
前面幾篇文章已經深入討論過LangChain、RAG架構的細節,對RAG有了基礎的瞭解,今天重點梳理一下RAG的切片策略;
一、什麼是RAG切片
給定一個場景,我們有一本非常厚的百科全書(就像公司的員工手冊文檔或公司知識庫)。同時,我們有一個超級聰明的AI助手,他知識淵博,但有個弊端,他一次只能看一頁紙,而且給他哪一頁,他才能看哪一頁。他做不到直接從整本厚厚的書裏去尋找答案。
RAG 的切片策略,就是幫我們把這本厚厚的書,提前拆分成一頁一頁、或者一段一段的“小紙片”,並給這些小紙片做好詳細的“目錄”和“標籤”,做成一個高效的“索引”或者“目錄”,當AI助手需要回答問題時,它不需要去翻整本書,而是先快速查閲“目錄”,找到最相關的那麼幾張小紙片(比如第45頁的“考勤制度”和第46頁的“福利政策”),然後你只把這幾張紙遞給它。AI助手看着這幾張紙上的內容,就能給你一個非常精準的答案。不同的切片策略,就是做“目錄”的不同方法。
- 所以,到底什麼是RAG切片?
RAG切片就是把一份長長的文檔(如PDF、Word),合理地切割成一個個小塊(Chunks)的過程。這個過程是整個RAG系統的基石,它直接決定了後續檢索和生成答案的質量。
二、是必須要切片嗎
是的,由於以下原因,切片是勢必要進行的過程:
- AI的“記憶力”有限:由於上下文窗口限制,AI一次只能看有限的內容,比如幾千個字。如果不切片,整本書塞給它,它根本處理不了。
- 精準檢索的需要:如果不進行切片,整本書就是一個巨大的整體。當你要搜索“年假”時,搜索引擎無法知道具體內容在書的哪一部分,很可能返回無關信息。切片後,搜索引擎可以精準地定位到包含“年假”關鍵詞的那些小塊。
三、幾種切片策略
1. 改進的固定長度切片
1.1 詳細説明
這種方法在簡單固定長度切片的基礎上,增加了對語義完整性的基本保留。
- 核心思想:依然預設一個目標長度,但切割點不再是一個簡單的字符索引,而是尋找最接近目標長度的自然語言邊界(如句號、問號、換行符等),從而避免在句子中間切斷。
- 工作流程:
- 將文本按段落或雙換行符等主要分隔符進行初步分割。
- 對於每個初步分割出的段,如果其長度遠超目標 chunk_size,則再使用句子級別的分隔符('. ', '? ', '! ')進行二次分割。
- 確保每個最終的塊大小接近 chunk_size,且起始和結束都在完整的句子邊界上。
- 優點:在保持計算高效的同時,顯著減少了切碎句子的情況,比樸素固定切片效果好很多。
- 缺點:仍然無法處理複雜的語義單元(如一個表格、一個代碼塊、一個多句子的論點)。
- 適用場景:通用文本,是簡單固定切片和複雜語義切片之間的一個良好折衷方案。
1.2 演示示例
"""
固定長度切片策略
在句子邊界進行切分,避免切斷句子
"""
def improved_fixed_length_chunking(text, chunk_size=512, overlap=50):
"""改進的固定長度切片 - 在句子邊界切分"""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
# 嘗試在句子邊界切分
if end < len(text):
# 尋找最近的句子結束符
for i in range(end, max(start, end - 100), -1):
if text[i] in '.!?。!?':
end = i + 1
break
chunk = text[start:end]
if len(chunk.strip()) > 0:
chunks.append(chunk.strip())
start = end - overlap
return chunks
def print_chunk_analysis(chunks, method_name):
"""打印切片分析結果"""
print(f"\n{'='*60}")
print(f"📋 {method_name}")
print(f"{'='*60}")
if not chunks:
print("❌ 未生成任何切片")
return
total_length = sum(len(chunk) for chunk in chunks)
avg_length = total_length / len(chunks)
min_length = min(len(chunk) for chunk in chunks)
max_length = max(len(chunk) for chunk in chunks)
print(f"📊 統計信息:")
print(f" - 切片數量: {len(chunks)}")
print(f" - 平均長度: {avg_length:.1f} 字符")
print(f" - 最短長度: {min_length} 字符")
print(f" - 最長長度: {max_length} 字符")
print(f" - 長度方差: {max_length - min_length} 字符")
print(f"\n📝 切片內容:")
for i, chunk in enumerate(chunks, 1):
print(f" 塊 {i} ({len(chunk)} 字符):")
print(f" {chunk}")
print()
# 測試文本
text = """
迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動。兩日票需要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標註的有效期限。
購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。第三方平台如飛豬、攜程等合作代理商也可購票,但需認準官方授權標識。所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。
生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。軍人優惠現役及退役軍人憑證件享8折,需至少提前3天登記審批。
"""
if __name__ == "__main__":
print("🎯 固定長度切片策略測試")
print(f"📄 測試文本長度: {len(text)} 字符")
# 使用改進的固定長度切片
chunks = improved_fixed_length_chunking(text, chunk_size=300, overlap=50)
print_chunk_analysis(chunks, "固定長度切片")
輸出結果:
🎯 固定長度切片策略測試
📄 測試文本長度: 324 字符
============================================================
📋 固定長度切片
============================================================
📊 統計信息:
- 切片數量: 2
- 平均長度: 186.0 字符
- 最短長度: 80 字符
- 最長長度: 292 字符
- 長度方差: 212 字符
📝 切片內容:
塊 1 (292 字符):
迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動。兩日
票需要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標註的有效期限。
購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。第三方平台如飛豬、攜程等合作代理商也可購票,但需
認準官方授權標識。所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。
生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。
塊 2 (80 字符):
需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。軍人優惠現役及退役
軍人憑證件享8折,需至少提前3天登記審批。
2. 語義切片
2.1 詳細説明
這種方法基於內容本身的含義進行切割,是內容感知的。
- 核心思想:通過計算句子或段落之間的語義相似度來識別主題的轉折點。當相鄰文本單元的嵌入向量相似度突然變低時,就在那裏進行切割。
- 工作流程:
- 將文本分割成更小的單元(如句子)。
- 為每個句子生成嵌入向量(Embedding)。
- 計算相鄰句子之間的餘弦相似度,形成一個相似度序列。
- 識別相似度序列中的“谷底”(即相似度顯著下降的點),這些點就是潛在的主題轉換邊界。
- 在這些邊界點進行切割,並將相似度高的相鄰句子組合成一個塊。
- 優點:能產生語義上高度連貫的塊,檢索精度最高。
- 缺點:計算成本非常高,需要對大量句子進行嵌入計算和相似度比較,速度慢。
- 適用場景:對答案准確性和相關性要求極高的場景,如法律條款分析、學術文獻綜述、高端知識庫問答。
2.2 演示示例
"""
語義切片策略
基於句子邊界進行切分,保持語義完整性
"""
import re
def semantic_chunking(text, max_chunk_size=512):
"""基於語義的切片 - 按句子分割"""
# 使用正則表達式分割句子
sentences = re.split(r'[.!?。!?\n]+', text)
chunks = []
current_chunk = ""
for sentence in sentences:
sentence = sentence.strip()
if not sentence:
continue
# 如果當前句子加入後超過最大長度,保存當前塊
if len(current_chunk) + len(sentence) > max_chunk_size and current_chunk:
chunks.append(current_chunk.strip())
current_chunk = sentence
else:
current_chunk += " " + sentence if current_chunk else sentence
# 添加最後一個塊
if current_chunk.strip():
chunks.append(current_chunk.strip())
return chunks
def print_chunk_analysis(chunks, method_name):
"""打印切片分析結果"""
print(f"\n{'='*60}")
print(f"📋 {method_name}")
print(f"{'='*60}")
if not chunks:
print("❌ 未生成任何切片")
return
total_length = sum(len(chunk) for chunk in chunks)
avg_length = total_length / len(chunks)
min_length = min(len(chunk) for chunk in chunks)
max_length = max(len(chunk) for chunk in chunks)
print(f"📊 統計信息:")
print(f" - 切片數量: {len(chunks)}")
print(f" - 平均長度: {avg_length:.1f} 字符")
print(f" - 最短長度: {min_length} 字符")
print(f" - 最長長度: {max_length} 字符")
print(f" - 長度方差: {max_length - min_length} 字符")
print(f"\n📝 切片內容:")
for i, chunk in enumerate(chunks, 1):
print(f" 塊 {i} ({len(chunk)} 字符):")
print(f" {chunk}")
print()
# 測試文本
text = """
迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動。兩日票需要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標註的有效期限。
購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。第三方平台如飛豬、攜程等合作代理商也可購票,但需認準官方授權標識。所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。
生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。軍人優惠現役及退役軍人憑證件享8折,需至少提前3天登記審批。
"""
if __name__ == "__main__":
print("🎯 語義切片策略測試")
print(f"📄 測試文本長度: {len(text)} 字符")
# 使用語義切片
chunks = semantic_chunking(text, max_chunk_size=300)
print_chunk_analysis(chunks, "語義切片")
輸出結果:
語義切片策略測試
📄 測試文本長度: 324 字符
============================================================
📋 語義切片
============================================================
📊 統計信息:
- 切片數量: 2
- 平均長度: 158.0 字符
- 最短長度: 29 字符
- 最長長度: 287 字符
- 長度方差: 258 字符
📝 切片內容:
塊 1 (287 字符):
迪士尼樂園提供多種門票類型以滿足不同遊客需求 一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動 兩日票
需要連續兩天使用,總價比購買兩天單日票優惠約9折 特定日票包含部分節慶活動時段,需注意門票標註的有效期限 購票渠道以官方渠道
為主,包括上海迪士尼官網、官方App、微信公眾號及小程序 第三方平台如飛豬、攜程等合作代理商也可購票,但需認準官方授權標識 所
有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件 生日福利需在官方渠道登記
,可獲贈生日徽章和甜品券 半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐
塊 2 (29 字符):
軍人優惠現役及退役軍人憑證件享8折,需至少提前3天登記審批
3. LLM語義切片
3.1 詳細説明
這是語義切片的一種強化版,使用更強大的LLM來理解和識別最優切割點。
- 核心思想: prompting LLM來分析和判斷文本的最佳分割邊界。LLM可以理解更復雜的語義結構,如“論點結束”、“例子開始”、“結論部分”等。
- 工作流程:
- 將文本初步分成較大的段。
- 對於每個大段,構造Prompt讓LLM判斷:“如果我要將以下文本切成塊,用於問答系統,最佳切割點在哪裏?”或者“以下文本包含幾個獨立的觀點?”。
- 解析LLM的輸出(可能是標記後的文本或JSON),根據其指示進行切割。
- 優點:最智能、最準確,能理解最複雜的語義和邏輯結構。
- 缺點:成本極高,速度極慢,不適合大規模文檔處理,更偏向於研究性或對質量有極端要求的場景。
- 適用場景:處理高度複雜、結構非正式的文本(如哲學著作、長篇評論、創意寫作)。
3.2 演示示例
from openai import OpenAI
import json
import os
import re
def advanced_semantic_chunking_with_llm(text, max_chunk_size=512):
"""使用LLM進行高級語義切片"""
# 檢查環境變量
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
print("警告: 未設置 DASHSCOPE_API_KEY 環境變量,將使用基礎語義切片")
return fallback_semantic_chunking(text, max_chunk_size)
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
prompt = f"""
請將以下文本按照語義完整性進行切片,每個切片不超過{max_chunk_size}字符。
要求:
1. 保持語義完整性
2. 在自然的分割點切分
3. 返回JSON格式的切片列表,格式如下:
{{
"chunks": [
"第一個切片內容",
"第二個切片內容",
...
]
}}
文本內容:
{text}
請返回JSON格式的切片列表:
"""
try:
print("正在調用LLM進行語義切片...")
response = client.chat.completions.create(
model="qwen-turbo-latest",
messages=[
{"role": "system", "content": "你是一個專業的文本切片助手。請嚴格按照JSON格式返回結果,不要添加任何額外的標記。"},
{"role": "user", "content": prompt}
]
)
result = response.choices[0].message.content
print(f"LLM返回結果: {result[:800]}...")
# 清理結果,移除可能的Markdown代碼塊標記
cleaned_result = result.strip()
if cleaned_result.startswith('```'):
# 移除開頭的 ```json 或 ```
cleaned_result = re.sub(r'^```(?:json)?\s*', '', cleaned_result)
if cleaned_result.endswith('```'):
# 移除結尾的 ```
cleaned_result = re.sub(r'\s*```$', '', cleaned_result)
# 解析JSON結果
chunks_data = json.loads(cleaned_result)
# 處理不同的返回格式
if "chunks" in chunks_data:
return chunks_data["chunks"]
elif "slice" in chunks_data:
# 如果返回的是包含"slice"字段的列表
if isinstance(chunks_data, list):
return [item.get("slice", "") for item in chunks_data if item.get("slice")]
else:
return [chunks_data["slice"]]
else:
# 如果直接返回字符串列表
if isinstance(chunks_data, list):
return chunks_data
else:
print(f"意外的返回格式: {chunks_data}")
return []
except json.JSONDecodeError as e:
print(f"JSON解析失敗: {e}")
print(f"原始結果: {result}")
# 嘗試手動解析
try:
# 嘗試提取JSON部分
json_match = re.search(r'\{.*\}', result, re.DOTALL)
if json_match:
json_str = json_match.group()
chunks_data = json.loads(json_str)
if "chunks" in chunks_data:
return chunks_data["chunks"]
except:
pass
except Exception as e:
print(f"LLM切片失敗: {e}")
def test_chunking_methods():
"""測試不同的切片方法"""
# 示例文本
text = """
迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動。兩日票需要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標註的有效期限。
購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。第三方平台如飛豬、攜程等合作代理商也可購票,但需認準官方授權標識。所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。
生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。軍人優惠現役及退役軍人憑證件享8折,需至少提前3天登記審批。
"""
print("\n=== LLM高級語義切片測試 ===")
try:
chunks = advanced_semantic_chunking_with_llm(text, max_chunk_size=300)
print(f"LLM高級語義切片生成 {len(chunks)} 個切片:")
for i, chunk in enumerate(chunks):
print(f"LLM語義塊 {i+1} (長度: {len(chunk)}): {chunk}")
except Exception as e:
print(f"LLM切片測試失敗: {e}")
if __name__ == "__main__":
test_chunking_methods()
輸出結果:
=== LLM高級語義切片測試 ===
正在調用LLM進行語義切片...
LLM返回結果: {
"chunks": [
"迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動。",
"兩日票需要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標註的有效期限。",
"購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。第三方平台如飛豬、攜程等合作代理商也可購票,
但需認準官方授權標識。",
"所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。",
"生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。",
"軍人優惠現役及退役軍人憑證件享8折,需至少提前3天登記審批。"
]
}...
LLM高級語義切片生成 6 個切片:
LLM語義塊 1 (長度: 57): 迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價
格根據季節浮動。
LLM語義塊 2 (長度: 56): 兩日票需要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標
注的有效期限。
LLM語義塊 3 (長度: 71): 購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。第三方平台如飛豬、攜程等
合作代理商也可購票,但需認準官方授權標識。
LLM語義塊 4 (長度: 50): 所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件
。
LLM語義塊 5 (長度: 54): 生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會
廳雙人餐。
LLM語義塊 6 (長度: 30): 軍人優惠現役及退役軍人憑證件享8折,需至少提前3天登記審批。
4. 層次切片
4.1 詳細説明
這種方法不再產生扁平的塊,而是構建一個層次化的索引結構。
- 核心思想:創建不同粒度級別的塊。例如,小粒度的句子級塊(用於精準檢索)和中粒度的段落級塊(用於提供上下文)。
- 工作流程:
- 第一層(粗粒度):將文檔按章節或大標題分割。
- 第二層(中粒度):將每個章節按段落分割。
- 第三層(細粒度):將每個段落按句子或小標題分割。
- 檢索時,可以先檢索最細粒度的塊以找到最相關的信息,然後將其父級(中粒度)的塊作為上下文一起發送給LLM。
- 優點:兼顧了檢索的精度和上下文的完整性,效果好。
- 缺點:索引結構更復雜,需要存儲父子關係,檢索邏輯也更復雜(例如使用ParentDocumentRetriever)。
- 適用場景:長文檔(書籍、手冊、論文),其中既需要找到具體細節,又需要理解周圍的上下文。
4.2 演示示例
"""
層次切片策略
基於文檔結構層次進行切片
"""
def hierarchical_chunking(text, target_size=512, preserve_hierarchy=True):
"""層次切片 - 基於文檔結構層次進行切片"""
chunks = []
# 定義層次標記
hierarchy_markers = {
'title1': ['# ', '標題1:', '一、', '1. '],
'title2': ['## ', '標題2:', '二、', '2. '],
'title3': ['### ', '標題3:', '三、', '3. '],
'paragraph': ['\n\n', '\n']
}
# 分割文本為行
lines = text.split('\n')
current_chunk = ""
current_hierarchy = []
for line in lines:
line = line.strip()
if not line:
continue
# 檢測當前行的層次級別
line_level = None
for level, markers in hierarchy_markers.items():
for marker in markers:
if line.startswith(marker):
line_level = level
break
if line_level:
break
# 如果沒有檢測到層次標記,默認為段落
if not line_level:
line_level = 'paragraph'
# 判斷是否需要開始新的切片
should_start_new_chunk = False
# 1. 如果遇到更高級別的標題,開始新切片
if preserve_hierarchy and line_level in ['title1', 'title2']:
should_start_new_chunk = True
# 2. 如果當前切片長度超過目標大小
if len(current_chunk) + len(line) > target_size and current_chunk.strip():
should_start_new_chunk = True
# 3. 如果遇到段落分隔符且當前切片已經足夠長
if line_level == 'paragraph' and len(current_chunk) > target_size * 0.8:
should_start_new_chunk = True
# 開始新切片
if should_start_new_chunk and current_chunk.strip():
chunks.append(current_chunk.strip())
current_chunk = ""
current_hierarchy = []
# 添加當前行到切片
if current_chunk:
current_chunk += "\n" + line
else:
current_chunk = line
# 更新層次信息
if line_level != 'paragraph':
current_hierarchy.append(line_level)
# 處理最後一個切片
if current_chunk.strip():
chunks.append(current_chunk.strip())
return chunks
def print_chunk_analysis(chunks, method_name):
"""打印切片分析結果"""
print(f"\n{'='*60}")
print(f"📋 {method_name}")
print(f"{'='*60}")
if not chunks:
print("❌ 未生成任何切片")
return
total_length = sum(len(chunk) for chunk in chunks)
avg_length = total_length / len(chunks)
min_length = min(len(chunk) for chunk in chunks)
max_length = max(len(chunk) for chunk in chunks)
print(f"📊 統計信息:")
print(f" - 切片數量: {len(chunks)}")
print(f" - 平均長度: {avg_length:.1f} 字符")
print(f" - 最短長度: {min_length} 字符")
print(f" - 最長長度: {max_length} 字符")
print(f" - 長度方差: {max_length - min_length} 字符")
print(f"\n📝 切片內容:")
for i, chunk in enumerate(chunks, 1):
print(f" 塊 {i} ({len(chunk)} 字符):")
print(f" {chunk}")
print()
# 測試文本 - 包含層次結構
text = """
# 迪士尼樂園門票指南
## 一、門票類型介紹
### 1. 基礎門票類型
迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動。兩日票需要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標註的有效期限。
### 2. 特殊門票類型
年票適合經常遊玩的遊客,提供更多優惠和特權。VIP門票包含快速通道服務,可減少排隊時間。團體票適用於10人以上團隊,享受團體折扣。
## 二、購票渠道與流程
### 1. 官方購票渠道
購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。這些渠道提供最可靠的服務和最新的票務信息。
### 2. 第三方平台
第三方平台如飛豬、攜程等合作代理商也可購票,但需認準官方授權標識。建議優先選擇官方渠道以確保購票安全。
### 3. 證件要求
所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。
## 三、入園須知
### 1. 入園時間
樂園通常在上午8:00開園,晚上8:00閉園,具體時間可能因季節和特殊活動調整。建議提前30分鐘到達園區。
### 2. 安全檢查
入園前需要進行安全檢查,禁止攜帶危險物品、玻璃製品等。建議輕裝簡行,提高入園效率。
### 3. 園區服務
園區內提供寄存服務、輪椅租賃、嬰兒車租賃等服務,可在遊客服務中心諮詢詳情。
生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。軍人優惠現役及退役軍人憑證件享8折,需至少提前3天登記審批。
"""
if __name__ == "__main__":
print("🎯 層次切片策略測試")
print(f"📄 測試文本長度: {len(text)} 字符")
# 使用層次切片
chunks = hierarchical_chunking(text, target_size=300, preserve_hierarchy=True)
print_chunk_analysis(chunks, "層次切片")
輸出結果:
🎯 層次切片策略測試
📄 測試文本長度: 725 字符
============================================================
📋 層次切片
============================================================
📊 統計信息:
- 切片數量: 4
- 平均長度: 177.0 字符
- 最短長度: 11 字符
- 最長長度: 264 字符
- 長度方差: 253 字符
📝 切片內容:
塊 1 (11 字符):
# 迪士尼樂園門票指南
塊 2 (219 字符):
## 一、門票類型介紹
### 1. 基礎門票類型
迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動。兩日票需
要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標註的有效期限。
### 2. 特殊門票類型
年票適合經常遊玩的遊客,提供更多優惠和特權。VIP門票包含快速通道服務,可減少排隊時間。團體票適用於10人以上團隊,享受團體折
扣。
塊 3 (214 字符):
## 二、購票渠道與流程
### 1. 官方購票渠道
購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。這些渠道提供最可靠的服務和最新的票務信息。
### 2. 第三方平台
第三方平台如飛豬、攜程等合作代理商也可購票,但需認準官方授權標識。建議優先選擇官方渠道以確保購票安全。
### 3. 證件要求
所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。
塊 4 (264 字符):
## 三、入園須知
### 1. 入園時間
樂園通常在上午8:00開園,晚上8:00閉園,具體時間可能因季節和特殊活動調整。建議提前30分鐘到達園區。
### 2. 安全檢查
入園前需要進行安全檢查,禁止攜帶危險物品、玻璃製品等。建議輕裝簡行,提高入園效率。
### 3. 園區服務
園區內提供寄存服務、輪椅租賃、嬰兒車租賃等服務,可在遊客服務中心諮詢詳情。
生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。軍人優惠現役及
退役軍人憑證件享8折,需至少提前3天登記審批。
5. 滑動窗口切片
5.1詳細説明
這種方法與固定重疊類似,但更強調上下文的連續性。
- 核心思想:以很小的步長(遠小於塊大小)在文本上滑動,生成大量重疊的塊。這確保了任何一段文本及其周圍上下文都會以多種形式被索引。
- 工作流程:
- 設定窗口大小(window_size)和步長(stride)。
- 從文本起始開始,取第一個window_size的字符作為第一個塊。
- 向後移動stride個字符,取下一個window_size的字符作為第二個塊。
- 如此重複,直到覆蓋全文。
- 優點:能最大程度地保證檢索到任何一段文本及其所有可能的上下文窗口,對於捕捉局部上下文非常有效。
- 缺點:會產生巨大的索引,因為冗餘度很高,存儲和檢索成本大。
- 適用場景:代碼、日誌文件或任何局部上下文極度重要而存儲成本不是首要考慮因素的場景。
5.2 演示示例
"""
滑動窗口切片策略
固定長度、有重疊的文本分割方法
"""
def sliding_window_chunking(text, window_size=512, step_size=256):
"""滑動窗口切片"""
chunks = []
for i in range(0, len(text), step_size):
chunk = text[i:i + window_size]
if len(chunk.strip()) > 0:
chunks.append(chunk.strip())
return chunks
def print_chunk_analysis(chunks, method_name):
"""打印切片分析結果"""
print(f"\n{'='*60}")
print(f"📋 {method_name}")
print(f"{'='*60}")
if not chunks:
print("❌ 未生成任何切片")
return
total_length = sum(len(chunk) for chunk in chunks)
avg_length = total_length / len(chunks)
min_length = min(len(chunk) for chunk in chunks)
max_length = max(len(chunk) for chunk in chunks)
print(f"📊 統計信息:")
print(f" - 切片數量: {len(chunks)}")
print(f" - 平均長度: {avg_length:.1f} 字符")
print(f" - 最短長度: {min_length} 字符")
print(f" - 最長長度: {max_length} 字符")
print(f" - 長度方差: {max_length - min_length} 字符")
print(f"\n📝 切片內容:")
for i, chunk in enumerate(chunks, 1):
print(f" 塊 {i} ({len(chunk)} 字符):")
print(f" {chunk}")
# 測試文本
text = """
迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動。兩日票需要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標註的有效期限。
購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。第三方平台如飛豬、攜程等合作代理商也可購票,但需認準官方授權標識。所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。
生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。軍人優惠現役及退役軍人憑證件享8折,需至少提前3天登記審批。
"""
if __name__ == "__main__":
print("🎯 滑動窗口切片策略測試")
print(f"📄 測試文本長度: {len(text)} 字符")
# 使用滑動窗口切片
chunks = sliding_window_chunking(text, window_size=300, step_size=150)
print_chunk_analysis(chunks, "滑動窗口切片")
輸出結果:
🎯 滑動窗口切片策略測試
📄 測試文本長度: 324 字符
============================================================
📋 滑動窗口切片
============================================================
📊 統計信息:
- 切片數量: 3
- 平均長度: 165.0 字符
- 最短長度: 23 字符
- 最長長度: 299 字符
- 長度方差: 276 字符
📝 切片內容:
塊 1 (299 字符):
迪士尼樂園提供多種門票類型以滿足不同遊客需求。一日票是最基礎的門票類型,可在購買時選定日期使用,價格根據季節浮動。兩日
票需要連續兩天使用,總價比購買兩天單日票優惠約9折。特定日票包含部分節慶活動時段,需注意門票標註的有效期限。
購票渠道以官方渠道為主,包括上海迪士尼官網、官方App、微信公眾號及小程序。第三方平台如飛豬、攜程等合作代理商也可購票,但需
認準官方授權標識。所有電子票需綁定身份證件,港澳台居民可用通行證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。
生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。軍人優惠現役及
塊 2 (173 字符):
小程序。第三方平台如飛豬、攜程等合作代理商也可購票,但需認準官方授權標識。所有電子票需綁定身份證件,港澳台居民可用通行
證,外籍遊客用護照,兒童票需提供出生證明或户口本複印件。
生日福利需在官方渠道登記,可獲贈生日徽章和甜品券。半年內有效結婚證持有者可購買特別套票,含皇家宴會廳雙人餐。軍人優惠現役及
退役軍人憑證件享8折,需至少提前3天登記審批。
塊 3 (23 字符):
退役軍人憑證件享8折,需至少提前3天登記審批。
四、結合 FAISS 搭建本地知識庫
以下是結合 FAISS 搭建本地知識庫的完整流程圖。該流程圖詳細展示了從原始文檔到最終問答的整個流程,並突出了不同切片策略的應用場景和選擇路徑。
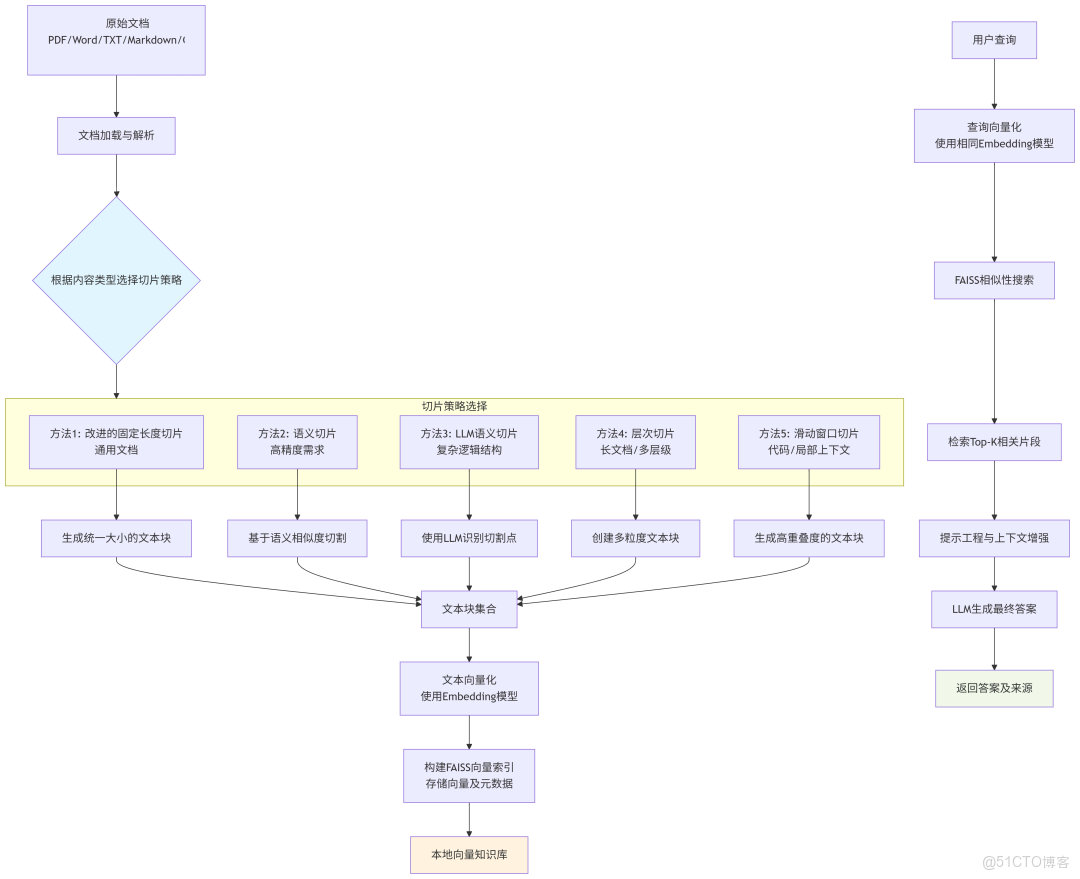
流程解析:
1. 文檔加載與解析
- 系統接受多種格式的原始文檔輸入(PDF、Word、文本、Markdown、代碼等)
- 使用相應的解析器提取純文本和元數據
2. 切片策略選擇(核心決策點)
這是流程中的關鍵決策環節,根據文檔類型和需求選擇最適合的切片策略:
- 方法1: 改進的固定長度切片
- 適用:通用文檔,內容結構相對統一
- 特點:在固定長度基礎上尊重句子邊界,平衡效率與語義完整性
- 方法2: 語義切片
- 適用:高精度需求場景(法律、學術、醫療)
- 特點:基於嵌入相似度檢測主題變化點,保證語義連貫性
- 方法3: LLM語義切片
- 適用:複雜邏輯結構文檔(哲學論述、創意寫作)
- 特點:使用LLM識別最佳切割點,智能度最高但成本也最高
- 方法4: 層次切片
- 適用:長文檔、手冊、書籍等多層級內容
- 特點:創建不同粒度的文本塊(章節、段落、句子),支持分層檢索
- 方法5: 滑動窗口切片
- 適用:代碼、日誌文件等局部上下文至關重要的內容
- 特點:高重疊度切割,確保任何內容都有充足的上下文
3. 向量化與索引構建
- 使用嵌入模型(如DeepSeek、OpenAI等)將文本塊轉換為向量
- 使用FAISS構建高效的向量索引,存儲向量及元數據(包括來源、頁碼等信息)
- 最終形成本地向量知識庫,支持快速相似性搜索
4. 查詢處理與答案生成
- 用户查詢經過相同嵌入模型向量化
- 在FAISS索引中執行相似性搜索,找到最相關的文本片段
- 通過提示工程將檢索到的上下文與用户問題組合
- LLM基於增強的上下文生成最終答案,並返回答案及其來源信息
五、選擇指南與建議
|
方法 |
智能度 |
計算成本 |
檢索質量 |
適用場景 |
|
改進固定切片 |
低 |
低 |
中 |
通用場景,良好的默認選擇 |
|
語義切片 |
高 |
非常高 |
非常高 |
高精度問答,法律、學術 |
|
LLM語義切片 |
極高 |
極高 |
極高 |
研究性,複雜文本結構 |
|
層次切片 |
中 |
中 |
高 |
長文檔,需兼顧精度與上下文 |
|
滑動窗口切片 |
低 |
中(索引大) |
中(局部性好) |
代碼、日誌、局部上下文關鍵 |
決策建議
- 從方法1改進固定切片開始,調整 chunk_size 和 chunk_overlap。
- 如果處理長文檔(書籍、手冊),優先嚐試方法4層次切片。
- 如果對答案質量有極致要求且不計成本,可以研究方法2語義切片。
- 方法5滑動窗口非常特殊,通常只用於代碼等場景。
- 方法3LLM語義切片目前更多處於實驗階段,成本過高。
總之,沒有放之四海而皆準的最佳策略。 最適合你數據和用例的策略需要通過實驗來確定。
- 準備一組代表性的測試問題。
- 用不同的策略和參數(大小、重疊)處理你的文檔。
- 運行你的RAG管道,評估答案的質量。評估答案是否準確?檢索到的上下文是否真正相關?
- 迭代優化:選擇效果最好的那種策略。
六、總結
RAG切片,本質上就是為了能讓AI高效地“閲讀”和“利用”龐雜的本地知識,我們提前把這些知識材料(文檔)進行合理的“預處理”,切割成大小適中、語義完整的小塊,並做好索引,以便快速精準檢索。
它就像是給AI大腦外接了一個整理得井井有條的“資料架”,而不是扔給它一個“混亂的書堆”。切片策略的好壞,直接決定了這個“資料架”的易用性和AI最終回答的質量。