
一、必不可少

回憶我們日常的場景中,有時候我們使用百度或Google,要得到一個問題的答案,似乎來來回回換了很多次問法,才得到了我們期望的答案,或者到最後都沒有獲取預期的結果,這是為什麼呢?
這裏存在一個核心矛盾,我們的“問法”和知識庫的“存法”有着極大的差異,我們在提問過程中(Query)靈活、多變、口語化、不完整且沒有標明依賴背景,比如會問“電腦卡死了咋辦”、“LLM和AI有啥關係”等,知識庫的存法都是固定、規範、目錄、索引且自成體系的結構化內容,如果直接將兩者匹配,就像是用獨特的方言和普通話交流,對兩者來説都可能是晦澀難懂,不一定是完全失敗,但失敗的概率會非常大,尋求問題的答案,自然是需要追求更大的成功率,所以對請求提問(Query)的改寫是很有必要且必不可少的。
二、什麼是Query改寫
核心定義
Query 改寫是指在 RAG 系統的檢索階段之前,對用户輸入的原始查詢(Query)進行一系列處理、擴展或重構的技術,旨在生成一個或多個對檢索器(Retriever)更友好、更能匹配知識庫中相關文檔的“新查詢”。
主要工作
把我們的“原始查詢”,通過適合的方法加工翻譯成知識庫能聽懂、能高效執行的“改寫後的查詢”。
三、為什麼需要Query改寫
由於每個人的不同的思維都會有獨特的提問方式和術語,導致我們輸入的原始查詢會存在以下的一些偏差:
- 簡短模糊: “如何解決這個問題?” -> “這個問題”指代不明。
- 缺乏上下文: 在多輪對話中,用户可能説“那上一個方法呢?”,缺乏指代。
- 表述不專業: 用户使用口語化或錯誤術語,而知識庫使用規範術語。
- 信息缺失: 問題隱含了未明説的前提條件或意圖。
- 語義鴻溝: 用户的問法和文檔中的答法在表述上不一致。
如果直接將這樣的原始查詢扔給檢索器(如向量數據庫做相似性搜索),很可能檢索到不相關或次相關的文檔,導致後續的生成階段(Generator)產生“胡言亂語”或答非所問的情況。
因此,Query 改寫的終極目標是:提升檢索召回率(Recall)和精確率(Precision),為答案生成奠定高質量的上下文基礎。
四、Query不該寫會有什麼影響
如果不對 Query 做任何處理,直接扔給檢索器(比如向量數據庫做語義搜索),會出現一些問題:
1. 召回失敗(Recall Failure):根本找不到答案
問題:用户問:“蘋果股價咋樣了?”(用了口語“咋樣”和品牌“蘋果”)
答案:知識庫裏的文檔標題是:《Apple Inc. (AAPL) 2024年Q2財報與股價分析》。
偏差:雖然“蘋果”和“Apple”語義相似,但“咋樣”和“財報分析”的匹配度很低。檢索器可能無法將這篇最相關的文檔排到最前面,甚至完全找不到它。用户得到的結果是“未找到相關信息”或一個不相關的答案。
2. 精度失敗(Precision Failure):找到錯誤的答案
問題:用户問:“Python怎麼裝?”(想安裝Python語言環境)
答案:知識庫裏還有一篇文檔叫《如何在Python中安裝PyTorch包(Using Pip)》。
後果:檢索器發現“Python”和“安裝”這兩個詞都高度匹配,很可能將這篇關於“安裝包”的文檔錯誤地排在第一位。最終大模型根據這篇錯誤文檔,開始教用户如何使用pip install,完全答非所問。
3. 上下文低效(Ineffective Context):找到的文檔無法用於生成
問題:用户問:“總結一下Transformer的創新點。”
答案:知識庫裏最相關的是一篇50頁的論文《Attention Is All You Need》。
偏差:檢索器成功找對了文檔!但它把整整50頁的論文全部作為上下文扔給了大模型。最終大模型的輸入長度有限,可能被迫截斷後面的內容;同時,過多的無關信息也會干擾大模型的判斷,導致它無法生成一個精煉、準確的總結。
五、怎麼去做Query改寫
1. 補充細節:把模糊的話變具體。
- 如果問:“上次説的那個事?”(啥事?)
- 改寫為:“關於上週三會議上討論的預算增加方案。”(這下清楚了!)
2. 更換説法:把口語化的詞換成知識庫里正式的詞。
- 如果問:“電腦卡死了咋辦?”
- 改寫為:“計算機響應緩慢故障排除的解決方案”(術語對齊,一找一個準)
3. 多角度提問:怕一種問法搜不到,就換幾種方式都問問。
- 如果問:“這個 error 是啥意思?”
- 改寫後則會同時問:“這個錯誤代碼的含義”、“如何解決這個錯誤”、“這個錯誤的常見原因”(這樣搜到的答案更全面!)
4. 猜你想要啥:根據你的問題,直接“腦補”出一段答案,然後用這段答案去匹配相似的文檔。
- 如果問:“怎麼泡茶好喝?”
- 改寫會“腦補”出一段話:“要選擇好水,控制水温,綠茶80度,紅茶100度……”,然後用這段“腦補”的專業描述:去知識庫找,更容易找到《茶藝入門》這種專業文檔,而不是隻匹配“泡茶”、“好喝”這種詞。
通過Query改寫,檢索器能找到真正相關的文檔,大模型才能更準確的分析得出讓我們滿意的答案。
如果沒有這一步,就好比再厲害的廚師,用一堆錯誤的食材,也做不出好菜。所以,Query改寫是確保RAG系統聰明好用的第一步,也是至關重要的一步。
六、Query改寫的類型
以下改寫類型都是結合 qwen-turbo-latest模型的Query改寫演示:
1. 上下文依賴型
- 定義:用户的當前查詢嚴重依賴之前的對話歷史或未明説的上下文背景,孤立地看當前查詢則無法理解其真實意圖。
- 挑戰:檢索器看不到對話歷史,直接檢索會因信息缺失而失敗。
- 改寫策略:將關鍵的上下文信息顯式地融入當前查詢中,生成一個獨立、完整的查詢。
- 示例:對話歷史:
用户:介紹一下蘇軾。
AI:蘇軾,字子瞻,號東坡居士,北宋著名文學家...
用户:他的詞風呢?
原始查詢:他的詞風呢? (檢索器無法理解“他”指誰)
改寫後查詢:蘇軾的詞風特點是什麼?
代碼演示:
# Query改寫使用示例
# 導入依賴庫
import dashscope
import os
import json
# 從環境變量中獲取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基於 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改寫功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_context_dependent_query(self, current_query, conversation_history):
"""上下文依賴型Query改寫"""
instruction = """
你是一個智能的查詢優化助手。請分析用户的當前問題以及前序對話歷史,判斷當前問題是否依賴於上下文。
如果依賴,請將當前問題改寫成一個獨立的、包含所有必要上下文信息的完整問題。
如果不依賴,直接返回原問題。
"""
prompt = f"""
### 指令 ###
{instruction}
### 對話歷史 ###
{conversation_history}
### 當前問題 ###
{current_query}
### 改寫後的問題 ###
"""
return get_completion(prompt, self.model)
def main():
# 初始化Query改寫器
rewriter = QueryRewriter()
print("=== Query改寫功能使用示例(迪士尼主題樂園) ===\n")
# 示例1: 上下文依賴型Query
print("示例1: 上下文依賴型Query")
conversation_history = """
用户: "我想了解一下上海迪士尼樂園的最新項目。"
AI: "上海迪士尼樂園最新推出了'瘋狂動物城'主題園區,這裏有朱迪警官和尼克狐的互動體驗。"
用户: "這個園區有什麼遊樂設施?"
AI: "'瘋狂動物城'園區目前有瘋狂動物城警察局、朱迪警官訓練營和尼克狐的冰淇淋店等設施。"
"""
current_query = "還有其他設施嗎?"
print(f"對話歷史: {conversation_history}")
print(f"當前查詢: {current_query}")
result = rewriter.rewrite_context_dependent_query(current_query, conversation_history)
print(f"改寫結果: {result}\n")
if __name__ == "__main__":
main()
輸出結果:
=== Query改寫功能使用示例(迪士尼主題樂園) ===
示例1: 上下文依賴型Query
對話歷史:
用户: "我想了解一下上海迪士尼樂園的最新項目。"
AI: "上海迪士尼樂園最新推出了'瘋狂動物城'主題園區,這裏有朱迪警官和尼克狐的互動體驗。"
用户: "這個園區有什麼遊樂設施?"
AI: "'瘋狂動物城'園區目前有瘋狂動物城警察局、朱迪警官訓練營和尼克狐的冰淇淋店等設施。"
當前查詢: 還有其他設施嗎?
改寫結果: 除了瘋狂動物城警察局、朱迪警官訓練營和尼克狐的冰淇淋店之外,'瘋狂動物城'園區還有其他遊樂設施嗎?
2. 對比型
- 定義:用户意圖是對兩個或多個實體、概念進行對比、比較其異同或優劣。
- 挑戰:直接檢索可能只能找到分別描述單個實體的文檔,而找不到直接的對比資料。
- 改寫策略:在查詢中顯式添加“vs”、“與”、“區別”、“對比”、“優缺點”等比較性詞彙。
- 示例:
原始查詢:Transformer 和 RNN
改寫後查詢:Transformer 與 RNN 的區別和優缺點對比
代碼演示:
# Query改寫使用示例
# 導入依賴庫
import dashscope
import os
import json
# 從環境變量中獲取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基於 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改寫功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_comparative_query(self, query, context_info):
"""對比型Query改寫"""
instruction = """
你是一個查詢分析專家。請分析用户的輸入和相關的對話上下文,識別出問題中需要進行比較的多個對象。
然後,將原始問題改寫成一個更明確、更適合在知識庫中檢索的對比性查詢。
"""
prompt = f"""
### 指令 ###
{instruction}
### 對話歷史/上下文信息 ###
{context_info}
### 原始問題 ###
{query}
### 改寫後的查詢 ###
"""
return get_completion(prompt, self.model)
def main():
# 初始化Query改寫器
rewriter = QueryRewriter()
print("=== Query改寫功能使用示例(迪士尼主題樂園) ===\n")
# 示例2: 對比型Query
print("示例2: 對比型Query")
conversation_history = """
用户: "我想了解一下上海迪士尼樂園的最新項目。"
AI: "上海迪士尼樂園最新推出了瘋狂動物城主題園區,還有蜘蛛俠主題園區"
"""
current_query = "哪個遊玩的時間比較長,比較有趣"
print(f"對話歷史: {conversation_history}")
print(f"當前查詢: {current_query}")
result = rewriter.rewrite_comparative_query(current_query, conversation_history)
print(f"改寫結果: {result}\n")
if __name__ == "__main__":
main()
輸出結果:
=== Query改寫功能使用示例(迪士尼主題樂園) ===
示例2: 對比型Query
對話歷史:
用户: "我想了解一下上海迪士尼樂園的最新項目。"
AI: "上海迪士尼樂園最新推出了瘋狂動物城主題園區,還有蜘蛛俠主題園區"
當前查詢: 哪個遊玩的時間比較長,比較有趣
改寫結果: 哪個遊玩時間更長、更有趣:上海迪士尼樂園的瘋狂動物城主題園區和蜘蛛俠主題園區?
3. 模糊指代型
- 定義:查詢中使用了一些代詞(這個、那個)、口語化詞彙或省略語,導致所指不明。
- 挑戰:知識庫中的文檔使用明確、規範的語言,無法匹配模糊的指代。
- 改寫策略:根據對話歷史或常識,將模糊指代替換為具體的實體名稱或規範術語。
- 示例:
原始查詢:你們那個新品什麼時候上線? (“那個新品”指代不明)
改寫後查詢:智能手錶產品 Galaxy Watch 7 的預計上市發佈時間
代碼演示:
# Query改寫使用示例
# 導入依賴庫
import dashscope
import os
import json
# 從環境變量中獲取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基於 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改寫功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_ambiguous_reference_query(self, current_query, conversation_history):
"""模糊指代型Query改寫"""
instruction = """
你是一個消除語言歧義的專家。請分析用户的當前問題和對話歷史,找出問題中 "都"、"它"、"這個" 等模糊指代詞具體指向的對象。
然後,將這些指代詞替換為明確的對象名稱,生成一個清晰、無歧義的新問題。
"""
prompt = f"""
### 指令 ###
{instruction}
### 對話歷史 ###
{conversation_history}
### 當前問題 ###
{current_query}
### 改寫後的問題 ###
"""
return get_completion(prompt, self.model)
def main():
# 初始化Query改寫器
rewriter = QueryRewriter()
print("=== Query改寫功能使用示例(迪士尼主題樂園) ===\n")
# 示例3: 模糊指代型Query
print("示例3: 模糊指代型Query")
conversation_history = """
用户: "我想了解一下上海迪士尼樂園和香港迪士尼樂園的煙花表演。"
AI: "好的,上海迪士尼樂園和香港迪士尼樂園都有精彩的煙花表演。"
"""
current_query = "都什麼時候開始?"
print(f"對話歷史: {conversation_history}")
print(f"當前查詢: {current_query}")
result = rewriter.rewrite_ambiguous_reference_query(current_query, conversation_history)
print(f"改寫結果: {result}\n")
if __name__ == "__main__":
main()
輸出結果:
=== Query改寫功能使用示例(迪士尼主題樂園) ===
示例3: 模糊指代型Query
對話歷史:
用户: "我想了解一下上海迪士尼樂園和香港迪士尼樂園的煙花表演。"
AI: "好的,上海迪士尼樂園和香港迪士尼樂園都有精彩的煙花表演。"
當前查詢: 都什麼時候開始?
改寫結果: 上海迪士尼樂園和香港迪士尼樂園的煙花表演都什麼時候開始?
4. 多意圖型
- 定義:一個查詢中包含了多個獨立的問題或意圖。回答它需要從知識庫中多個不同部分檢索信息。
- 挑戰:單一查詢檢索,可能只能匹配到其中一個意圖的文檔,導致回答不全。
- 改寫策略:將複合查詢分解成多個原子性的子查詢,分別進行檢索,最後再整合答案。
- 示例:
原始查詢:請介紹公司的創始人背景以及目前的主要產品線。
改寫後查詢:
[公司名稱] 創始人 背景 經歷
[公司名稱] 當前 主要產品線 有哪些
代碼演示:
# Query改寫使用示例
# 導入依賴庫
import dashscope
import os
import json
# 從環境變量中獲取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基於 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改寫功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_multi_intent_query(self, query):
"""多意圖型Query改寫 - 分解查詢"""
instruction = """
你是一個任務分解機器人。請將用户的複雜問題分解成多個獨立的、可以單獨回答的簡單問題。以JSON數組格式輸出。
"""
prompt = f"""
### 指令 ###
{instruction}
### 原始問題 ###
{query}
### 分解後的問題列表 ###
請以JSON數組格式輸出,例如:["問題1", "問題2", "問題3"]
"""
response = get_completion(prompt, self.model)
try:
return json.loads(response)
except:
return [response]
def main():
# 初始化Query改寫器
rewriter = QueryRewriter()
print("=== Query改寫功能使用示例(迪士尼主題樂園) ===\n")
# 示例4: 多意圖型Query
print("示例4: 多意圖型Query")
query = "門票多少錢?需要提前預約嗎?停車費怎麼收?"
print(f"原始查詢: {query}")
result = rewriter.rewrite_multi_intent_query(query)
print(f"分解結果: {result}\n")
if __name__ == "__main__":
main()
輸出結果:
=== Query改寫功能使用示例(迪士尼主題樂園) ===
示例4: 多意圖型Query
原始查詢: 門票多少錢?需要提前預約嗎?停車費怎麼收?
分解結果: ['門票多少錢?', '需要提前預約嗎?', '停車費怎麼收?']
5. 反問型
- 定義:用户以反問或否定句的形式提出問題,但其真實意圖是肯定性的。
- 挑戰:檢索器可能被反問的語氣或否定詞誤導,去檢索“為什麼不”的原因,而不是如何做。
- 改寫策略:識別出反問句背後的真實肯定性意圖,並將其轉換為中性的、正向的查詢。
- 示例:
原始查詢:難道就沒有更快的方法了嗎? (情緒化、否定)
改寫後查詢:提高 [某項任務] 執行速度的優化方法或高效技巧
代碼演示:
# Query改寫使用示例
# 導入依賴庫
import dashscope
import os
import json
# 從環境變量中獲取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基於 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改寫功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_rhetorical_query(self, current_query, conversation_history):
"""反問型Query改寫"""
instruction = """
你是一個溝通理解大師。請分析用户的反問或帶有情緒的陳述,識別其背後真實的意圖和問題。
然後,將這個反問改寫成一箇中立、客觀、可以直接用於知識庫檢索的問題。
"""
prompt = f"""
### 指令 ###
{instruction}
### 對話歷史 ###
{conversation_history}
### 當前問題 ###
{current_query}
### 改寫後的問題 ###
"""
return get_completion(prompt, self.model)
def main():
# 初始化Query改寫器
rewriter = QueryRewriter()
print("=== Query改寫功能使用示例(迪士尼主題樂園) ===\n")
# 示例5: 反問型Query
print("示例5: 反問型Query")
conversation_history = """
用户: "你好,我想預訂下週六上海迪士尼樂園的門票。"
AI: "正在為您查詢... 查詢到下週六的門票已經售罄。"
用户: "售罄是什麼意思?我朋友上週去還能買到當天的票。"
"""
current_query = "這不會也要提前一個月預訂吧?"
print(f"對話歷史: {conversation_history}")
print(f"當前查詢: {current_query}")
result = rewriter.rewrite_rhetorical_query(current_query, conversation_history)
print(f"改寫結果: {result}\n")
if __name__ == "__main__":
main()
輸出結果:
=== Query改寫功能使用示例(迪士尼主題樂園) ===
示例5: 反問型Query
對話歷史:
用户: "你好,我想預訂下週六上海迪士尼樂園的門票。"
AI: "正在為您查詢... 查詢到下週六的門票已經售罄。"
用户: "售罄是什麼意思?我朋友上週去還能買到當天的票。"
當前查詢: 這不會也要提前一個月預訂吧?
改寫結果: 迪士尼樂園門票是否需要提前一個月預訂?
6. 總結
|
類型 |
核心特徵 |
改寫策略 |
|
上下文依賴型 |
依賴歷史對話
|
補全上下文 |
|
對比型 |
比較兩個事物 |
添加比較詞
|
|
模糊指代型 |
使用代詞、口語 |
替換為具體術語
|
|
多意圖型 |
一個問題多部分 |
分解為子查詢 |
|
反問型 |
否定、反問語氣 |
轉為正向意圖 |
七、Query意圖識別
- 定義:它指的是系統需要先理解用户查詢的深層目的(是問定義、查步驟、要對比,還是故障排查)。
- 挑戰:不同的意圖需要不同的改寫策略和檢索優化(如添加過濾器)。
- 改寫策略:首先對查詢進行意圖分類,然後根據分類結果應用特定的改寫模板或策略。
- 示例1:
原始查詢:Python list comprehension
意圖識別:詢問定義
改寫策略:添加“是什麼”、“介紹”、“概念”等詞。
改寫後查詢:Python list comprehension 的概念是什麼?
- 示例2:
原始查詢:如何用 Python list comprehension 過濾數據?
意圖識別:詢問操作方法
改寫策略:添加“步驟”、“方法”、“示例”等詞。
改寫後查詢:使用 Python list comprehension 過濾數據的步驟與示例
下圖描繪了結合 qwen-turbo-latest 模型的Query改寫智能決策流程:
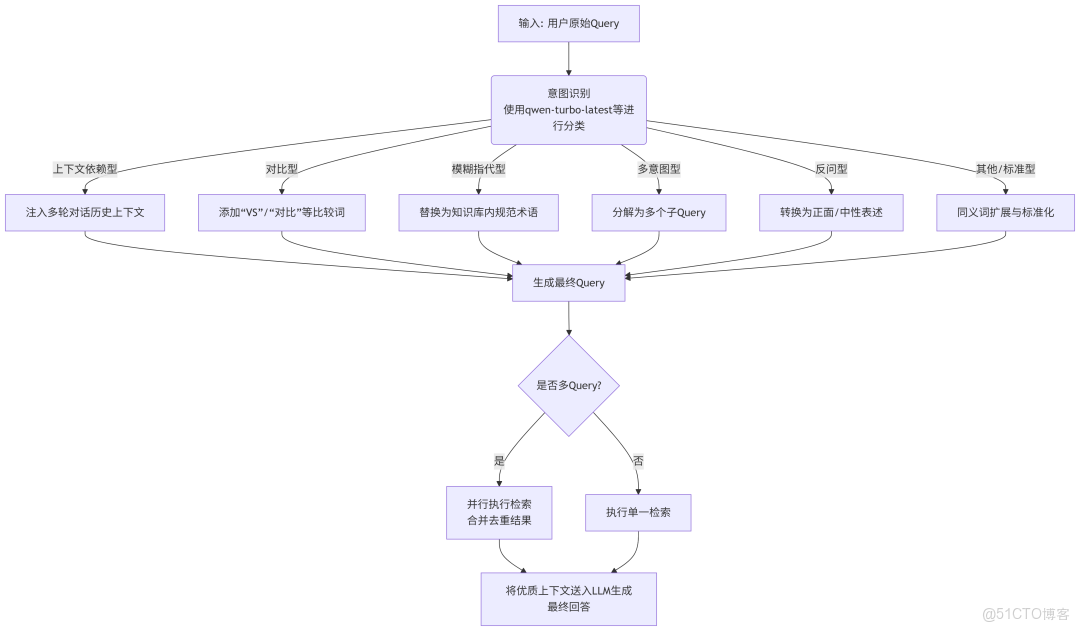
流程解讀:
1. 入口:流程始於接收用户的原始Query。
2. 核心決策點(意圖識別):首先使用 qwen-turbo-latest 等模型對Query進行意圖分類。這是整個流程的“大腦”,決定了後續的改寫策略。常見的意圖類別包括:定義、操作、對比、故障排除等。
3. 策略分支:根據識別出的意圖,進入不同的專用處理通道:
- 上下文依賴型:會查詢對話歷史,將缺失的上下文補全到當前Query中。
- 對比型:會顯式地在Query中添加比較詞彙。
- 模糊指代型:會調用一個術語表或另一個LLM調用,將模糊指代具體化。
- 多意圖型:會被分解成多個獨立的子Query,這是最關鍵的一步。
- 反問型:會進行“否定轉肯定”的語義轉換。
- 標準型:對於沒有特殊意圖的查詢,進行基礎的擴展和規範化。
4. 生成與檢索:所有分支最終匯合,生成最終的一個或多個優化後的Query,送入檢索器。
- 如果是多Query(如多意圖型分解後),則會並行執行檢索,並將結果合併、去重、重排,得到最全面的上下文。
- 如果是單一Query,則直接執行檢索。
5. 出口:將檢索到的優質上下文文檔與原始Query一起,送給LLM(如 qwen-turbo-latest )生成最終準確、可靠的回答。
這個流程圖展示了一個成熟RAG系統處理Query的完整邏輯鏈,其中意圖識別是觸發不同改寫策略的開關,而 specialized 的改寫策略是精準命中知識庫內容的關鍵。
代碼演示:
# Query改寫使用示例
# 導入依賴庫
import dashscope
import os
import json
# 從環境變量中獲取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基於 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改寫功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def auto_rewrite_query(self, query, conversation_history="", context_info=""):
"""自動識別Query類型並進行改寫"""
instruction = """
你是一個智能的查詢分析專家。請分析用户的查詢,識別其屬於以下哪種類型:
1. 上下文依賴型 - 包含"還有"、"其他"等需要上下文理解的詞彙
2. 對比型 - 包含"哪個"、"比較"、"更"、"哪個更好"、"哪個更"等比較詞彙
3. 模糊指代型 - 包含"它"、"他們"、"都"、"這個"等指代詞
4. 多意圖型 - 包含多個獨立問題,用"、"或"?"分隔
5. 反問型 - 包含"不會"、"難道"等反問語氣
説明:如果同時存在多意圖型、模糊指代型,優先級為多意圖型>模糊指代型
請返回JSON格式的結果:
{
"query_type": "查詢類型",
"rewritten_query": "改寫後的查詢",
"confidence": "置信度(0-1)"
}
"""
prompt = f"""
### 指令 ###
{instruction}
### 對話歷史 ###
{conversation_history}
### 上下文信息 ###
{context_info}
### 原始查詢 ###
{query}
### 分析結果 ###
"""
response = get_completion(prompt, self.model)
try:
return json.loads(response)
except:
return {
"query_type": "未知類型",
"rewritten_query": query,
"confidence": 0.5
}
def main():
# 初始化Query改寫器
rewriter = QueryRewriter()
print("=== Query改寫功能使用示例(迪士尼主題樂園) ===\n")
# 示例6: 自動識別Query類型
print("示例6: 自動識別Query類型")
test_queries = [
"還有其他遊樂項目嗎?",
"哪個園區更好玩?",
"都適合小朋友嗎?",
"有什麼餐廳?價格怎麼樣?",
"這不會也要排隊兩小時吧?"
]
for i, query in enumerate(test_queries, 1):
print(f"測試查詢 {i}: {query}")
result = rewriter.auto_rewrite_query(query)
print(f" 識別類型: {result['query_type']}")
print(f" 改寫結果: {result['rewritten_query']}")
print(f" 置信度: {result['confidence']}\n")
if __name__ == "__main__":
main()
輸出結果:
=== Query改寫功能使用示例(迪士尼主題樂園) ===
示例6: 自動識別Query類型
測試查詢 1: 還有其他遊樂項目嗎?
識別類型: 上下文依賴型
改寫結果: 除了已知的遊樂項目外,還有哪些其他遊樂項目?
置信度: 0.95
測試查詢 2: 哪個園區更好玩?
識別類型: 對比型
改寫結果: 請比較各個園區的娛樂性,指出哪個更好玩。
置信度: 0.95
測試查詢 3: 都適合小朋友嗎?
識別類型: 模糊指代型
改寫結果: 哪些產品或活動適合小朋友?
置信度: 0.95
測試查詢 4: 有什麼餐廳?價格怎麼樣?
識別類型: 多意圖型
改寫結果: 有哪些餐廳?這些餐廳的價格怎麼樣?
置信度: 0.95
測試查詢 5: 這不會也要排隊兩小時吧?
識別類型: 反問型
改寫結果: 這需要排隊兩小時嗎?
置信度: 0.95
八、總結
因為用户的自然提問方式與知識庫的客觀組織方式天生存在不可調和的差異。如果不進行改寫,直接將原始查詢用於檢索,就如同讓一個不懂檢索的人自己去漫無目的地查字典,結果往往是找不到、找錯了或找到的沒法用。
Query 改寫是保障 RAG 系統可靠性、準確性和可用性的“第一道防線”和“核心基礎設施”。它通過一系列技術手段,將用户的意圖“翻譯”成檢索器能高效理解的語言,從而確保後續步驟能在一個高質量的基礎上進行。沒有它,再強大的大模型也只會是“巧婦難為無米之炊”,甚至“做出一鍋壞飯”。
