
一、温故知新
回顧前面幾篇文章,我們分別對文生圖的案例演示和RAG Query改寫做了詳細介紹,今天我們再趣味性的強化一下兩者的應用途徑,結合兩個模型Qwen-Turbo和Qwen-Image同時使用,將自然語言處理與計算機視覺完美結合,發現兩者的奧妙之處。

二、系統介紹
先看看展示界面:
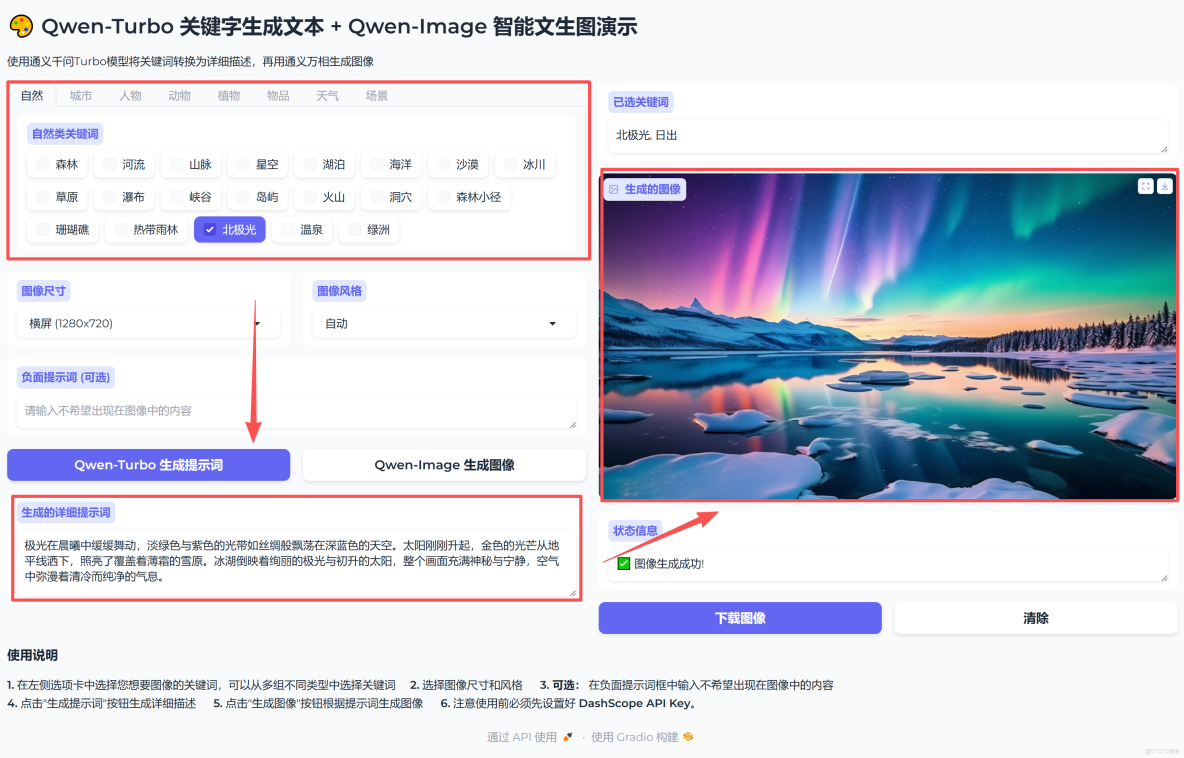
示例關鍵詞:北極光, 日出
示例生成的文案:極光在晨曦中緩緩舞動,淡綠色與紫色的光帶如絲綢般飄蕩在深藍色的天空。太陽剛剛升起,金色的光芒從地平線灑下,照亮了覆蓋着薄霜的雪原。冰湖倒映着絢麗的極光與初升的太陽,整個畫面充滿神秘與寧靜,空氣中瀰漫着清冷而純淨的氣息。
生成的圖片:

看系統界面,清楚我們使用Gradio構建的一個演示界面,該界面將展示如何使用Qwen-Turbo生成提示詞,然後使用Qwen-Image生成圖像。 我們將按照之前的設計,將流程分為兩個主要步驟:先生成提示詞,然後生成圖像。在提示詞生成成功之前,直接生成圖像將會給出提示先生成提示詞。
系統的核心在於三個主要功能模塊:關鍵詞管理、提示詞生成和圖像處理。關鍵詞管理系統提供了結構化的選擇方式,用户可以從多個類別中選擇感興趣的關鍵詞,系統會自動將這些關鍵詞組合成有意義的查詢。
提示詞生成引擎是系統的智能核心,它不僅簡單拼接關鍵詞,而是理解用户的創作意圖,生成富有創意和細節的圖像描述。圖像處理模塊則負責將文本描述轉換為視覺內容,支持多種風格和尺寸的定製。
系統主要包含以下功能:
1. 關鍵詞選擇:使用選項卡和複選框組讓用户選擇關鍵詞。
2. 參數設置:下拉菜單選擇尺寸和風格,文本框輸入負面提示詞。
3. 生成提示詞:點擊按鈕調用Qwen-Turbo生成提示詞,並顯示在文本框中。
4. 生成圖像:只有在提示詞生成後才可點擊,調用Qwen-Image生成圖像並顯示。
5. 狀態顯示:顯示操作的狀態信息(成功、錯誤、進行中)。
6. 清除和下載功能:清除所有選擇,下載生成的圖像。
三、系統流程
實際操作過程簡單直觀:首先在界面左側選擇相關的關鍵詞,這些關鍵詞按主題分類,方便快速查找和選擇。接着設置圖像參數,包括尺寸、風格等可選設置。
點擊"生成提示詞"後,系統調用Qwen-Turbo生成詳細的圖像描述。獲得滿意的提示詞後,可以點擊"生成圖像"按鈕,系統將調用Qwen-Image創建最終的視覺作品。整個過程通常只需要幾分鐘,具體時間取決於圖像複雜度和服務器負載。
1. 流程圖
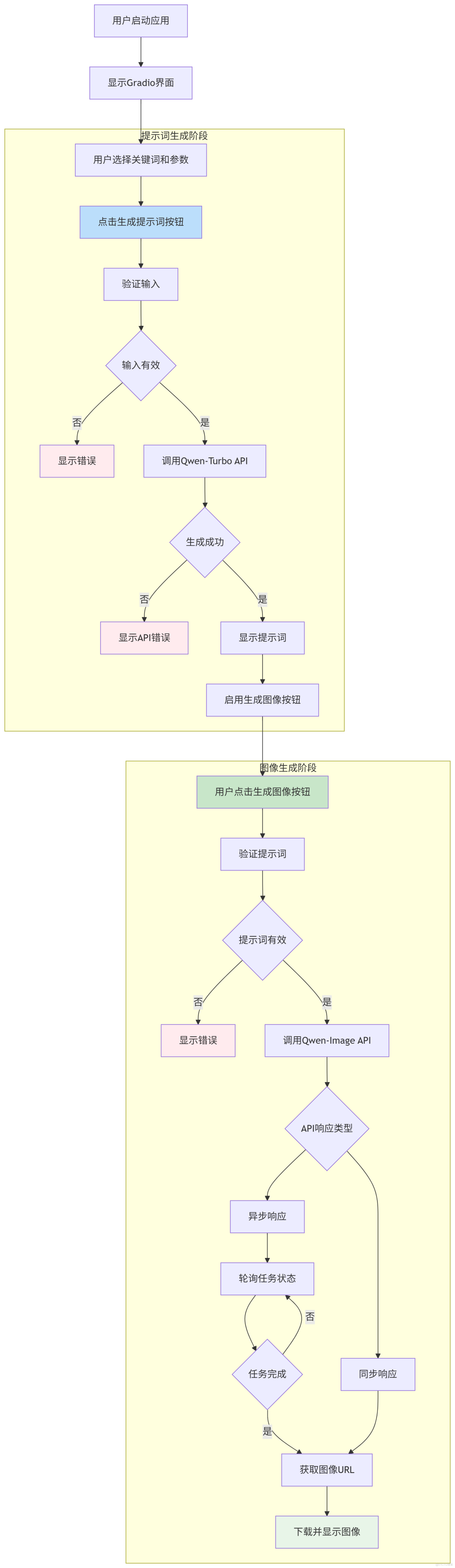
2. 流程介紹
2.1 應用啓動與初始化
- 用户啓動應用,加載Gradio界面
- 系統初始化API連接和參數設置
- 生成圖像按鈕初始狀態為禁用
2.2 提示詞生成
- 用户選擇關鍵詞和參數
- 點擊生成提示詞按鈕
- 系統驗證輸入有效性
- 調用Qwen-Turbo API生成詳細圖像描述
- 處理API響應,顯示生成的提示詞或錯誤信息
- 成功生成提示詞後啓用生成圖像按鈕
2.3 圖像生成
- 點擊生成圖像按鈕
- 系統驗證提示詞存在且有效
- 調用Qwen-Image API生成圖像
- 異步處理API響應
- 下載生成的圖像並顯示在界面
四、代碼參考與解析
import dashscope
from dashscope import ImageSynthesis
import requests
import tempfile
import os
import time
from PIL import Image
import io
import base64
import json
import gradio as gr
# 設置您的 DashScope API Key
DASHSCOPE_API_KEY = os.environ.get("DASHSCOPE_API_KEY", "") # 請替換為您的實際API Key
# 初始化 DashScope
dashscope.api_key = DASHSCOPE_API_KEY
# DashScope Qwen-Image 支持的風格參數
SUPPORTED_STYLES = {
"自動": "auto",
"3D卡通": "<3d cartoon>",
"動漫": "<anime>",
"油畫": "<oil painting>",
"水彩": "<watercolor>",
"素描": "<sketch>",
"中國畫": "<chinese painting>",
"扁平插畫": "<flat illustration>",
"攝影": "<photography>",
"肖像": "<portrait>"
}
# DashScope Qwen-Image 支持的尺寸參數
SUPPORTED_SIZES = {
"正方形 (1024x1024)": "1024*1024",
"橫屏 (1280x720)": "1280*720",
"豎屏 (720x1280)": "720*1280"
}
# 多組關鍵詞選項
KEYWORD_GROUPS = {
"自然": ["森林", "河流", "山脈", "星空", "湖泊", "海洋", "沙漠", "冰川", "草原", "瀑布",
"峽谷", "島嶼", "火山", "洞穴", "森林小徑", "珊瑚礁", "熱帶雨林", "北極光", "温泉", "綠洲"],
"城市": ["高樓", "街道", "公園", "夜景", "橋樑", "廣場", "地鐵", "商業區", "住宅區", "地標建築",
"咖啡館", "博物館", "美術館", "火車站", "機場", "港口", "書店", "餐廳", "購物中心", "體育場"],
"人物": ["兒童", "老人", "情侶", "家庭", "學生", "醫生", "藝術家", "運動員", "上班族", "旅行者",
"科學家", "教師", "音樂家", "舞蹈家", "演員", "作家", "攝影師", "廚師", "農民", "消防員", "解放軍"],
"動物": ["貓咪", "小狗", "熊貓", "老虎", "獅子", "大象", "海豚", "鳥類", "蝴蝶", "兔子",
"猴子", "長頸鹿", "斑馬", "企鵝", "考拉", "袋鼠", "熊", "狐狸", "狼", "馬"],
"植物": ["櫻花", "玫瑰", "竹子", "松樹", "向日葵", "仙人掌", "荷葉", "楓葉", "薰衣草", "鬱金香",
"百合", "牡丹", "菊花", "桂花", "茉莉花", "桃花", "杜鵑花", "梅花", "向日葵", "綠蘿"],
"物品": ["禮帽", "手杖", "書本", "咖啡杯", "吉他", "相機", "鐘錶", "花瓶", "雨傘", "揹包",
"眼鏡", "圍巾", "手套", "項鍊", "耳環", "戒指", "手錶", "錢包", "手機", "筆記本電腦"],
"天氣": ["晴天", "雨天", "雪天", "霧天", "日落", "日出", "彩虹", "雷電", "陰天", "微風",
"大風", "暴雨", "暴雪", "冰雹", "颱風", "霜凍", "露水", "霧霾", "多雲", "晴朗"],
"場景": ["咖啡館", "圖書館", "博物館", "海灘", "山脈", "森林", "花園", "未來城市", "賽博朋克", "太空站",
"海底世界", "古代城堡", "鄉村小屋", "豪華別墅", "小木屋", "沙漠帳篷", "雪山營地", "太空飛船", "閲兵式"]
}
def generate_prompt_with_qwen(keywords_dict, style=None):
"""
使用通義千問Turbo模型根據關鍵詞生成詳細的圖像描述提示詞
"""
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {DASHSCOPE_API_KEY}"
}
# 構建風格提示
style_prompt = ""
if style and style != "自動":
style_name = style
style_prompt = f",風格為{style_name}"
# 從字典中提取所有選中的關鍵詞
all_keywords = []
for group, keywords in keywords_dict.items():
if keywords:
all_keywords.extend(keywords)
# 如果沒有選擇任何關鍵詞,返回錯誤
if not all_keywords:
return None, "請至少選擇一個關鍵詞"
# 將關鍵詞列表組合成字符串
keywords_str = ",".join(all_keywords)
# 構建請求體
payload = {
"model": "qwen-turbo",
"input": {
"messages": [
{
"role": "system",
"content": "你是一個專業的圖像描述生成助手。你的任務是根據用户提供的關鍵詞,生成一段150字以內的詳細、生動、富有想象力的圖像描述,用於AI文生圖模型。描述應該包含場景、主體、動作、環境、光線、色彩、情緒等細節,使AI能夠生成高質量的圖像。"
},
{
"role": "user",
"content": f"請根據以下關鍵詞生成一段詳細的圖像描述{style_prompt},描述應該具體、生動,包含足夠的細節,適合用於AI文生圖:{keywords_str}。請直接給出描述文本,不要包含任何解釋或其他內容。"
}
]
},
"parameters": {
"temperature": 0.8,
"top_p": 0.8,
"result_format": "message"
}
}
try:
print(f"發送請求到Qwen-Turbo API: {json.dumps(payload, ensure_ascii=False)}")
response = requests.post(url, headers=headers, json=payload)
response_data = response.json()
print(f"Qwen-Turbo API響應: {json.dumps(response_data, ensure_ascii=False, indent=2)}")
if response.status_code == 200 and "output" in response_data:
# 提取生成的提示詞
generated_prompt = response_data["output"]["choices"][0]["message"]["content"]
return generated_prompt, None
else:
error_msg = f"Qwen-Turbo API調用失敗,狀態碼: {response.status_code}"
if "message" in response_data:
error_msg += f", 錯誤信息: {response_data['message']}"
return None, error_msg
except Exception as e:
error_msg = f"調用Qwen-Turbo時發生異常: {str(e)}"
print(error_msg)
import traceback
traceback.print_exc()
return None, error_msg
def generate_image_direct(prompt, size, style=None, negative_prompt=None):
"""
直接使用HTTP請求調用DashScope API,避免dashscope庫的問題
"""
if not DASHSCOPE_API_KEY or DASHSCOPE_API_KEY == "":
return "請先設置您的 DashScope API Key"
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text2image/image-synthesis"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {DASHSCOPE_API_KEY}",
"X-DashScope-Async": "enable" # 啓用異步調用
}
# 構建請求體
payload = {
"model": "wanx-v1",
"input": {
"prompt": prompt
},
"parameters": {
"size": size,
"n": 1
}
}
# 添加風格參數(如果提供且不是"自動")
if style and style != "自動":
# 將中文風格名稱轉換為API支持的格式
style_code = SUPPORTED_STYLES.get(style, "auto")
payload["parameters"]["style"] = style_code
# 添加負面提示(如果提供)
if negative_prompt and negative_prompt.strip():
payload["parameters"]["negative_prompt"] = negative_prompt
try:
print(f"發送請求到DashScope API: {json.dumps(payload, ensure_ascii=False)}")
response = requests.post(url, headers=headers, json=payload)
response_data = response.json()
print(f"API響應: {json.dumps(response_data, ensure_ascii=False, indent=2)}")
if response.status_code == 200:
# 檢查是否為異步任務
if "output" in response_data and "task_status" in response_data["output"]:
task_id = response_data["output"]["task_id"]
print(f"異步任務已創建,任務ID: {task_id}")
# 輪詢任務狀態
return poll_task_result(task_id)
elif "output" in response_data and "results" in response_data["output"]:
# 同步響應,直接獲取結果
if len(response_data["output"]["results"]) > 0:
image_url = response_data["output"]["results"][0]["url"]
return download_and_save_image(image_url)
else:
return "API響應中未包含有效結果"
else:
return "API響應格式不正確"
else:
error_msg = f"API調用失敗,狀態碼: {response.status_code}"
if "message" in response_data:
error_msg += f", 錯誤信息: {response_data['message']}"
return error_msg
except Exception as e:
error_msg = f"發生異常: {str(e)}"
print(error_msg)
import traceback
traceback.print_exc()
return error_msg
def poll_task_result(task_id, max_attempts=30, delay=2):
"""
輪詢異步任務結果
"""
if not DASHSCOPE_API_KEY or DASHSCOPE_API_KEY == "":
return "請先設置您的 DashScope API Key"
url = f"https://dashscope.aliyuncs.com/api/v1/tasks/{task_id}"
headers = {
"Authorization": f"Bearer {DASHSCOPE_API_KEY}"
}
attempt = 0
while attempt < max_attempts:
try:
print(f"輪詢任務狀態,嘗試 {attempt + 1}/{max_attempts}")
response = requests.get(url, headers=headers)
response_data = response.json()
print(f"任務狀態響應: {json.dumps(response_data, ensure_ascii=False, indent=2)}")
if response.status_code == 200:
if "output" not in response_data:
return "API響應格式不正確,缺少output字段"
task_status = response_data["output"].get("task_status", "UNKNOWN")
if task_status == "SUCCEEDED":
if ("output" in response_data and
"results" in response_data["output"] and
len(response_data["output"]["results"]) > 0):
image_url = response_data["output"]["results"][0]["url"]
return download_and_save_image(image_url)
else:
return "任務成功但未包含有效結果"
elif task_status in ["FAILED", "CANCELED"]:
error_msg = f"任務失敗,狀態: {task_status}"
if "message" in response_data["output"]:
error_msg += f", 錯誤信息: {response_data['output']['message']}"
return error_msg
else:
# 任務仍在處理中,等待後再次嘗試
time.sleep(delay)
attempt += 1
else:
return f"獲取任務狀態失敗,狀態碼: {response.status_code}"
except Exception as e:
error_msg = f"輪詢任務時發生異常: {str(e)}"
print(error_msg)
time.sleep(delay)
attempt += 1
return "任務處理超時"
def download_and_save_image(image_url):
"""
下載圖像並保存到臨時文件
"""
try:
img_response = requests.get(image_url)
if img_response.status_code == 200:
# 創建臨時文件保存圖像
with tempfile.NamedTemporaryFile(delete=False, suffix='.png') as f:
f.write(img_response.content)
image_path = f.name
print("圖像下載成功!")
return image_path
else:
return f"下載圖像失敗,狀態碼: {img_response.status_code}"
except Exception as e:
return f"下載圖像時發生異常: {str(e)}"
# 創建 Gradio 界面
def create_interface():
with gr.Blocks(title="Qwen-Image 智能文生圖演示", theme=gr.themes.Soft()) as demo:
gr.Markdown("# 🎨 Qwen-Turbo 關鍵字生成文本 + Qwen-Image 智能文生圖演示")
gr.Markdown("使用通義千問Turbo模型將關鍵詞轉換為詳細描述,再用通義萬相生成圖像 ")
# 創建關鍵詞選項卡
keyword_components = {}
with gr.Row():
with gr.Column(scale=1):
# 關鍵詞選項卡 - 移除了不支持的label參數
with gr.Tabs():
for group_name, keywords in KEYWORD_GROUPS.items():
with gr.Tab(group_name):
# 為每組關鍵詞創建多選框,並存儲在字典中
keyword_components[group_name] = gr.CheckboxGroup(
choices=keywords,
label=f"{group_name}類關鍵詞",
interactive=True
)
# 使用gr.Row()將圖像尺寸和圖像風格合併成一行顯示
with gr.Row():
with gr.Column(scale=1):
# 使用支持的尺寸選項
size = gr.Dropdown(
choices=list(SUPPORTED_SIZES.keys()),
value="橫屏 (1280x720)",
label="圖像尺寸"
)
with gr.Column(scale=1):
# 使用支持的風格選項
style = gr.Dropdown(
choices=list(SUPPORTED_STYLES.keys()),
value="自動",
label="圖像風格"
)
negative_prompt = gr.Textbox(
label="負面提示詞 (可選)",
placeholder="請輸入不希望出現在圖像中的內容",
lines=1
)
with gr.Row():
generate_prompt_btn = gr.Button("Qwen-Turbo 生成提示詞", variant="primary")
generate_image_btn = gr.Button("Qwen-Image 生成圖像", variant="secondary")
# 生成的提示詞顯示
generated_prompt = gr.Textbox(
label="生成的詳細提示詞",
placeholder="這裏將顯示通義千問生成的詳細提示詞",
lines=3,
interactive=True
)
with gr.Column(scale=1):
# 將已選關鍵詞顯示框移到生成的圖像上方
selected_keywords_display = gr.Textbox(
label="已選關鍵詞",
placeholder="這裏將顯示所有已選擇的關鍵詞",
lines=1,
interactive=False
)
output_image = gr.Image(
label="生成的圖像",
interactive=False
)
status_text = gr.Textbox(
label="狀態信息",
interactive=False,
lines=1
)
with gr.Row():
download_btn = gr.Button("下載圖像", variant="primary")
clear_btn = gr.Button("清除", variant="stop")
# 將使用説明移到主Row外部,實現全屏顯示
with gr.Row():
with gr.Column():
gr.Markdown("### 使用説明")
gr.Markdown("""
__1.__ 在左側選項卡中選擇您想要圖像的關鍵詞,可以從多組不同類型中選擇關鍵詞 __2.__ 選擇圖像尺寸和風格
__3. 可選:__ 在負面提示詞框中輸入不希望出現在圖像中的內容
__4.__ 點擊"生成提示詞"按鈕生成詳細描述 __5.__ 點擊"生成圖像"按鈕根據提示詞生成圖像
__6.__ 注意使用前必須先設置好 __DashScope API Key__。
""")
# 添加一個函數,用於即時更新已選關鍵詞顯示
def update_selected_keywords_display(*args):
# args包含所有關鍵詞選擇組件的當前值
all_selected_keywords = []
for selected in args:
if selected:
all_selected_keywords.extend(selected)
# 將已選關鍵詞格式化為字符串顯示
keywords_display = ", ".join(all_selected_keywords)
return keywords_display
# 處理生成提示詞按鈕點擊事件
def on_generate_prompt_click(*args):
# 前 len(KEYWORD_GROUPS) 個參數是每組關鍵詞的選擇結果
selected_keywords_dict = {}
all_selected_keywords = []
for i, group_name in enumerate(KEYWORD_GROUPS.keys()):
selected_keywords_dict[group_name] = args[i]
# 收集所有已選關鍵詞
if args[i]:
all_selected_keywords.extend(args[i])
# 下一個參數是尺寸,再下一個是風格
style = args[len(KEYWORD_GROUPS) + 1]
if not any(selected_keywords_dict.values()):
yield None, "", "⚠️ 警告:請至少選擇一個關鍵詞!"
return
if not DASHSCOPE_API_KEY or DASHSCOPE_API_KEY == "您的API_KEY":
yield None, "", "⚠️ 警告:請先設置您的 DashScope API Key!"
return
# 更新狀態
status = "正在使用通義千問生成詳細提示詞..."
# 將已選關鍵詞格式化為字符串顯示
keywords_display = ", ".join(all_selected_keywords)
yield None, keywords_display, status
# 使用通義千問生成詳細提示詞
prompt, error = generate_prompt_with_qwen(selected_keywords_dict, style)
if error:
yield None, keywords_display, f"❌ 生成提示詞失敗: {error}"
else:
yield prompt, keywords_display, "✅ 提示詞生成成功!"
# 處理生成圖像按鈕點擊事件
def on_generate_image_click(prompt, size, style, negative_prompt):
if not prompt.strip():
yield None, "⚠️ 異常提醒:請先生成提示詞!"
return
if not DASHSCOPE_API_KEY or DASHSCOPE_API_KEY == "您的API_KEY":
yield None, "⚠️ 異常提醒:請先設置您的 DashScope API Key!"
return
# 更新狀態
status = "正在生成圖像,這可能需要一些時間..."
yield None, status
# 將用户友好的尺寸名稱轉換為API格式
api_size = SUPPORTED_SIZES.get(size, "1024*1024")
# 調用API生成圖像
result = generate_image_direct(prompt, api_size, style, negative_prompt)
# 檢查結果是圖像路徑還是錯誤信息
if isinstance(result, str) and result.endswith('.png') and os.path.exists(result):
yield result, "✅ 圖像生成成功!"
else:
yield None, f"❌ 生成圖像失敗: {result}"
# 處理清除按鈕點擊事件
def on_clear_click():
# 清除關鍵詞選擇
clear_keywords = [[] for _ in range(len(KEYWORD_GROUPS))]
# 清除其他組件
return clear_keywords + [None, "", "已清除圖像和提示詞"]
# 準備輸入參數列表:所有關鍵詞組件 + [尺寸, 風格]
generate_prompt_inputs = list(keyword_components.values()) + [size, style]
generate_prompt_btn.click(
fn=on_generate_prompt_click,
inputs=generate_prompt_inputs,
outputs=[generated_prompt, selected_keywords_display, status_text]
)
generate_image_btn.click(
fn=on_generate_image_click,
inputs=[generated_prompt, size, style, negative_prompt],
outputs=[output_image, status_text],
api_name="generate_image",
show_progress=True
)
# 處理下載按鈕點擊事件
def on_download_click(image):
if image is None:
return "沒有可下載的圖像"
# 獲取當前時間作為文件名
timestamp = int(time.time())
filename = f"qwen_image_{timestamp}.png"
try:
# 如果圖像是文件路徑
if isinstance(image, str) and os.path.exists(image):
import shutil
shutil.copy2(image, filename)
return f"圖像已保存為 {filename}"
else:
return "無法保存圖像:無效的圖像路徑"
except Exception as e:
return f"保存圖像時發生錯誤: {str(e)}"
download_btn.click(
fn=on_download_click,
inputs=output_image,
outputs=status_text
)
# 準備清除按鈕的輸出參數
clear_outputs = list(keyword_components.values()) + [output_image, generated_prompt, selected_keywords_display, status_text]
clear_btn.click(
fn=on_clear_click,
inputs=None,
outputs=clear_outputs
)
# 為每個關鍵詞選擇組件添加事件監聽,實現即時更新已選關鍵詞顯示
for component in keyword_components.values():
component.change(
fn=update_selected_keywords_display,
inputs=list(keyword_components.values()),
outputs=selected_keywords_display
)
return demo
# 啓動 Gradio 應用
if __name__ == "__main__":
# 檢查API密鑰是否已設置
if not DASHSCOPE_API_KEY or DASHSCOPE_API_KEY == "您的API_KEY":
print("警告: 請先設置您的 DashScope API Key")
print("您可以在代碼中設置 DASHSCOPE_API_KEY 變量")
# 創建並啓動 Gradio 界面
demo = create_interface()
demo.launch(
server_name="0.0.0.0", # 允許外部訪問
server_port=7861, # 設置端口
share=False, # 不創建公開鏈接
debug=True # 啓用調試模式
)
結構分析:
1. 導入和初始化
import dashscope
from dashscope import ImageSynthesis
import requests
import tempfile
import os
import time
from PIL import Image
import io
import base64
import json
import gradio as gr
# 設置API密鑰
DASHSCOPE_API_KEY = os.environ.get("DASHSCOPE_API_KEY", "")
dashscope.api_key = DASHSCOPE_API_KEY
- 導入必要的庫,包括DashScope SDK、HTTP請求、文件處理、圖像處理和Gradio界面庫
- 從環境變量獲取API密鑰並進行初始化
2. 參數配置
# 支持的風格和尺寸參數
SUPPORTED_STYLES = {...}
SUPPORTED_SIZES = {...}
# 多組關鍵詞選項
KEYWORD_GROUPS = {
"自然": ["森林", "河流", ...],
"城市": ["高樓", "街道", ...],
# ... 其他類別
}
- 定義了API支持的圖像風格和尺寸選項
- 創建了分類的關鍵詞庫,方便用户選擇
3. 核心功能函數
3.1 提示詞生成函數
def generate_prompt_with_qwen(keywords_dict, style=None):
- 使用Qwen-Turbo模型根據用户選擇的關鍵詞生成詳細的圖像描述
- 構建系統提示詞,指導模型生成適合AI繪畫的描述
- 處理API響應並提取生成的提示詞
- 輸入:用户選擇的關鍵詞和風格參數
處理:構建API請求,調用Qwen-Turbo模型
輸出:生成的詳細圖像描述提示詞
3.2 圖像生成函數
def generate_image_direct(prompt, size, style=None, negative_prompt=None):
- 直接使用HTTP請求調用DashScope API生成圖像
- 支持異步任務處理和輪詢機制
- 處理風格、尺寸和負面提示詞參數
- 輸入:生成的提示詞和用户設置的參數
處理:構建API請求,調用Qwen-Image模型
輸出:圖像URL或任務ID(異步任務)
3.3 輔助函數
def poll_task_result(task_id, max_attempts=30, delay=2):
def download_and_save_image(image_url):
- 實現異步任務狀態輪詢
- 下載生成的圖像並保存到臨時文件
4. Gradio界面構建
def create_interface():
- 創建多選項卡關鍵詞選擇界面
- 設計圖像參數配置區域(尺寸、風格、負面提示詞)
- 設置提示詞生成和圖像生成按鈕
- 添加狀態顯示和結果展示區域
5. 事件處理邏輯
def on_generate_prompt_click(*args):
def on_generate_image_click(prompt, size, style, negative_prompt):
def on_clear_click():
def on_download_click(image):
- 處理用户交互事件
- 協調提示詞生成和圖像生成流程
- 實現狀態更新和結果反饋
6. 函數的執行流程
這是一個簡化流程圖,清晰地展示了Qwen-Turbo和Qwen-Image協同工作的核心流程

五、應用場景與案例賞析
這一技術在實際應用中展現出巨大價值。在創意設計領域,設計師可以快速生成概念圖、靈感素材;在內容創作方面,自媒體工作者能夠為文章配圖、製作吸引人的封面;在教育領域,教師可以創建教學插圖、可視化教材。
商業應用案例同樣豐富:電商企業可以用其生成產品展示圖,營銷團隊可以創作廣告素材,甚至房地產行業也能用於生成房產概念圖。這些應用不僅提高了工作效率,更重要的是開啓了新的創作可能性。
案例1
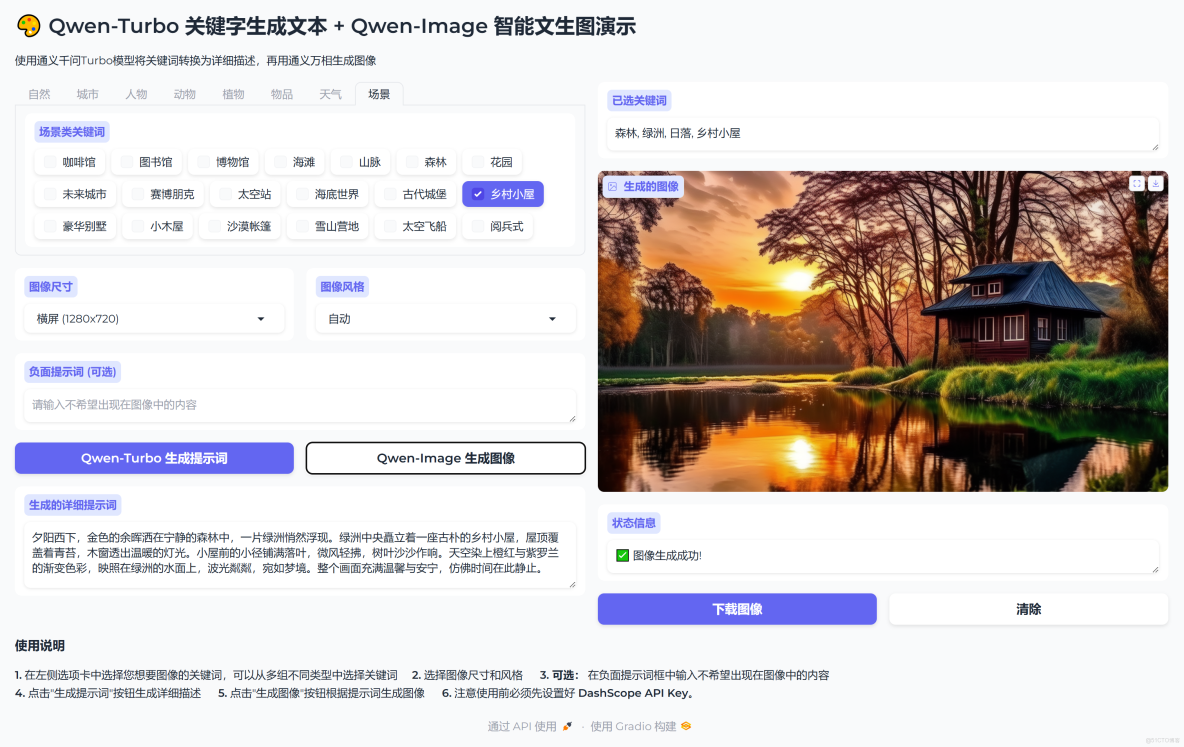
關鍵詞:森林, 綠洲, 日落, 鄉村小屋
生成的文案:夕陽西下,金色的餘暉灑在寧靜的森林中,一片綠洲悄然浮現。綠洲中央矗立着一座古樸的鄉村小屋,屋頂覆蓋着青苔,木窗透出温暖的燈光。小屋前的小徑鋪滿落葉,微風輕拂,樹葉沙沙作響。天空染上橙紅與紫羅蘭的漸變色彩,映照在綠洲的水面上,波光粼粼,宛如夢境。整個畫面充滿温馨與安寧,彷彿時間在此靜止。
生成的圖片:

案例2
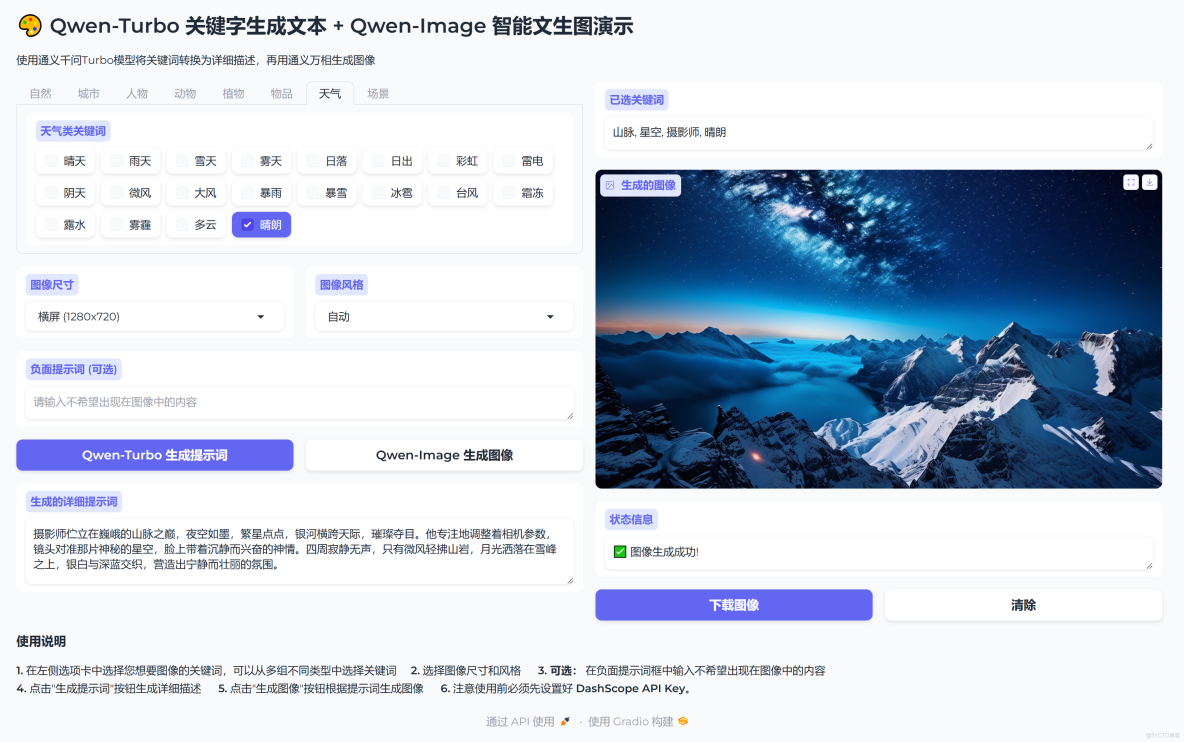
關鍵詞:山脈, 星空, 攝影師, 晴朗
生成的文案:攝影師佇立在巍峨的山脈之巔,夜空如墨,繁星點點,銀河橫跨天際,璀璨奪目。他專注地調整着相機參數,鏡頭對準那片神秘的星空,臉上帶着沉靜而興奮的神情。四周寂靜無聲,只有微風輕拂山岩,月光灑落在雪峯之上,銀白與深藍交織,營造出寧靜而壯麗的氛圍。
生成的圖片:

案例3
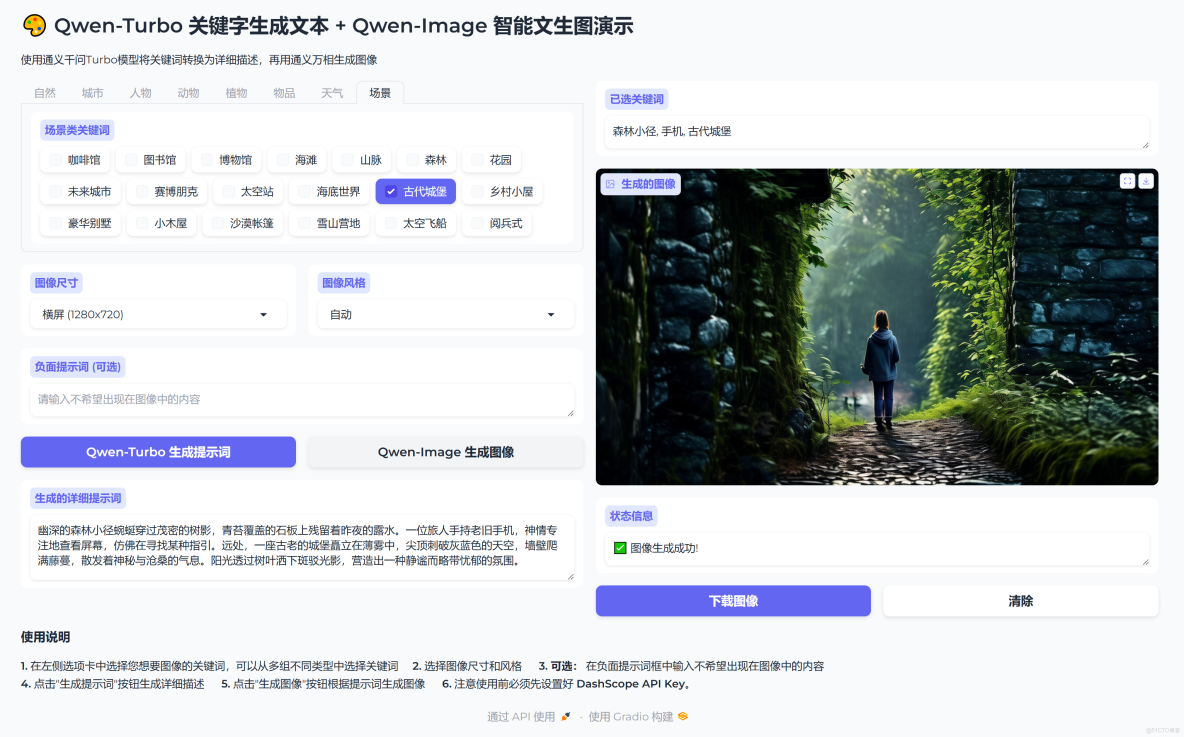
關鍵詞:森林小徑, 手機, 古代城堡
生成的文案:幽深的森林小徑蜿蜒穿過茂密的樹影,青苔覆蓋的石板上殘留着昨夜的露水。一位旅人手持老舊手機,神情專注地查看屏幕,彷彿在尋找某種指引。遠處,一座古老的城堡矗立在薄霧中,尖頂刺破灰藍色的天空,牆壁爬滿藤蔓,散發着神秘與滄桑的氣息。陽光透過樹葉灑下斑駁光影,營造出一種靜謐而略帶憂鬱的氛圍。
生成的圖片:

案例4
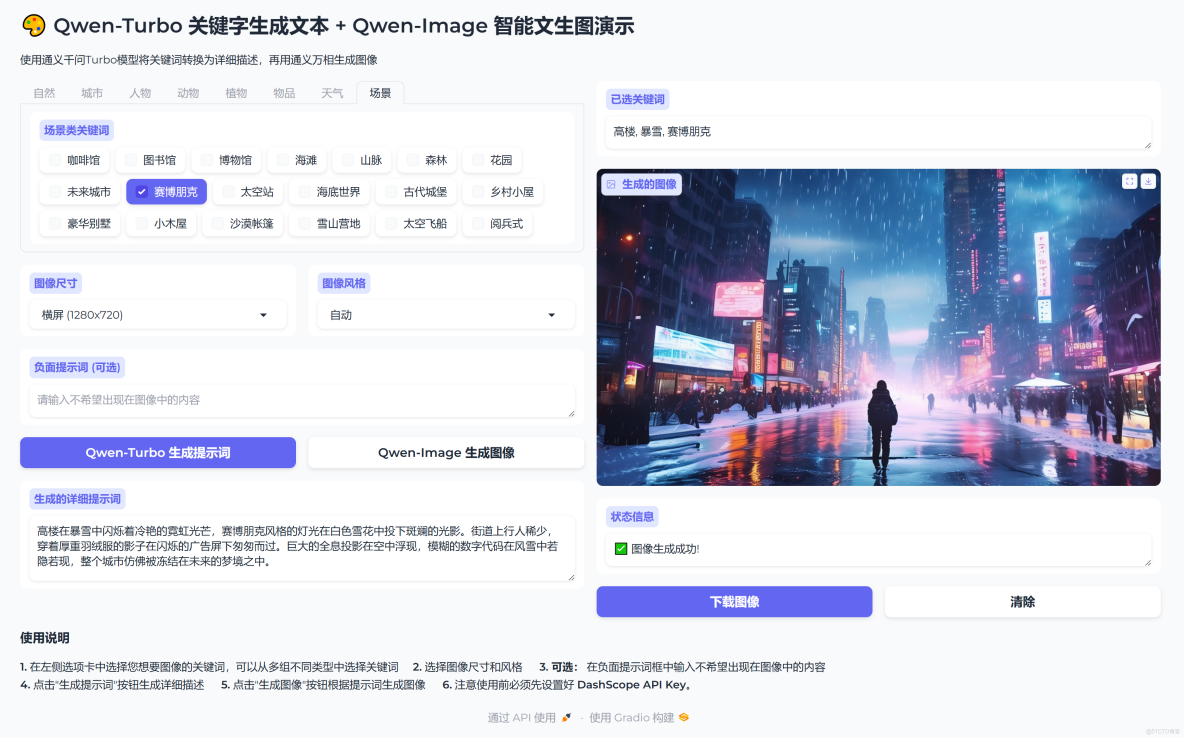
關鍵詞:高樓, 暴雪, 賽博朋克
生成的文案:高樓在暴雪中閃爍着冷豔的霓虹光芒,賽博朋克風格的燈光在白色雪花中投下斑斕的光影。街道上行人稀少,穿着厚重羽絨服的影子在閃爍的廣告屏下匆匆而過。巨大的全息投影在空中浮現,模糊的數字代碼在風雪中若隱若現,整個城市彷彿被凍結在未來的夢境之中。
生成的圖片:

六、總結
為了獲得最佳效果,我們也應該掌握一些實用技巧:在關鍵詞選擇時,儘量選擇相關性強、具體的詞彙;在提示詞生成後,可以適當編輯優化;對於圖像生成,可以嘗試不同的風格參數組合。
代碼性能方面,通過合理的API調用策略和緩存機制,可以優化提高響應速度。同時,還應該瞭解各種參數對生成結果的影響,以便更好地控制輸出質量。
隨着AI技術的不斷髮展,這一領域仍有巨大提升空間。未來的版本可能會支持更復雜的提示詞結構、更精細的風格控制、更快的生成速度。同時,應用場景也將進一步擴展,可能涵蓋視頻生成、3D模型創建等更復雜的視覺內容生產。
Qwen-Turbo與Qwen-Image的組合不僅是一次思維的風暴,也是AI內容創作的實際落地。雙模型架構不僅技術先進,更重要的是實用性強,能夠真正解決實際創作中的痛點。