka 的分區數據搬遷,它會產生較大的網絡和磁盤 I/O,同時耗費大量時間。並且團隊成員還需要投入大量精力,去驗證流量是否被正確、均衡地引導至新的 Broker 節點。整個擴縮容流程走完,通常需要 1 天左右的時間,並且依賴人工介入,整個過程是耗時且有風險的。
- 數據熱點處理棘手:除了計劃內的擴容,當突發的數據熱點出現時,運維團隊也需要人工介入,通過調整生產端的寫入策略來打散流量,以避免單個 Broker 或分區過載。這種手動干預的方式不僅響應不及時,而且操作複雜,給系統的穩定性帶來了潛在風險。
這些長期存在的成本與運維難題,給負責 Kafka 運維的團隊帶來了沉重的負擔,也成為了制約數據基礎設施進一步發展的瓶頸。因此,尋找一個更具彈性、更低成本、運維更友好的下一代 Kafka 解決方案,被提上了議程。
為什麼選擇 AutoMQ
在評估下一代 Kafka 解決方案時,我們團隊有幾個非常明確的目標。經過深入的技術調研和對比,我們認為 AutoMQ 是最能滿足我們當前和未來需求的方案。
- 解決運維瓶頸,實現快速彈性:我們面臨最大的痛點是傳統 Kafka 擴縮容的低效和高風險。AutoMQ 存算分離的架構,將 Broker 變成了無狀態節點,數據則存放在對象存儲上。這對我們來説,最直接的好處就是分區遷移可以按秒級完成,集羣擴容不再需要漫長的數據搬遷,整個過程可以自動化,從過去耗時一兩天的人工操作,縮短到了幾分鐘,極大地提升了我們的運維效率。
- 在保證性能穩定的前提下,實現架構性降本:成本是另一個核心考量。AutoMQ 的架構讓我們能夠獨立擴展計算和存儲資源,這意味着我們不再需要為應對流量峯值而預留大量昂貴的計算實例。同時,將數據從本地磁盤轉移到成本低得多的對象存儲,直接降低了存儲開銷。這種架構上的改變,是從根本上解決了成本問題,而不是小修小補。
- 真正適配雲原生(Kubernetes Native):我們的基礎設施正在全面擁抱 Kubernetes。傳統 Kafka 的有狀態特性,使其難以充分利用 Kubernetes 在資源調度和故障恢復上的優勢。AutoMQ 的無狀態 Broker 則能與 Kubernetes 完美協同,像普通應用一樣被自由調度,這為我們未來將整個 Kafka 服務遷移至 K8s 鋪平了道路,有助於最大化資源利用率。
- 原生支持 Iceberg,簡化數據入湖:我們未來的數據平台規劃之一是構建基於 Apache Iceberg 的流式數據湖。AutoMQ 在這方面的前瞻性設計是一個重要加分項。它提供的 Table Topic 功能可以直接將 Topic 數據流式寫入為 Iceberg 表格式,並存入對象存儲。這意味着我們未來可以省去一個獨立的 Flink 或 Spark 作業來進行數據轉換和入湖,從而顯著簡化數據棧的架構和維護成本。
- 平滑無感的遷移路徑:替換核心基礎設施,最大的風險在於遷移過程。AutoMQ 提供了 100% 的 Kafka 協議兼容性,這一點至關重要。這意味着我們現有的所有生產者、消費者程序代碼都無需任何改動。同時,我們已經構建多年的監控、運維和安全等配套設施也能無縫集成。這為我們提供了一個低風險、低成本的遷移方案,是項目能夠成功落地的基本保障。

評估和遷移過程
對於一項如此核心的基礎設施升級,一個嚴謹且分階段的評估與遷移計劃是必不可少的。我們的目標是確保 AutoMQ 在真實的生產負載下,其穩定性、性能和兼容性都達到甚至超過我們的預期。整個過程可以分為兩個階段:負載驗證和生產遷移。
負載驗證階段
我們設計了兩種典型的業務場景來對 AutoMQ 進行壓力測試,以覆蓋我們主要的負載模型:
- 2025 年 6 月 - 大流量場景驗證:我們首先上線了一個承載高數據吞吐量、但 QPS(每秒請求數)相對不高的集羣。這個測試的目的是驗證 AutoMQ 在處理海量數據持續寫入和讀取場景下的性能和穩定性,特別是在網絡 I/O 和對象存儲交互方面的表現。
- 2025 年 7 月 - 高 QPS 場景驗證:隨後,我們部署了第二個集羣,用於承載一個高 QPS、但單條消息流量較小的業務。這個場景重點考驗的是 AutoMQ 在處理高頻元數據請求、客户端連接管理以及小 I/O 聚合能力上的性能極限。
在這兩個月的測試中,我們通過構造多組不同的測試負載,對 AutoMQ 進行了全面的評估。結果表明,AutoMQ 在各種壓力場景下都展現出了非常好的穩定性,其吞吐量、延遲等關鍵性能指標完全符合我們生產環境的要求。這給了我們充足的信心,正式啓動生產環境的遷移工作。
生產遷移階段
從 2025 年 8 月開始,我們正式將生產環境的業務流量遷移至 AutoMQ。得益於 AutoMQ 對 Apache Kafka 協議 100% 的兼容性,整個遷移過程異常絲滑,對業務方完全透明,也無需我們進行額外的開發適配。
我們的遷移遵循了以下標準的三步流程,以確保數據的零丟失和服務的不中斷:
- 切換生產者 (Producer):我們首先修改生產者的客户端配置,將它們的接入點地址指向新的 AutoMQ 集羣。這個過程通過滾動更新(rolling update)的方式進行,線上流量被平滑地切換過來,新的數據開始源源不斷地寫入 AutoMQ。
- 排空舊集羣數據:在生產者完全切換後,舊的 Kafka 集羣不再接收新的數據。我們會讓消費者繼續運行在舊集羣上,直到它們消費完所有堆積的歷史數據。
- 切換消費者 (Consumer):確認舊集羣數據已被消費完畢後,我們同樣以滾動更新的方式,修改消費者的接入點地址,使其指向新的 AutoMQ 集羣。消費者會配置為從新集羣中最早的可用位點(Offset)開始消費,從而無縫銜接,保證了數據處理的連續性。
上線情況與效果
經過平滑的遷移,AutoMQ 目前已經在我們內部穩定運行,並承接了核心的生產流量。截至目前,我們總計上線了 6 個 AutoMQ 集羣,整體峯值寫入吞吐量達到 1.6 GiB/s,峯值 QPS 約為 480K。
為了更直觀地展示其運行表現,下圖是我們其中一個較大集羣的生產集羣監控概覽:
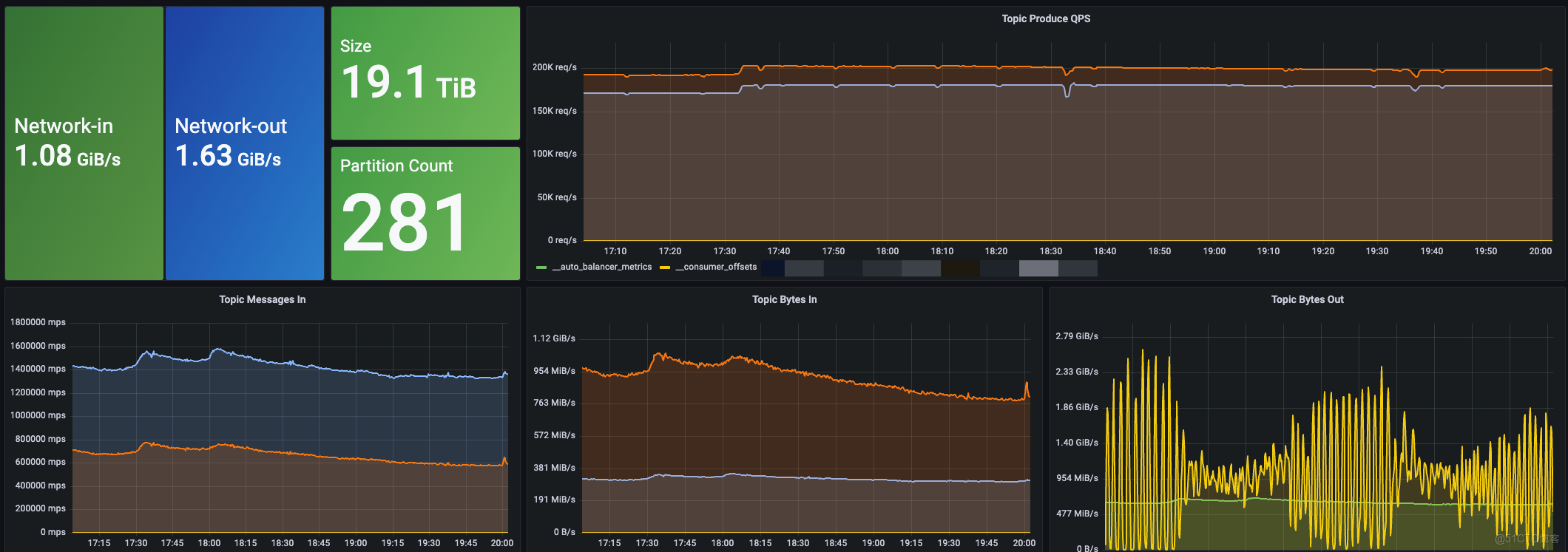
遷移到 AutoMQ 後,我們獲得了非常顯著的收益,完美解決了之前在傳統 Kafka 上遇到的核心痛點。
- 成本大幅度降低:最直接、最顯著的收益來自於成本的優化。AutoMQ 存算分離的創新架構,從根本上解決了傳統 Kafka 因資源捆綁而導致的成本問題。我們不再需要為應對流量高峯而預留大量的計算資源,同時通過將數據持久化到對象存儲,也極大地降低了存儲開銷。綜合計算和存儲兩方面的節省,**騰訊音樂 Kafka 集羣成本平均降低超過了 50%**。
- 獲得“秒級”的極速擴縮容能力:過去困擾我們運維團隊的擴容難題,在 AutoMQ 上徹底成為了過去式。由於擴容新的 Broker 節點不再需要進行耗時的數據搬遷,整個過程變得異常迅速。憑藉 AutoMQ 分區的秒級遷移能力以及其內置的 Self-Balancing 自動流量均衡機制,我們現在可以在數十秒內,平滑地為集羣擴展出 1 GiB/s 的吞吐容量。這種極致的彈性伸縮能力,意味着我們可以從容應對任何突發的業務流量增長,為騰訊音樂未來的業務發展提供了堅實而靈活的基礎設施保障。

未來展望
回顧這次技術升級之旅,AutoMQ 在騰訊音樂生產環境中的表現令人印象深刻。無論是在高負載下的穩定性、優秀的性能指標,還是在降本增效和簡化運維方面取得的實質性成果,都完全符合甚至超出了我們運維團隊的預期。這次成功的實踐,驗證了 AutoMQ 這種雲原生架構在 Kafka 流領域的巨大價值。
基於當前的成功經驗,我們制定了清晰的未來演進路線圖,按優先級逐步推進:
- 全面推進存量遷移:我們將加速推進剩餘 Kafka 集羣的遷移工作。計劃將所有服務於全量可觀測和多維分析業務的 Kafka 集羣全部遷移至 AutoMQ,以最大化地釋放成本紅利並統一運維體系。
- 落地流式數據入湖:在數據架構演進方面,我們將着手落地 AutoMQ 的 Table Topic 功能。充分利用其對 Iceberg 的原生支持,構建更加簡潔、高效、實時的流式數據入湖鏈路,為上層的數據分析業務提供更強有力的支撐。
- AutoMQ 組件標準化與推廣:我們計劃將 AutoMQ 打造成騰訊音樂內部標準化的基礎設施組件,並積極將其推廣應用到更多樣化的業務場景中,讓更多的業務線受益於新架構帶來的極致彈性和低成本優勢。
- 邁向完全的 Kubernetes 雲原生:最後,依託 AutoMQ 天然無狀態的雲原生特性,我們將啓動將 Kafka 服務整體搬遷至 Kubernetes 的探索與實踐。這將有助於我們進一步提升資源管理的自動化水平和整體利用率,推動騰訊音樂的數據基礎設施向着完全雲原生的方向邁進。