
一、發軔之始
在工作和生活中,我們可能經常會遇到一些場景,我們在搜索引擎中輸入問題尋求解決方案,返回的卻是大量重複的、基礎性的、甚至是商業推廣的內容。無奈的反覆修正我們的檢索內容,就是找不到答案,這確實是一大困擾,由於算法的侷限性和商業干擾,導致搜索引擎算法傾向於流行度而非質量,商業利益常常凌駕於信息價值之上。我們得到的往往是最多人點擊的,而不是最正確的。
如今隨着AI的大爆發,我們也在設計AI產品,我們如何突破這種信息繭房,讓我們設計的系統反饋的答案更加的精準化,首先我們已經瞭解到RAG的概念和優勢,現在我們繼續為RAG插上翅膀,集成結果的重排序Rerank模型,提升產品用户體驗和系統信任度,增強搜索問題和結果之間的深層語義關係,從海量信息中精準篩選出最適合的內容,並以易於理解的方式呈現給用户。

二、 什麼是Rerank模型
重排序(Rerank) 是在檢索增強生成(RAG)系統中,對初步檢索到的文檔結果進行精細化重新排序的關鍵技術環節。它位於初始檢索和最終生成之間,充當"質檢員"和"精算師"的角色,對初步檢索到的大量候選文檔(例如100-1000個)進行重新評分和排序,將最相關、最準確的少量文檔(例如5-10個)排在頂部,然後將其提供給LLM生成最終答案。確保傳遞給大語言模型(LLM)的上下文材料是最高質量的。主要用於優化初步檢索結果的排序,提高最終輸出的相關性或準確性。
可以通俗的將Rerank理解為一位專業的“質檢員”或“決賽裁判”:
- 初始檢索(如FAISS):像“海選”,快速從數百萬選手中選出100位可能符合條件的。
- Rerank模型:像“專家評審”,仔細面試這100位選手,從中挑出最頂尖的5位。
- LLM:像“終極BOSS”,基於最頂尖的5位選手的信息,做出最終決策(生成答案)。
三、為什麼需要Rerank
初始的向量檢索器,如基於Embedding的FAISS,雖然速度快,但存在固有侷限性:
- 語義相似度 ≠ 查詢-文檔相關性:Embedding模型學習的是廣泛的語義相似性,但“相關”是一個更具體、更任務導向的概念。一個文檔可能與查詢在語義上很接近,但可能並未直接回答查詢的問題。
- “詞彙不匹配”問題:儘管比關鍵詞搜索好,但Embedding模型有時仍然難以完美解決表述差異的問題。
- 精度與召回率的權衡:為了提高召回率(Recall),我們通常會初始檢索大量文檔(K值較大),但這其中必然包含許多不精確或冗餘的文檔,直接交給LLM會引入噪聲,增加成本並可能導致錯誤回答。
Rerank模型通過執行更深入的“查詢-文檔”對交叉分析,專門針對“相關性”進行優化,完美解決了上述問題。
1. Rerank模型和Embedding模型比較
|
特性 |
嵌入(Embedding)模型 |
重排序(Rerank)模型 |
|
輸入 |
單段文本 |
(Query, Document) 對 |
|
輸出 |
一個高維向量 |
一個相關性分數(標量) |
|
計算方式 |
對稱或不對稱語義搜索 |
交叉編碼(Cross-Encoder),深度交互 |
|
速度 |
非常快,適合大規模初步檢索 |
相對慢,適合對少量候選精排 |
|
精度 |
良好,但不夠精確 |
非常高,是相關性判斷的專家 |
|
典型用途 |
從海量數據中快速召回Top K個候選 |
對Top K個候選進行精細重排序 |
2. 核心工作原理:交叉編碼
與生成嵌入向度的雙編碼器(Bi-Encoder) 不同,Rerank模型通常是交叉編碼器(Cross-Encoder)。
- Bi-Encoder(雙塔模型):查詢和文檔分別通過編碼器(通常是同一個)獨立地轉換為向量,然後計算向量間的相似度(如餘弦相似度)。優勢是快,因為文檔可以預先編碼存儲。
- Cross-Encoder(交叉編碼):將查詢和文檔拼接在一起,作為一個完整的序列輸入到模型中。模型(如BERT)的注意力機制(Attention)能夠同時在查詢和文檔的所有詞元之間進行深度的、精細的交互,從而直接輸出一個相關性的分數。優勢是精度極高,因為它能真正“理解”Query和Document之間的細微關係。
3. Rerank的優勢
- 顯著提升答案質量:提供給LLM的上下文質量更高,直接減少幻覺、提高答案准確性。
- 降低Token消耗:只需傳遞更少、更精煉的文檔給LLM,節省了輸入Token的成本。
- 增強系統魯棒性:即使初始檢索不夠準確,Rerank也能在一定程度上糾正錯誤。
四、Rerank的流程節點和模型選擇
1. Rerank在RAG流程中的位置
一個集成Rerank的完整RAG流程如下:
- 輸入:用户查詢(Query)。
- 初步檢索(Recall):使用向量搜索引擎(如FAISS)從知識庫中快速召回Top K個相關文檔(K較大,例如100)。
- 重排序(Rerank):將用户查詢和初步召回的每一個文檔依次組成(Query, Document)對,輸入到Rerank模型中獲取相關性分數。
- 篩選與排序:根據Rerank分數對所有候選文檔進行降序排序,並選取Top N個分數最高的文檔(N較小,例如5)。
- 生成(Generation):將用户查詢和精排後的Top N個文檔一起構成提示(Prompt),輸入給LLM生成最終答案。
- 輸出:LLM生成的、基於最相關上下文的答案。
2. Rerank模型選擇
BGE-Rerank和Cohere Rerank是兩種廣泛使用的重排序模型,它們在檢索增強生成(RAG)系統、搜索引擎優化和問答系統中表現優異。
2.1 BGE-Rerank模型
- bge-reranker-base / bge-reranker-large:北京智源AI研究院開源的優秀中英雙語Rerank模型,非常流行,後者在精度上更優。
- 基於Transformer的Cross-Encoder結構,直接計算查詢(Query)與文檔(Document)的交互相關性得分,可本地部署。
- BAAI/bge-reranker-v2-m3:智源最新的多語言、多功能重排序模型。
2.2 Cohere Rerank模型
- 由Cohere公司提供的商業API服務。
- 基於專有的深度學習模型,支持多語言(如rerank-multilingual-v3.0)。
- 訓練數據:優化了語義匹配,特別適用於混合檢索(如結合BM25和向量檢索)後的結果優化。
- 使用方式:通過API調用,集成到LangChain、LlamaIndex等框架中。
- 簡單易用,適合快速集成到現有系統,在英文和多語言任務中表現優異。
更大的模型(Large)通常精度更高,但推理速度更慢。需要在精度和速度之間做出權衡。
五、集成Rerank完整流程圖
1. 完整流程圖
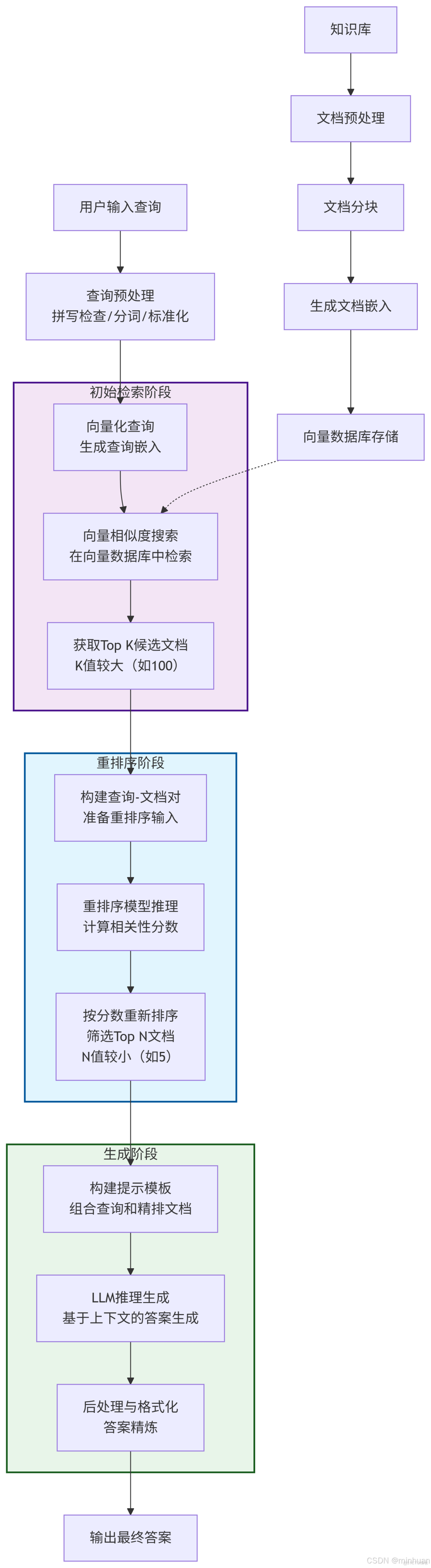
流程介紹
1. 初始檢索階段
- 用户輸入查詢:接收用户的自然語言問題
- 查詢預處理:對查詢進行清洗、標準化和分詞處理
- 向量化查詢:使用嵌入模型將查詢轉換為向量表示
- 向量相似度搜索:在向量數據庫中進行近似最近鄰搜索
- 獲取Top K候選文檔:返回相似度最高的K個文檔(K值較大,確保召回率)
2. 重排序階段 - 核心環節
- 構建查詢-文檔對:將查詢與每個候選文檔組合成(Query, Document)對
- 重排序模型推理:使用交叉編碼器模型對每個對進行深度相關性分析
- 按分數重新排序:根據模型輸出的相關性分數對文檔降序排列
- 篩選Top N文檔:選擇分數最高的N個文檔(N值較小,確保精確率)
3. 生成階段
- 構建提示模板:將精排後的文檔與查詢組合成LLM可理解的提示
- LLM推理生成:大語言模型基於提供的上下文生成答案
- 後處理與格式化:對生成的答案進行精煉、格式化和驗證
4. 知識庫預處理流程
- 文檔預處理:清洗和標準化原始文檔
- 文檔分塊:將長文檔分割成適當大小的塊
- 生成文檔嵌入:為每個文檔塊生成向量表示
- 向量數據庫存儲:將文檔向量存入向量數據庫以備檢索
2. Rerank流程圖
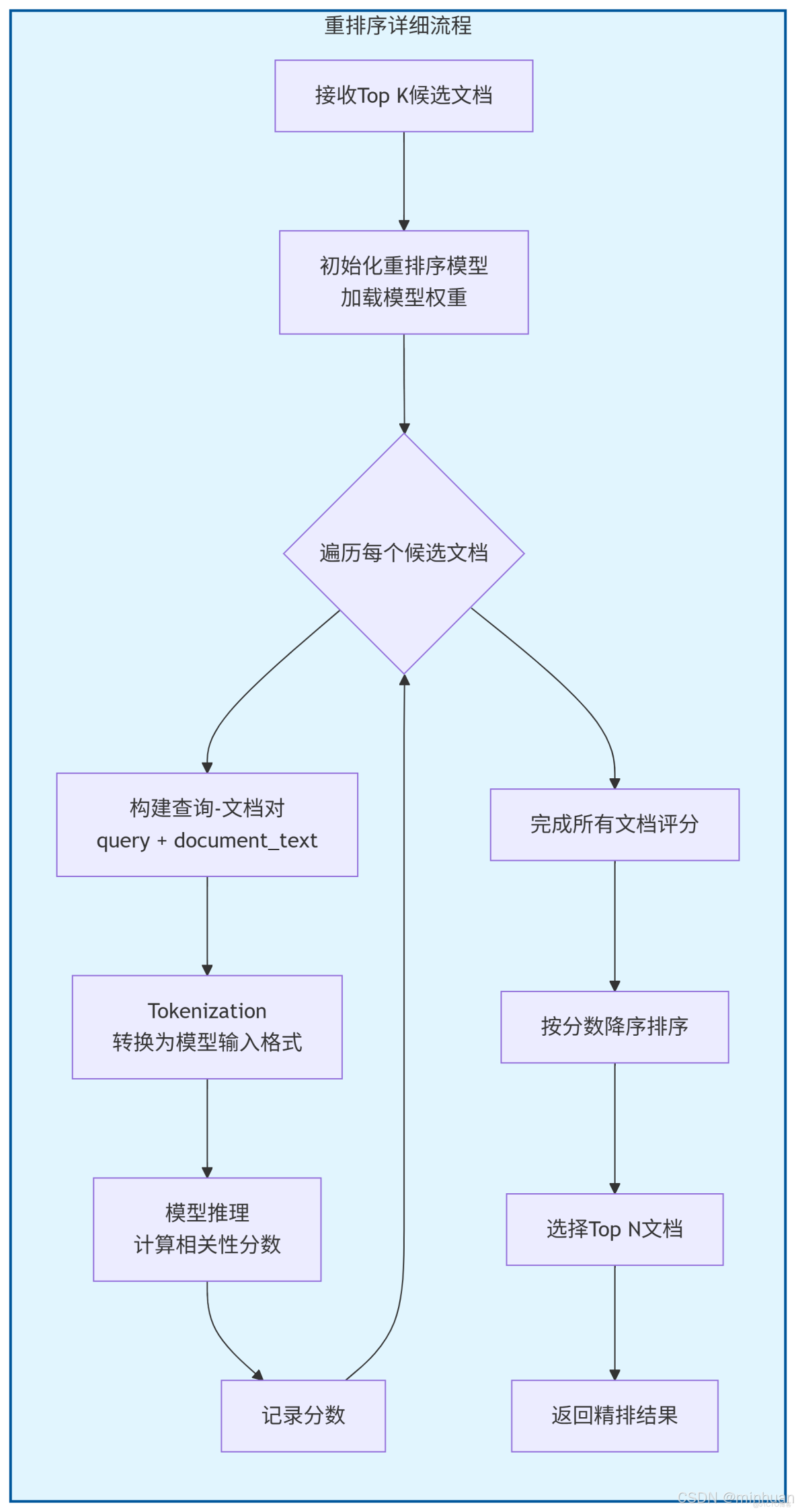
各階段輸入輸出示例
1. 初始檢索階段
輸入: "如何學習鋼琴?"
輸出:
1. 鋼琴保養指南 (相似度: 0.82)
2. 音樂理論基礎 (相似度: 0.79)
3. 鋼琴購買指南 (相似度: 0.77)
4. 鋼琴入門指法教程 (相似度: 0.75)
5. 十大鋼琴家介紹 (相似度: 0.72)
... (共100個文檔)
2. 重排序階段
輸入: 初始檢索的100個文檔 + 查詢"如何學習鋼琴?"
處理: 使用BGE-Reranker計算每個文檔與查詢的相關性分數
輸出:
1. 鋼琴入門指法教程 (相關性: 0.95)
2. 鋼琴練習曲目推薦 (相關性: 0.92)
3. 音樂理論基礎 (相關性: 0.88)
4. 鋼琴學習計劃制定 (相關性: 0.85)
5. 鋼琴師資選擇指南 (相關性: 0.82)
3. 生成階段
輸入: 精排後的5個文檔 + 查詢"如何學習鋼琴?"
輸出:
學習鋼琴應該從基礎開始,首先掌握正確的坐姿和手型,然後學習基本的指法。
推薦從《拜厄鋼琴基本教程》開始,每天堅持練習30-60分鐘。
同時建議學習基礎樂理知識,如音符、節奏和和絃等。
最好找一位有經驗的老師指導,可以幫助糾正錯誤姿勢和提供個性化建議。
六、Rerank的使用場景
推薦使用場景:
- 高精度要求:醫療、法律、金融等專業領域
- 複雜查詢:多概念、抽象或模糊的查詢
- 關鍵任務:答案准確性至關重要的應用
- 文檔質量不均:知識庫中包含大量相似或冗餘文檔
可忽略場景:
- 簡單事實查詢:"中國的首都"、"浙江的省會"
- 實時性要求極高:需要毫秒級響應的場景
- 計算資源有限:無法承擔額外推理成本
七、演示示例
示例1:蘋果公司創始人推測
1. 基礎代碼
使用 bge-reranker模型在基於FAISS的RAG流程中集成Rerank模型。
from langchain_community.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.schema import Document
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
import numpy as np
# 1. 準備示例知識庫和初始檢索
# 初始化一個嵌入模型用於初始檢索
embedding_model = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
# 假設的文檔庫
documents = [
"蘋果公司於1976年由史蒂夫·喬布斯、史蒂夫·沃茲尼亞克和羅納德·韋恩創立,最初主要生產和銷售個人電腦。",
"蘋果公司最著名的產品是iPhone智能手機,它徹底改變了移動通信行業。",
"水果蘋果是一種薔薇科蘋果屬的落葉喬木果實,營養價值高,富含維生素和纖維。",
"蘋果公司在2023年發佈了其首款混合現實頭顯設備Apple Vision Pro。",
"吃蘋果有助於促進消化和增強免疫力,是一種健康零食。",
"蒂姆·庫克是蘋果公司的現任首席執行官,於2011年接替史蒂夫·喬布斯。"
]
# 轉換為LangChain Document對象
docs = [Document(page_content=text) for text in documents]
# 構建FAISS向量庫
vectorstore = FAISS.from_documents(docs, embedding_model)
# 用户查詢
query = "蘋果公司的創始人是誰?"
# 初始檢索:使用向量庫召回Top K個文檔(這裏K=4)
initial_retrieved_docs = vectorstore.similarity_search(query, k=4)
print("=== 初始檢索結果(基於語義相似度)===")
for i, doc in enumerate(initial_retrieved_docs):
print(f"{i+1}. [相似度得分: N/A] {doc.page_content}")
# 2. 初始化Rerank模型
# 我們使用 `BAAI/bge-reranker-base`,這是一個強大的中英雙語Reranker
model_name = "BAAI/bge-reranker-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
model.eval() # 設置為評估模式
# 3. 重排序函數
def rerank_docs(query, retrieved_docs, model, tokenizer, top_n=3):
"""
對檢索到的文檔進行重排序
Args:
query: 用户查詢
retrieved_docs: 檢索到的文檔列表
model: 重排序模型
tokenizer: 重排序模型的tokenizer
top_n: 返回頂部多少個文檔
Returns:
sorted_docs: 按相關性分數降序排列的文檔列表
scores: 對應的分數列表
"""
# 構建(query, doc)對
pairs = [(query, doc.page_content) for doc in retrieved_docs]
# Tokenize所有文本對
with torch.no_grad(): # 禁用梯度計算,加快推理速度
inputs = tokenizer(
pairs,
padding=True,
truncation=True,
return_tensors='pt',
max_length=512
)
# 模型前向傳播,計算分數
scores = model(**inputs).logits.squeeze(dim=-1).float().numpy()
# 將分數和文檔打包在一起
doc_score_list = list(zip(retrieved_docs, scores))
# 按分數降序排序
doc_score_list.sort(key=lambda x: x[1], reverse=True)
# 解包,返回Top N個文檔和它們的分數
sorted_docs = [doc for doc, score in doc_score_list[:top_n]]
sorted_scores = [score for doc, score in doc_score_list[:top_n]]
return sorted_docs, sorted_scores
# 4. 執行重排序
reranked_docs, reranked_scores = rerank_docs(query, initial_retrieved_docs, model, tokenizer, top_n=3)
# 5. 打印結果
print("\n=== 重排序後結果(基於交叉編碼相關性)===")
for i, (doc, score) in enumerate(zip(reranked_docs, reranked_scores)):
print(f"{i+1}. [相關性分數: {score:.4f}] {doc.page_content}")
# 6. 將精排後的上下文傳遞給LLM(這裏用打印模擬)
context_for_llm = "\n".join([doc.page_content for doc in reranked_docs])
prompt = f"""
基於以下上下文,請回答問題。
上下文:
{context_for_llm}
=== 最終輸出最優的匹配結果 ===
問題:{query}
答案:{reranked_docs[0].page_content}
"""
print(f"\n=== 最終提供給LLM的Prompt ===")
print(prompt)
2. 執行結果
=== 初始檢索結果(基於語義相似度)===
1. [相似度得分: N/A] 蘋果公司於1976年由史蒂夫·喬布斯、史蒂夫·沃茲尼亞克和羅納德·韋恩創立,最初主要生產和銷售個人電腦
。
2. [相似度得分: N/A] 蒂姆·庫克是蘋果公司的現任首席執行官,於2011年接替史蒂夫·喬布斯。
3. [相似度得分: N/A] 蘋果公司在2023年發佈了其首款混合現實頭顯設備Apple Vision Pro。
4. [相似度得分: N/A] 水果蘋果是一種薔薇科蘋果屬的落葉喬木果實,營養價值高,富含維生素和纖維。
=== 重排序後結果(基於交叉編碼相關性)===
1. [相關性分數: 9.3700] 蘋果公司於1976年由史蒂夫·喬布斯、史蒂夫·沃茲尼亞克和羅納德·韋恩創立,最初主要生產和銷售個人電
腦。
2. [相關性分數: 4.5305] 蒂姆·庫克是蘋果公司的現任首席執行官,於2011年接替史蒂夫·喬布斯。
3. [相關性分數: -6.0679] 蘋果公司在2023年發佈了其首款混合現實頭顯設備Apple Vision Pro。
=== 最終提供給LLM的Prompt ===
基於以下上下文,請回答問題。
上下文:
蘋果公司於1976年由史蒂夫·喬布斯、史蒂夫·沃茲尼亞克和羅納德·韋恩創立,最初主要生產和銷售個人電腦。
蒂姆·庫克是蘋果公司的現任首席執行官,於2011年接替史蒂夫·喬布斯。
蘋果公司在2023年發佈了其首款混合現實頭顯設備Apple Vision Pro。
=== 最終輸出最優的匹配結果 ===
問題:蘋果公司的創始人是誰?
答案:蘋果公司於1976年由史蒂夫·喬布斯、史蒂夫·沃茲尼亞克和羅納德·韋恩創立,最初主要生產和銷售個人電腦。
3. 代碼詳解
1. 初始設置:
- 使用sentence-transformers的嵌入模型和FAISS構建一個簡單的向量檢索庫。
- 定義了一個有歧義的查詢“蘋果公司的創始人是誰?”。注意,知識庫中既包含科技公司“蘋果”,也包含水果“蘋果”。
2. 初始檢索:
- vectorstore.similarity_search(query, k=4) 召回了4個最“語義相似”的文檔。
- 由於Embedding模型的理解是廣義語義的,水果“蘋果”的文檔也可能被召回(例如,文檔3和5)。
3. 初始化Rerank模型:
- 使用transformers庫加載預訓練的BAAI/bge-reranker-base模型和其對應的分詞器。
- model.eval()將模型設置為評估模式,這會關閉Dropout等訓練層,保證輸出的一致性。
4. 重排序函數 rerank_docs:
- 構建對:將查詢和每一個檢索到的文檔內容組成(Query, Document)對。
- Tokenize:使用tokenizer將所有這些文本對處理成模型可接受的輸入格式(input_ids, attention_mask等)。padding=True和truncation=True確保了不同長度的文本對可以被批量處理。
- 模型推理:將處理好的輸入傳遞給模型。with torch.no_grad()塊確保不計算梯度,大幅減少內存消耗並加快推理速度。模型的輸出是一個分數,分數越高代表相關性越強。
- 排序與篩選:根據模型計算出的相關性分數對文檔進行降序排序,並返回Top N個文檔。
5. 結果分析:
- 初始檢索結果:可能包含水果蘋果的文檔,因為它們也包含“蘋果”這個詞,語義上有相似性。
- 重排序後結果:Rerank模型作為“相關性專家”,能夠精確理解“蘋果公司”這個特定實體的查詢意圖。它會給科技公司蘋果的文檔打出非常高的分數,而給水果蘋果的文檔打出很低的分數。最終,Top結果中只會留下最相關的科技公司蘋果的文檔。
4. 模型引用
示例中使用了兩個模型sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2和BAAI/bge-reranker-base,都可以本地化部署,前者是一個嵌入模型用於初始檢索,它將句子和段落映射到384維的密集向量空間中,可用於聚類或語義搜索等任務;後者前文介紹過,是專門做Rerank的模型,它直接計算查詢(Query)與文檔(Document)的交互相關性得分,也可本地部署。
在代碼運行時,模型檢測到本地沒有,會自動從線上下載:

下載完成的模型目錄:
模型下載完成後,再次運行時會直接從本地讀取!
從示例輸出可以清晰看到,重排序後,直接包含答案“創始人”的文檔排到了第一,並且所有排名靠前的文檔都是關於科技公司的,水果相關的文檔被有效地過濾掉了。這樣提供給LLM的上下文質量極高,能保證生成答案的準確性。
通過這個流程,Rerank模型極大地提升了RAG系統的最終表現,是其從可用到好用的關鍵升級。
示例2:如何學習鋼琴
1. 基礎代碼
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
class BGEReranker:
def __init__(self, model_name="BAAI/bge-reranker-base"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(model_name)
self.model.eval() # 設置為評估模式
def rerank(self, query: str, documents: list, top_k: int = 5):
"""
對文檔進行重排序
:param query: 用户查詢
:param documents: 候選文檔列表
:param top_k: 返回前K個文檔
:return: 排序後的文檔和分數
"""
# 構建查詢-文檔對
pairs = [(query, doc) for doc in documents]
# 特徵編碼
with torch.no_grad():
inputs = self.tokenizer(
pairs,
padding=True,
truncation=True,
return_tensors='pt',
max_length=512
)
# 計算相關性分數
scores = self.model(**inputs).logits.squeeze(dim=-1).float().numpy()
# 組合文檔和分數
scored_docs = list(zip(documents, scores))
# 按分數降序排序
scored_docs.sort(key=lambda x: x[1], reverse=True)
return scored_docs[:top_k]
# 使用示例
if __name__ == "__main__":
# 初始化重排序模型
reranker = BGEReranker()
# 用户查詢
query = "如何學習鋼琴?"
# 初始檢索結果(假設從FAISS獲取)
initial_docs = [
"鋼琴保養和清潔方法",
"音樂理論基礎入門",
"鋼琴購買指南:如何選擇第一台鋼琴",
"鋼琴入門指法教程:從零開始學習",
"十大著名鋼琴家及其作品",
"鋼琴練習曲目推薦:適合初學者"
]
print("初始檢索結果:")
for i, doc in enumerate(initial_docs):
print(f"{i+1}. {doc}")
# 應用重排序
reranked_docs = reranker.rerank(query, initial_docs, top_k=3)
print("\n重排序後結果:")
for i, (doc, score) in enumerate(reranked_docs):
print(f"{i+1}. [分數: {score:.4f}] {doc}")
print("\n最優的匹配結果:")
print(reranked_docs[0][0])
2. 執行結果
初始檢索結果:
1. 鋼琴保養和清潔方法
2. 音樂理論基礎入門
3. 鋼琴購買指南:如何選擇第一台鋼琴
4. 鋼琴入門指法教程:從零開始學習
5. 十大著名鋼琴家及其作品
6. 鋼琴練習曲目推薦:適合初學者
重排序後結果:
1. [分數: 1.7239] 鋼琴入門指法教程:從零開始學習
2. [分數: 0.7639] 音樂理論基礎入門
3. [分數: -1.1614] 鋼琴練習曲目推薦:適合初學者
最優的匹配結果:
鋼琴入門指法教程:從零開始學習
八、總結
重排序(Rerank)是RAG系統中提升精度的關鍵技術,它能夠深度理解查詢和文檔間的語義關係、精細排序初步檢索結果篩選最相關文檔、顯著提升最終生成答案的質量和準確性。
雖然引入了一定的計算開銷,但在大多數重視準確性的應用場景中,重排序帶來的性能提升遠遠超過了其成本,是現代RAG系統不可或缺的組件。
對於精度要求極高的場景(如醫療、法律),強烈推薦使用Rerank。對於延遲敏感或資源有限的場景,可以酌情省略或減少重排序的文檔數量(K)。選擇合適的重排序策略和模型,能夠讓RAG系統從能用升級到好用,真正發揮檢索增強生成的全部潛力。