
一、開篇導語
不知道大家有沒有刷到過一個趣味玩法,在輸入法的文本框以一個什麼字開頭,一直按下一個下一個,可以生成一句看似完整且有趣的話,這是最早期的通過鍵盤記憶形成的詞組文本。再看看近期豆包和deepseek大火,大家有沒有嘗試過給他們輸入一個簡短的文本或情節,讓他們進行續寫,生成一段內容,經歷過這些,不知道你是否曾好奇,這些功能強大的AI工具,是如何從“今天天氣真好”這樣簡單的開頭,生成出或嚴謹、或風趣、或充滿創意的長長段落的?它每次生成的答案為何時而穩定,時而多變?這背後的奧秘,就是基於語言模型的採樣方法在做決策。採樣方法決定了AI在每一步思考時,是做一個嚴謹的學霸,只認唯一答案;還是成為一個奔放的詩人,在詞海中自由徜徉。
今天,我們就來探討一下采樣方法的神秘面紗,瞭解這些了我們將不再是AI輸出的被動接受者,而將成為它的導演,學會如何通過調整温度、Top-p等這些旋鈕,精確地控制AI的性格和輸出風格。無論你是想讓AI基於知識庫做精準可靠的問答,還是讓它創作動人的故事,這篇文章都將帶你由淺入深,通過通俗的講解和豐富的代碼示例(結合Faiss檢索和Qwen大模型),徹底掌握這門與AI對話的藝術。

二、AI是怎麼説話的
想象一下,讓一個語言模型完成這句話:“今天的天氣真好啊,我們一起去...”。模型可能會計算出無數個後續詞的概率,比如“公園”(概率30%)、“散步”(概率25%)、“爬山”(概率15%)、“睡覺”(概率0.1%)等等。
如果我們每次都只選擇概率最高的“公園”,那麼模型生成的文本就會非常機械和可預測,缺乏驚喜和創造力。採樣或者説解碼策略,就是我們從這些概率分佈中選擇下一個詞的一系列規則和方法。它的目的是在生成文本的準確性、多樣性、流暢性和創造性之間取得平衡。
採樣,也叫解碼策略,就是我們教AI如何從這份“候選詞清單”裏挑詞的方法。不同的挑法,會讓AI變成不同的角色,是嚴謹的科學家,還是天馬行空的詩人?全看我們怎麼掌舵這個方向。
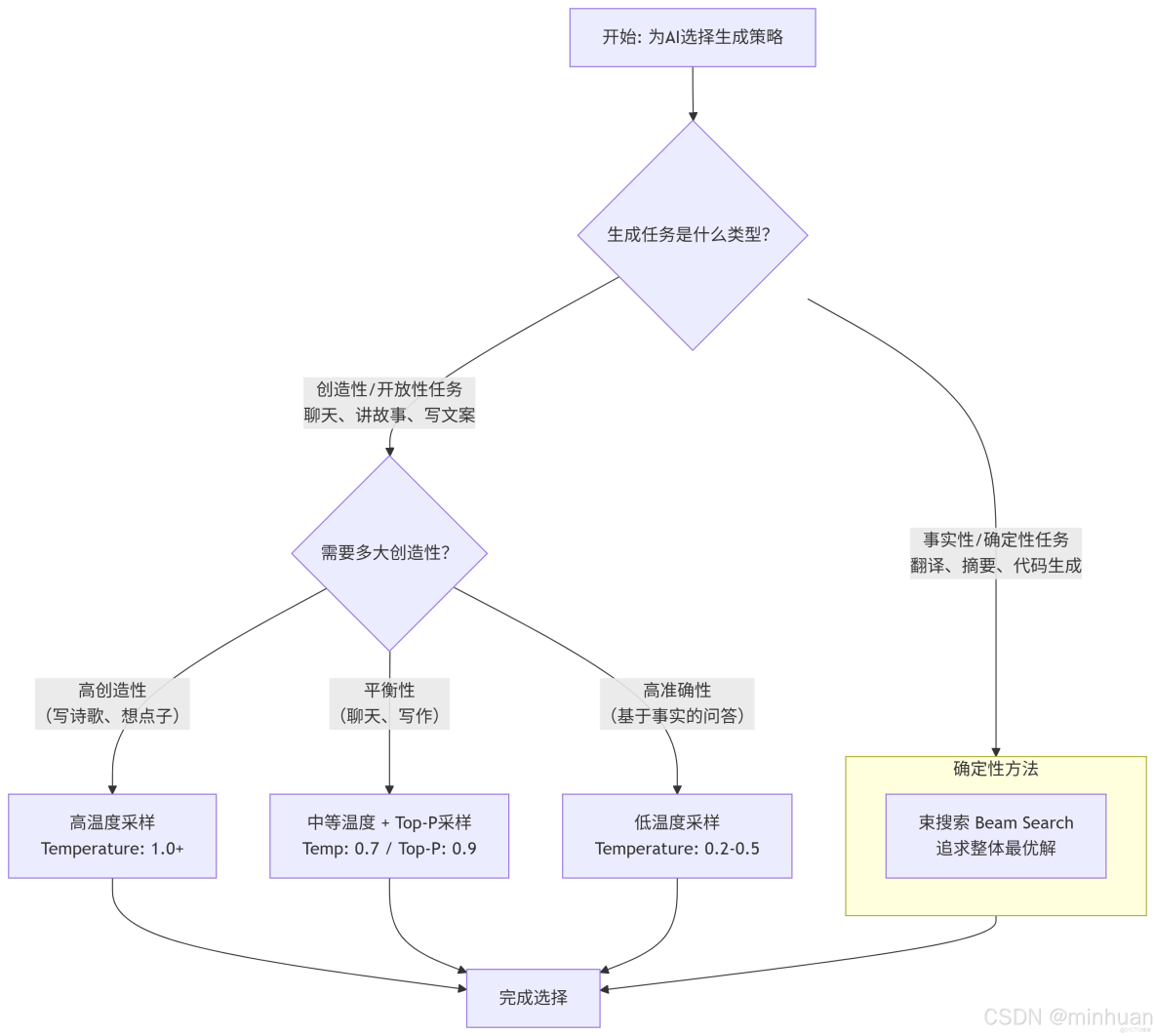
為了更直觀地理解如何選擇這些方法,我們可以參考下面的決策流程圖:
三、採樣方法
1. 確定性方法——“嚴謹的學霸”
這類方法的核心是每次都以某種確定性規則選擇概率最高的詞,就像是一個嚴謹的學霸,每次只認“最優解”,所以同樣的題目,每次給出的答案都一模一樣。
1.1 貪心算法
原理:每一步都毫不猶豫地選擇當前概率最高的詞。
通俗理解:永遠只選當前第一步最好的,不管後面。就像下棋,只吃對方眼前的一個兵,而不考慮接下來十步會不會輸。
示例一:提示詞:"夏天的午後,最適合吃一塊冰鎮的"
- "夏天的午後,最適合吃一塊冰鎮的",看到"西瓜"概率最高(25%),立馬選擇"西瓜"。
- 接着,"夏天的午後,最適合吃一塊冰鎮的西瓜",後面概率最高的可能是"。"(句號) ,生成結束。
- 最終輸出:"夏天的午後,最適合吃一塊冰鎮的西瓜。" (正確但平淡)
示例二:提示詞:"夏夜的星空,"
- 模型計算 "夏夜的星空," 之後的所有詞,發現 "格外" 概率最高,選擇 "格外";
- 現在句子是 "夏夜的星空,格外",模型計算下一個詞,發現 "明亮" 概率最高,選擇 "明亮";
- 句子變為 "夏夜的星空,格外明亮",模型計算下一個詞,"。"(句號)概率最高,選擇 "。",生成結束。
- 最終輸出:"夏夜的星空,格外明亮。"
優點: 計算高效,速度快。
缺點:容易生成重複、無聊的文本,並且可能錯過全局更優的序列。因為它可能為了第一步的“西瓜”,錯過了“冰鎮的芒果蛋糕真是太美味了”這樣更長更精彩的句子。
特點:正確但非常平淡、可預測,沒有任何驚喜。多次生成只會得到一模一樣的結果。
使用場景: 主要用於需要確定性輸出和快速生成的簡單任務,如實時翻譯或語音識別,但現在已較少用於開放式文本生成。
1.2 束搜索 - 貪心搜索的升級版
原理:貪心搜索的升級版,它不再是“孤注一擲”,而是有一個“容錯空間”。它會在每一步保留概率最大的k個候選序列,保留多條路徑,最終選擇整體概率最高的序列。
通俗理解:不是隻選1條路,而是同時探索多條(k條)最有潛力的路,最後看哪條路整體最好。
假設 k=2(束寬為2),就像派2個人並行探險。
示例一:提示詞:"夏天的午後,最適合吃一塊冰鎮的"
- 第一步:第一個人選概率最高的"西瓜"(25%),第二個人選第二高的"蛋糕"(20%)。
- 第二步:基於"西瓜"計算後面所有詞的概率(如"西瓜很", "西瓜。");基於"蛋糕"也計算一遍(如"蛋糕和", "蛋糕。")。然後從所有這些組合中("西瓜很", "西瓜。", "蛋糕和", "蛋糕。")再選出總體概率最高的2個序列。
- 第三步:如此反覆,直到所有人都走到句號為止。
示例二:提示詞: "夏夜的星空,"
- 第一步:選擇概率最高的兩個詞:"格外" (1st) 和 "非常" (2nd)。
- 第二步:對於路徑1 "格外":計算後續詞,比如 "明亮"、"的"...
- 對於路徑2 "非常":計算後續詞,比如 "明亮"、"美麗"...
- 現在比較所有組合:"格外明亮" vs "格外璀璨" vs "非常明亮" vs "非常美麗"... 假設 "非常美麗" 和 "格外明亮" 是整體概率最高的兩條路徑。
- 第三步:繼續基於這兩條路徑擴展,直到完成。
- 最終輸出:"夏夜的星空,非常美麗。" 或 "夏夜的星空,格外明亮。"
優點:比貪心搜索視野更廣,找到全局更優序列的可能性大得多,生成的文本通常整體更通順、更合理,如“非常美麗”整體上可能比“格外明亮”更優
缺點:生成的內容仍然比較保守、缺乏驚喜和多樣性,可能很平淡甚至乏味。而且k值越大,計算量也越大。
使用場景:非常適合有標準答案、事實性強、目標明確的任務,如機器翻譯、文本摘要、代碼生成,這些任務通常有一個“最佳”答案。
2. 隨機採樣方法——“富有創意的藝術家”
這類方法通過“擲骰子”的方式引入隨機性,從概率分佈中隨機抽取下一個詞,從而讓生成內容更具創造性和多樣性。讓AI變得更有創意。同樣的提示,每次生成的結果都可能不同。
2.1 基礎隨機採樣
原理:純粹地按照模型輸出的概率分佈進行隨機抽樣,概率為0.4的詞被抽中的機會就是40%,通俗的理解就是按照概率分佈“擲骰子”。
實例過程:
- 第一步:"夏夜的星空," 之後的概率分佈可能是 {"格外": 0.5, "非常": 0.3, "特別": 0.1, "有如": 0.05, ...}。它完全隨機地抽到了一個詞,比如 "特別"。
- 第二步:"夏夜的星空,特別" 之後的概率分佈,它又隨機抽到了 "的"。
- 第三步:"夏夜的星空,特別的",它可能抽到一個低概率詞,比如 "深邃"。
- 最終輸出:"夏夜的星空,特別的深邃。" (可能通順)
- 也可能輸出:"夏夜的星空,特別西瓜。" (不通順,甚至荒謬,因為它有可能抽到任何低概率詞)。
優點:最大化多樣性。
缺點:過於隨機,容易產生不合邏輯或不連貫的內容,甚至可能抽到一些奇怪的低概率詞。
特點:極度不可控,可能產生有趣的結果,但更可能生成無意義的內容。
使用場景: 在需要高度創造性的場景中偶爾使用,但通常需要與其他技術結合。
2.2 温度採樣 - 控制創意的油門
原理:通過温度參數調整概率分佈的平滑度後再採樣。
通俗理解:這是控制隨機性最常用、最有效的手段。它通過一個温度參數來調整概率分佈的形狀,然後再進行採樣。温度就是個“創意油門”。温度值(T)就像控制概率分佈是“尖峯”還是“平原”。
示例一:提示詞:"夏天的午後,最適合吃一塊冰鎮的"
低温度 (T < 1, 比如 0.2): “謹慎模式”。猛踩油門,猛踩油門,放大高概率詞的差距,讓分佈更“尖鋭”,讓高概率的詞(如“西瓜”)概率更高,低概率的詞(如“拖鞋”)概率更低。AI輸出更集中、更可靠、更保守。
- T=0.2時,概率分佈可能變為:"西瓜"(0.7) | "蛋糕"(0.2) | ... | "拖鞋"(0.0000001%)。AI幾乎肯定會選擇“西瓜”。
高温度 (T > 1, 比如 1.5): “瘋狂模式”。放鬆油門,平滑概率分佈,縮小高概率和低概率詞之間的差距,讓所有詞都有更接近的機會。AI輸出更隨機、更創意、也更可能出錯。
- T=1.5時,概率分佈可能變為:"西瓜"(0.2) | "蛋糕"(0.19) | "冰塊"(0.18) | "芒果"(0.17) | ...。AI可能會選擇“芒果”這樣更有創意的詞。
示例二:提示詞: "夏夜的星空,"
- 高温度 (T=1.5) 會拉平原始概率分佈。原本 "格外"(0.5) 和 "非常"(0.3) 差距很大,現在可能變成 "格外"(0.3), "非常"(0.25), "特別"(0.2), "有如"(0.15)... 差距變小了。
- 模型在這個被平滑後的分佈裏隨機採樣,它選中 "有如" 的概率就大大增加了。
- 後續步驟也遵循同樣規則。
- 最終輸出:"夏夜的星空,有如一幅閃爍的畫卷。" (更具文學性和創意)
特點:有效控制輸出的隨機性程度。低温度(T=0.5)會輸出更像貪心搜索的結果("格外明亮"),而高温度能鼓勵模型選擇更不尋常的詞,增加創造性。
使用場景:
低温度:聊天對話、事實問答、文本分析,追求準確和可靠。
高温度:寫詩歌、講故事、生成創意文案,追求新穎和出乎意料。
2.3 Top-k 採樣
通俗理解:為了解決基礎隨機採樣可能抽到奇怪低概率詞的問題,Top-k採樣只從概率最高的k個詞中進行採樣,並將這k個詞的概率重新歸一化,使它們的概率之和為1,然後只在這個k個詞的候選名單名單裏“擲骰子”。
原理:只從概率最高的k個詞裏採樣。
示例一:提示詞:"夏天的午後,最適合吃一塊冰鎮的",假設k=3
- 模型只考慮概率最高的3個詞:"西瓜"、"蛋糕"、"冰塊"。它會無視後面的所有詞(包括“拖鞋”),然後在前三名裏隨機選擇。
- 最終輸出:"夏天的午後,最適合吃一塊冰鎮的西瓜(蛋糕和冰塊都有可能)“
示例二:提示詞: "夏夜的星空,",假設k=40
- 模型計算出 "夏夜的星空," 之後概率最高的40個詞。這個名單裏可能包含 "格外", "非常", "特別", "無比", "彷彿", "像"... 等合理的詞。
- 它絕對排除了排名第41及以後的所有詞,比如一些完全不相關的名詞或動詞(如“西瓜”、“跑步”),避免了基礎隨機採樣的無意義的內容問題。
- 它在這個“Top-40精英名單”裏隨機抽樣,抽中了 "彷彿"。
- 最終輸出:"夏夜的星空,彷彿在低聲訴説着什麼。"
優點: 有效避免了低概率奇怪詞的干擾。
缺點:不夠靈活。有時候概率分佈可能很平,很多詞概率差不多,k值固定可能過濾掉很多合理的候選;有時候分佈很尖,只有一個詞概率極高,k值固定又可能引入不合適的候選。通俗的講就是有時候前3個詞都很合適,有時第4名其實也是個好詞,但被無情淘汰了。
特點:在保證質量的基礎上引入多樣性,避免了奇怪詞,但不夠靈活,因為k是固定值。
2.4 Top-p 採樣 (核採樣) - 創意候選名單
Top-k的升級版,解決了其不夠靈活的問題。它不固定候選詞的數量k,而是固定一個概率閾值p(通常0.7~0.95)。它從概率最高的詞開始累加,直到累積概率剛好超過p,然後只從這個小集合裏採樣。
原理:從累積概率超過p的最小詞集合中採樣。
通俗理解:不固定名單數量k,而是固定一個概率總和p。AI從高到低累加詞的概率,直到總和超過p,然後在這個動態的名單裏“擲骰子”。
示例一: 提示詞:"夏天的午後,最適合吃一塊冰鎮的",p=0.9。
- 模型對"夏天的午後,最適合吃一塊冰鎮的"之後的詞按概率從高到低排序並累加:
- 概率列表:"西瓜"(0.5) -> "蛋糕"(0.2) -> "冰塊"(0.15) -> "芒果"(0.1) -> ...
- 累加:0.5 + 0.2 = 0.7 < 0.9;0.7 + 0.15 = 0.85 < 0.9;0.85 + 0.1 = 0.95 > 0.9(停了!)。
- 於是,AI只在 {"西瓜", "蛋糕", "冰塊", "芒果"} 這個集合裏隨機選擇。
- 最終輸出:"夏天的午後,最適合吃一塊冰鎮的西瓜(蛋糕、冰塊、芒果都有可能)“
示例二:提示詞: "夏夜的星空,",p=0.9。
- 模型對 "夏夜的星空," 之後的詞按概率從高到低排序並累加:
- 概率列表:"格外" (0.5) -> "非常" (0.3) -> "特別" (0.1)
- 累加:0.5 + 0.3 = 0.8 < 0.9; 0.8 + 0.1 = 0.9 (剛好達到/超過0.9,停止!)
- 此時,動態的候選集合是 {"格外", "非常", "特別"}。模型只從這個集合裏隨機採樣,它抽中了 "特別"。
- 注意:像 "彷彿"(概率0.05)這次沒有被包含進來,因為累積概率在 "特別" 這裏已經達到閾值了。但如果某次提示的概率分佈更平緩,"彷彿" 就可能被包含進來。候選集大小是動態變化的。
- 最終輸出:"夏夜的星空,特別讓人心曠神怡。"
優點:超級智能!名單大小能根據當前概率分佈動態調整。是目前開放式創作的首選方法。
特點:智能且靈活,能自適應不同的概率分佈,是創造性任務的首選。它結合了Top-k的優點,同時又克服了其缺點。
使用場景: 幾乎所有的創造性文本生成任務,如與ChatGPT等聊天機器人的對話。
3. 示例的特性對比
|
方法 |
實例輸入 |
可能輸出實例 |
特點 |
|
貪心搜索 |
夏夜的星空, |
格外明亮。 |
單調、可預測、無驚喜 |
|
束搜索 |
夏夜的星空, |
非常美麗。 |
更通順,但依然保守 |
|
基礎隨機 |
夏夜的星空, |
特別西瓜。 或 特別的深邃。 |
極度隨機,可能荒謬 |
|
温度 (高)採樣 |
夏夜的星空, |
有如一幅閃爍的畫卷。 |
創造性高,文學性強 |
|
Top-k採樣 |
夏夜的星空, |
彷彿在低聲訴説。 |
質量有保障,多樣性好 |
|
Top-p採樣 |
夏夜的星空, |
特別讓人心曠神怡。 |
智能、靈活、首選 |
4. 方法總結
|
方法 |
核心思想 |
優點 |
缺點 |
適用場景 |
|
貪心搜索 |
每一步選最概率最高的 |
速度快 |
容易重複,缺乏多樣性 |
簡單任務,已少用 |
|
束搜索 |
每一步保留Top-k候選 |
生成更流暢準確 |
缺乏多樣性,計算量大 |
翻譯、摘要、代碼生成 |
|
温度採樣 |
用温度參數調整分佈形狀 |
有效控制隨機性 |
需手動調參 |
幾乎所有場景的微調 |
|
Top-k採樣 |
從Top-k詞中隨機選 |
避免奇怪詞 |
k值不靈活 |
創造性生成(較舊) |
|
Top-p採樣 |
從累積概率超p的詞中選 |
動態靈活,智能 |
需手動調參 |
創造性生成(首選) |
場景對應的組合選擇:
- 任務目標明確,有標準答案:束搜索 或 極低温度+Top-p。
- 開放式聊天、創意寫作:中等温度(0.7~1.0) + Top-p(0.9~0.95),這是當前最主流的組合。
- 需要高度隨機性和驚喜:高温度(>1.0) + Top-p。
四、方法示例
不同採樣方法在 RAG 系統中的代碼示例, 下面將為每種採樣方法提供結合 Faiss 檢索和 Qwen API 調用的具體代碼示例:
1. 公共部分的代碼
import dashscope
from dashscope import Generation
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
import os
# 設置API密鑰 - 請替換為您的實際API信息
dashscope.api_key = os.environ.get("DASHSCOPE_API_KEY")
# 1. 準備知識庫 - 中國古典詩詞知識
knowledge_base = [
"《靜夜思》是唐代詩人李白的詩作,表達了對故鄉的思念之情。牀前明月光,疑是地上霜。舉頭望明月,低頭思故鄉。",
"《水調歌頭·明月幾時有》是宋代蘇軾的代表作,是一首詠月懷人的詞。明月幾時有?把酒問青天。",
"《春曉》是唐代詩人孟浩然的詩作,描繪了春天早晨的景色。春眠不覺曉,處處聞啼鳥。夜來風雨聲,花落知多少。",
"杜甫是唐代偉大的現實主義詩人,被尊為詩聖,與李白合稱李杜。他的詩反映了唐代由盛轉衰的歷史過程。",
"《將進酒》是李白的一首豪放詩篇,表達了人生得意須盡歡的豪情。君不見黃河之水天上來,奔流到海不復回。",
"王維是唐代著名詩人、畫家,被譽為詩佛,他的詩多以山水田園為題材,充滿禪意。",
"《相思》是王維的詩作,借紅豆表達相思之情。紅豆生南國,春來發幾枝。願君多采擷,此物最相思。",
]
# 2. 將知識庫轉換成向量並構建Faiss索引
encoder = SentenceTransformer('D:/modelscope/hub/models/sentence-transformers/all-MiniLM-L6-v2')
kb_embeddings = encoder.encode(knowledge_base)
dimension = kb_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(kb_embeddings)
# 3. 用户查詢和檢索
user_query = "請介紹李白的《靜夜思》這首詩"
query_embedding = encoder.encode([user_query])
k = 3 # 從知識庫中檢索最相關的3條信息
distances, indices = index.search(query_embedding, k)
# 構建檢索到的上下文
retrieved_context = ""
for i, idx in enumerate(indices[0]):
retrieved_context += knowledge_base[idx] + "\n"
print(f"用户問: {user_query}")
print("---Faiss檢索到的最相關知識---")
print(retrieved_context)
# 4. 構建通用Prompt模板
def build_prompt(context, query):
return f"""
你是一個博學的中國古典文學專家。請根據以下【相關知識】,準確並專業地回答用户的問題。
如果相關知識中沒有答案,請如實告知你不知道。
【相關知識】
{context}
【用户問題】
{query}
【專家回答】
"""
# 5. Qwen API調用函數
def call_qwen_api(prompt, **kwargs):
"""
調用Qwen API生成文本
:param prompt: 輸入的提示文本
:param kwargs: 生成參數
:return: 生成的文本
"""
try:
response = Generation.call(
model="qwen-max", # 可根據需要選擇不同模型,如qwen-plus、qwen-max等
prompt=prompt,
**kwargs
)
return response.output.text
except Exception as e:
print(f"API調用出錯: {e}")
return None
輸出結果:
用户問: 請介紹李白的《靜夜思》這首詩
---Faiss檢索到的最相關知識---
《靜夜思》是唐代詩人李白的詩作,表達了對故鄉的思念之情。牀前明月光,疑是地上霜。舉頭望明月,低頭思故鄉。
《將進酒》是李白的一首豪放詩篇,表達了人生得意須盡歡的豪情。君不見黃河之水天上來,奔流到海不復回。
杜甫是唐代偉大的現實主義詩人,被尊為詩聖,與李白合稱李杜。他的詩反映了唐代由盛轉衰的歷史過程。
2. 貪心搜索示例
# 貪心搜索示例 - 通過設置temperature=0實現
print("\n=== 貪心搜索 ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用貪心搜索 - 設置temperature=0
response = call_qwen_api(
prompt,
temperature=0, # 温度為0相當於貪心搜索
max_tokens=200,
)
if response:
print(response)
else:
print("API調用失敗")
print("\n" + "="*50 + "\n")
輸出結果:
=== 貪心搜索 ===
《靜夜思》是唐代著名詩人李白創作的一首五言絕句,這首詩以其簡潔明快的語言和深刻的情感表達而廣為人知。全詩如下:
牀前明月光,
疑是地上霜。
舉頭望明月,
低頭思故鄉。
在這首詩中,李白通過描繪夜晚明亮的月光照進房間的情景,營造出一種寧靜而又略帶孤寂的氛圍。“疑是地上霜”一句巧妙地將月光
比作地上的白霜,既形象又富有詩意。接着,“舉頭望明月”表達了詩人抬頭仰望天空中的月亮的動作;最後一句“低頭思故鄉”,則直
接點出了整首詩的主題——對遠方家鄉的深深思念之情。這種由外在景象引發內心情感變化的手法,在李白的作品中十分常見,也使得
《靜夜思》成為了流傳千古、觸動無數遊子心絃的經典之作。
==================================================
3. 束搜索示例
# 束搜索示例 - 注意:Qwen API通常不支持束搜索參數
print("=== 束搜索 ===")
print("注意: Qwen API通常不支持束搜索參數,使用低温度替代")
prompt = build_prompt(retrieved_context, user_query)
# 使用低温度模擬束搜索的效果
response = call_qwen_api(
prompt,
temperature=0.1, # 低温度模擬束搜索的確定性
max_tokens=200,
)
if response:
print(response)
else:
print("API調用失敗")
print("\n" + "="*50 + "\n")
輸出結果:
=== 束搜索 ===
注意: Qwen API通常不支持束搜索參數,使用低温度替代
《靜夜思》是唐代著名詩人李白創作的一首五言絕句,這首詩以其簡潔明快的語言和深刻的情感表達而廣為人知。全詩如下:
牀前明月光,
疑是地上霜。
舉頭望明月,
低頭思故鄉。
在這首詩中,李白通過描繪夜晚獨自一人時所見的明亮月光,巧妙地將自然景象與個人情感相結合。首句“牀前明月光”直接點出了詩
人所在環境以及引起他注意的事物——那灑落在牀前如同白霜般的皎潔月光。“疑是地上霜”進一步強化了這種視覺上的錯覺,同時也暗
示着一種清冷孤寂之感。接下來,“舉頭望明月”,詩人抬頭仰望着天空中的滿月,這一動作不僅表達了他對美好事物的嚮往,也隱含
着對遠方親人或家鄉的思念之情。“低頭思故鄉”則是整首詩情感的核心所在
==================================================
4. 温度採樣示例
# 温度採樣示例 - 低温度
print("=== 温度採樣 - 低温度 (T=0.3) ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用温度採樣 - 低温度
response = call_qwen_api(
prompt,
temperature=0.3, # 低温度,輸出更確定
max_tokens=200,
)
if response:
print(response)
else:
print("API調用失敗")
print("\n" + "="*50 + "\n")
# 温度採樣示例 - 高温度
print("=== 温度採樣 - 高温度 (T=1.5) ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用温度採樣 - 高温度
response = call_qwen_api(
prompt,
temperature=1.5, # 高温度,輸出更隨機
max_tokens=200,
)
if response:
print(response)
else:
print("API調用失敗")
print("\n" + "="*50 + "\n")
輸出結果:
=== 温度採樣 - 低温度 (T=0.3) ===
《靜夜思》是唐代著名詩人李白創作的一首五言絕句,這首詩以其簡潔而深刻的語言表達了作者在寂靜夜晚對遠方家鄉的深切思念之
情。全詩如下:
牀前明月光,
疑是地上霜。
舉頭望明月,
低頭思故鄉。
在這首詩中,“牀前明月光”描繪了一個寧靜夜晚裏明亮皎潔的月光照進了屋內;“疑是地上霜”則通過將月光比作地上的白霜來進一步
強調了月色之明亮以及環境之清冷。“舉頭望明月”,當詩人抬頭仰望着那輪高掛天空中的圓月時,不禁勾起了他對遠方家人的無限懷
念與嚮往;最後一句“低頭思故鄉”,則是直接點出了整首詩的主題——對故鄉深深的思念之情。整首作品語言樸素自然,情感真摯動人
,充分展現了李白詩歌中既有豪放不羈也有細膩柔
==================================================
=== 温度採樣 - 高温度 (T=1.5) ===
《靜夜思》是唐代詩人李白所作的一首短詩,全詩只有四句二十字,但意境深邃、感人至深。它以簡潔明快的語言描繪了作者在寂靜
夜晚的深切思緒。“牀前明月光”,開篇就設置了一個寧靜而美麗的場景:明亮的月光照進屋內,“疑是地上霜”則是將月色比作寒冷季
節地面覆蓋的白霜,營造出一種清冷孤寂的氛圍。接着,“舉頭望明月”,詩人抬頭仰望天空中懸掛着的月亮,這裏的“望”字不僅描述
了動作,也表達了內心對遠方(可能是故鄉或親人)深切的掛念。“低頭思故鄉”最後一句,則直接點出了詩人此時此刻最真實的感情
狀態——思念家鄉。整首詩歌通過對月光景色細膩入微地描寫,巧妙地寓情於景,表達了遠離故土之人對家鄉的深深懷念之情。
==================================================
5. Top-k 採樣示例
# Top-k 採樣示例
print("=== Top-k 採樣 (k=30) ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用Top-k採樣
response = call_qwen_api(
prompt,
temperature=0.7, # 配合適中的温度
top_k=30, # 只從概率最高的30個詞中採樣
max_tokens=200,
)
if response:
print(response)
else:
print("API調用失敗")
print("\n" + "="*50 + "\n")
輸出結果:
=== Top-k 採樣 (k=30) ===
《靜夜思》是唐代著名詩人李白創作的一首膾炙人口的五言絕句,通過簡潔而富有畫面感的語言,表達了詩人在寂靜夜晚對遠方家鄉
深切的懷念之情。全詩如下:
牀前明月光,
疑是地上霜。
舉頭望明月,
低頭思故鄉。
這首詩以“牀前”的視角展開,首先映入眼簾的是明亮皎潔的月光,詩人初時誤以為是地上的白霜(這反映了夜間月色之明亮)。隨後
,他抬頭仰望着那輪高懸於空中的明月,在這樣的美景面前不禁想起了遙遠的家鄉。最後,“低頭思故鄉”一句,則直接點出了整首詩
歌的主題——即在外漂泊者對於故土難以割捨的情感寄託。整首詩語言樸素自然、情感真摯動人,成為中國古典文學中表達鄉愁的經典
之作之一。
==================================================
6. Top-p 採樣 (核採樣) 示例
# Top-p 採樣示例
print("=== Top-p 採樣 (p=0.9) ===")
prompt = build_prompt(retrieved_context, user_query)
# 使用Top-p採樣(核採樣)
response = call_qwen_api(
prompt,
temperature=0.7, # 配合適中的温度
top_p=0.9, # 從累積概率達到0.9的詞中採樣
max_tokens=200,
)
if response:
print(response)
else:
print("API調用失敗")
print("\n" + "="*50 + "\n")
輸出結果:
=== Top-p 採樣 (p=0.9) ===
《靜夜思》是唐代著名詩人李白創作的一首膾炙人口的五言絕句,這首詩以其簡潔明快的語言風格和深刻的情感表達深受後世讀者的
喜愛。全詩如下:
```
牀前明月光,
疑是地上霜。
舉頭望明月,
低頭思故鄉。
```
在這首詩中,李白通過對夜晚月色下景象的獨特描繪,表達了他對遠方家鄉深深的思念之情。“牀前明月光”,描述了作者夜晚醒來時
看到明亮皎潔的月光照進房間;“疑是地上霜”則通過將月光比喻成地面上覆蓋着一層薄霜來形象化這份清冷之美感,同時也暗示了季
節可能是在秋季或者是冬季初期。“舉頭望明月”表明詩人被這美麗的景色所吸引而抬頭凝視天空中的月亮;最後,“低頭思故鄉”直接
點出了整首詩的主題——無論身處何方,在這樣寧靜美好的夜晚裏
==================================================
7. 組合使用示例 (Temperature + Top-p)
# 組合使用示例 - 創造性回答
print("=== 組合採樣 (Temperature=0.8 + Top-p=0.9) ===")
creative_query = "請用富有詩意的語言介紹《靜夜思》"
prompt = build_prompt(retrieved_context, creative_query)
# 使用組合採樣 - 適合創造性任務
response = call_qwen_api(
prompt,
temperature=0.8, # 中等温度
top_p=0.9, # Top-p採樣
max_tokens=250,
)
if response:
print(response)
else:
print("API調用失敗")
print("\n" + "="*50 + "\n")
輸出結果:
=== 組合採樣 (Temperature=0.8 + Top-p=0.9) ===
在那寧靜而又深邃的夜晚,一輪明月悄悄地爬上了天際,將它那温柔而明亮的光芒灑向了大地。唐代詩人李白,在這樣一個萬籟俱寂
、唯有月色相伴的時刻,心中涌動着對遠方家鄉無盡的思念。他靜靜地坐在牀邊,眼前彷彿覆蓋了一層薄霜般的月光讓這位才華橫溢
的詩人不禁生出錯覺,以為是秋天的寒霜降臨。然而抬頭望向天空中那輪皎潔圓滿的月亮時,所有關於時間與空間的距離都瞬間被拉
近了——那不僅是天上的明珠,更是連接着遊子與故鄉之間最柔軟也最堅強的情感紐帶。
通過這首《靜夜思》,李白用極其簡練卻又充滿畫面感的語言,描繪了一個遠離家鄉的人在寂靜之夜對親人和故土深深眷戀之情。短
短四句詩,卻藴含着跨越千年仍舊能夠觸動人心絃的力量。每當有人身處異鄉仰望星空之時,《靜夜思》便如同一縷清風,穿越時空
界限,輕輕拂過每個漂泊者的心田,喚起那份埋藏心底對於“家”的永恆嚮往。
==================================================
8. 示例總結
通過上述示例,可以清楚地看到不同採樣方法的特點:
- 貪心搜索:輸出穩定、準確,但可能缺乏變化和創造性。
- 束搜索:比貪心搜索找到的句子通常更通順、完整,但依然較為保守。
- 基礎隨機:極度不可控,可能產生有趣的結果,但更可能生成無意義的內容。
- 温度採樣(低温度):輸出更加確定和可靠,適合事實性問答。
- 温度採樣(高温度):輸出更加隨機和富有創造性,適合文學性任務。
- Top-k 採樣:在保證質量的前提下引入多樣性,避免低概率奇怪詞。
- Top-p 採樣:智能動態地選擇候選詞,是目前創造性任務的首選方法。
- 組合採樣:通過調整温度和Top-p參數,可以精細控制生成文本的風格。
在實際應用中,你可以根據任務需求選擇合適的採樣方法:
- 事實性問答:低温度 + Top-p
- 創意寫作:中高温度 + Top-p
- 翻譯/摘要:束搜索 或 低温度採樣
- 開放式對話:中温度 + Top-p + 重複懲罰
這些示例展示瞭如何將Faiss檢索與Qwen大模型的不同採樣策略結合使用,構建一個靈活且強大的RAG系統。
五、組合示例
我們建一個“美食推薦機器人”。用户問:“天氣好熱,推薦點吃的吧?”。
- 用Faiss檢索:從美食知識庫中快速找到“清熱”、“解暑”、“夏季”相關的菜品描述。
- 用Qwen-max生成:把檢索到的信息餵給Qwen-max,讓它生成友好推薦。
代碼示例
import dashscope
from dashscope import Generation
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
import os
# 設置API密鑰 - 請替換為您的實際API密鑰
dashscope.api_key = os.environ.get("DASHSCOPE_API_KEY")
# 1. 準備一個模擬的"美食知識庫"
knowledge_base = [
"冰糖葫蘆是一種傳統的北方小吃,由山楂和糖製成,酸甜開胃,但適合冬天吃。",
"火鍋是四川特色,以麻辣鮮香著稱,但吃多了容易上火。",
"綠豆湯是由綠豆熬製而成的甜品,清熱解毒,是夏季消暑的佳品。",
"冰淇淋是一種冷凍奶製品,口感冰涼香甜,夏天食用能有效降温。",
"紅燒肉是一道著名的大眾菜餚,使用肥瘦相間的五花肉做成,油膩温熱,不適合夏天。",
"涼皮是陝西的特色小吃,口感滑嫩,涼爽可口,非常適合在炎熱的夏季食用。",
"姜撞奶是一種廣東甜品,由薑汁和牛奶製成,口感滑嫩,但姜性温熱。",
]
# 將知識庫轉換成向量並構建Faiss索引
encoder = SentenceTransformer('D:/modelscope/hub/models/sentence-transformers/all-MiniLM-L6-v2')
kb_embeddings = encoder.encode(knowledge_base)
dimension = kb_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(kb_embeddings)
# 2. 用户查詢和檢索
user_query = "天氣好熱,推薦點吃的吧?"
query_embedding = encoder.encode([user_query])
k = 3 # 從知識庫中檢索最相關的3條信息
distances, indices = index.search(query_embedding, k)
# 打印檢索到的內容
print(f"\n用户問: {user_query}")
print("---Faiss檢索到的最相關知識---")
retrieved_context = ""
for i, idx in enumerate(indices[0]):
print(f"{i+1}. {knowledge_base[idx]}")
retrieved_context += knowledge_base[idx] + "\n"
# 3. 構建Prompt,將檢索到的知識作為上下文
prompt = f"""
你是一個友好的美食推薦助手。請根據以下【相關知識】,回答用户的問題。
回答要簡短、親切、有吸引力。
【相關知識】
{retrieved_context}
【用户問題】
{user_query}
【助手推薦】
"""
print("\n---生成的Prompt---")
print(prompt)
# 4. 定義Qwen API調用函數
def call_qwen_api(prompt, **kwargs):
"""
調用Qwen API生成文本
:param prompt: 輸入的提示文本
:param kwargs: 生成參數
:return: 生成的文本
"""
try:
response = Generation.call(
model="qwen-max", # 可根據需要選擇不同模型,如qwen-plus、qwen-max等
prompt=prompt,
**kwargs
)
return response.output.text
except Exception as e:
print(f"API調用出錯: {e}")
return None
# 5. 關鍵步驟:選擇不同的採樣方法生成回覆
# 場景一:追求準確可靠(基於事實推薦)
print("\n---生成模式一: 準確模式(低温度+Top-p)---")
response = call_qwen_api(
prompt,
temperature=0.3, # 低温度,創造性低
top_p=0.9, # Top-p採樣
max_tokens=150, # 最多生成150個token
)
if response:
print(response)
else:
print("API調用失敗")
# 場景二:追求創意有趣(寫美食文案)
print("\n---生成模式二: 創意模式(中温度+Top-p)---")
response = call_qwen_api(
prompt,
temperature=0.8, # 中温度,創造性更高
top_p=0.92, # Top-p採樣
max_tokens=150, # 最多生成150個token
)
if response:
print(response)
else:
print("API調用失敗")
輸出結果
用户問: 天氣好熱,推薦點吃的吧?
---Faiss檢索到的最相關知識---
1. 冰糖葫蘆是一種傳統的北方小吃,由山楂和糖製成,酸甜開胃,但適合冬天吃。
2. 綠豆湯是由綠豆熬製而成的甜品,清熱解毒,是夏季消暑的佳品。
3. 紅燒肉是一道著名的大眾菜餚,使用肥瘦相間的五花肉做成,油膩温熱,不適合夏天。
---生成的Prompt---
你是一個友好的美食推薦助手。請根據以下【相關知識】,回答用户的問題。
回答要簡短、親切、有吸引力。
【相關知識】
冰糖葫蘆是一種傳統的北方小吃,由山楂和糖製成,酸甜開胃,但適合冬天吃。
綠豆湯是由綠豆熬製而成的甜品,清熱解毒,是夏季消暑的佳品。
紅燒肉是一道著名的大眾菜餚,使用肥瘦相間的五花肉做成,油膩温熱,不適合夏天。
【用户問題】
天氣好熱,推薦點吃的吧?
【助手推薦】
---生成模式一: 準確模式(低温度+Top-p)---
這麼熱的天,來碗清涼解暑的綠豆湯最合適不過了,既能消暑又能清熱解毒,給你帶來一絲涼爽!
---生成模式二: 創意模式(中温度+Top-p)---
這麼熱的天,來一碗清涼的綠豆湯最合適不過啦!既能解暑又能清熱解毒,讓你從內到外都感到清爽。試試看吧!
六、總結
綜合示例,通過調整“方向盤”上的參數,我們可以讓同一個AI模型表現出完全不同的性格:
- 做學問、搞翻譯:用束搜索或低温度+Top-p,讓它嚴謹可靠。
- 日常聊天、寫文案:用中温度+Top-p(如T=0.8, top_p=0.9),讓它既有創意又不失控。
- 寫詩、搞藝術創作:用高温度+Top-p(如T=1.2, top_p=0.9),讓它盡情發揮想象力。
通過這些實例,你可以直觀地感受到,通過調整這些“旋鈕”,我們能有效地控制AI模型的“性格”和輸出風格。