









【USparkle專欄】如果你深懷絕技,愛“搞點研究”,樂於分享也博採眾長,我們期待你的加入,讓智慧的火花碰撞交織,讓知識的傳遞生生不息!
一、前言<
近期筆者一直在研究一個專題:在Android平台下,遊戲以30幀運行時,即便整體性能穩定,仍普遍存在畫面抖動現象。即使是知名廠商的遊戲也不例外。例如筆者測試《星穹軌道》時發現:
角色跑動時留意那盆綠植會比較明顯:

可能是出於功耗的考慮,一進來就默認推薦了30幀,玩起來也有持續性的畫面抖動,不像是偶發的卡頓,我的手機性能是較好的,不至於連30幀都跑不流暢。
通過一段時間的研究,對這個問題的原理和解決方案有了一定的見解。
二、原因分析
1. 顯示機制
Android的顯示機制是一個典型的生產者-消費者模型。應用端負責生產畫面,通過調用SwapBuffer將內容寫入BufferQueue,系統端(SurfaceFlinger進程)則從BufferQueue中取出內容,執行後續的合成與顯示流程。
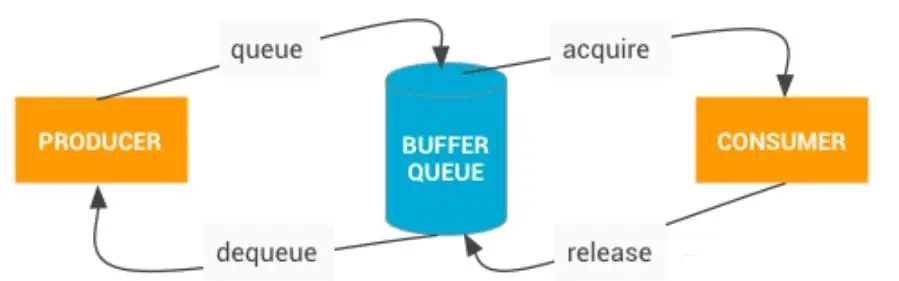
SurfaceFlinger取BufferQueue的節奏是根據系統Vsync-sf信號調節的,一般跟屏幕刷新率走,比如60hz那麼就是16.6ms為一個週期定期觸發,當遊戲為30幀時,平均是33.3ms生產一個Buffer,生產的速率遠遠慢於消耗的速率,當Vsync-sf信號來臨但BufferQueue裏面為空時,系統會重複顯示上一幀的內容。
理想情況下,在60Hz屏幕下運行30幀,SurfaceFlinger應該每兩個週期消耗一幀內容。然而通過分析發現,實際的消耗週期並不均勻:有時一個週期消耗,有時甚至三個週期消耗。導致每幀畫面在屏幕上的停留時間不一致,從而在視覺上產生抖動感。
2. 量化工具
接下來使用Perfetto來看一下這個遊戲,Perfetto是Android上系統級別的Trace工具,可以使用它來觀察具體的BufferQueue、Vsync情況。
Perfetto有一些配置,針對畫面抖動問題需要確認開啓ATrace的gfx、view模塊:

下圖中標註了每一次Buffer被消耗時,距離上一次的週期數:
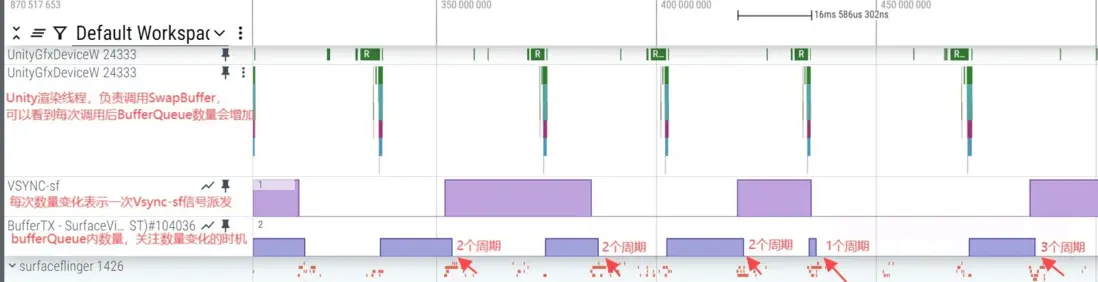
這裏篩選出了Trace數據中相關的軌道,從BufferQueue裏面可以看到大多數情況是2個週期消耗一次,偶爾會有1、3個週期出現。
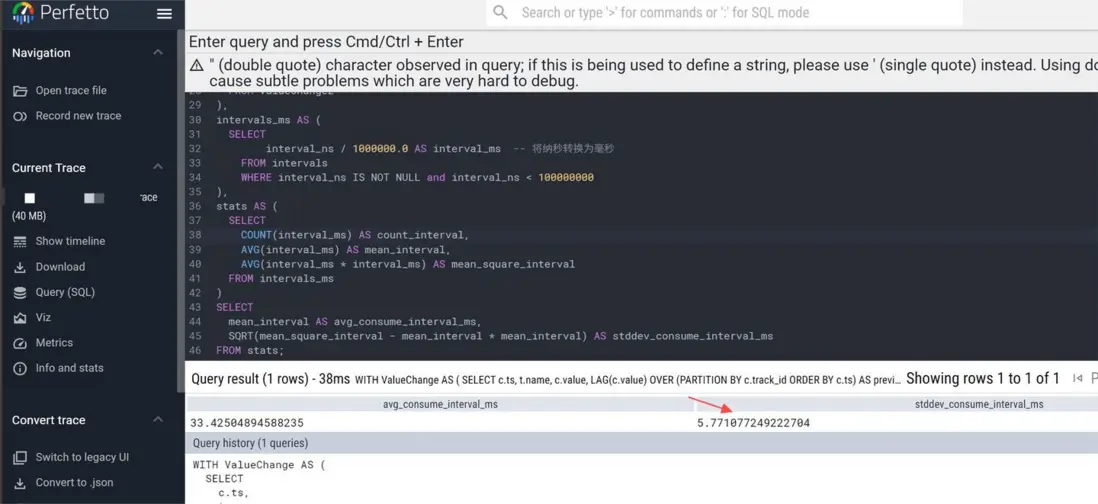
Perfetto生成的Trace文件可以通過SQL進行統計。筆者統計了每次BufferQueue減少時的時間點,進一步計算了這些時間間隔的標準差。該指標可用於量化畫面抖動的嚴重程度,為後續方案對比與優化提供了數據基礎。
完整SQL內容在附錄中提供:
三、目前的解決方案
1. Swappy方案
Swappy是Google GameSDK的一部分,這裏是它的官方介紹:
https://developer.android.com/games/sdk/frame-pacing?hl=zh-cn
*上述網址需要使用VPN打開
它是大多數遊戲引擎內置的方案,以Unity引擎為例直接設置一下生效就行。
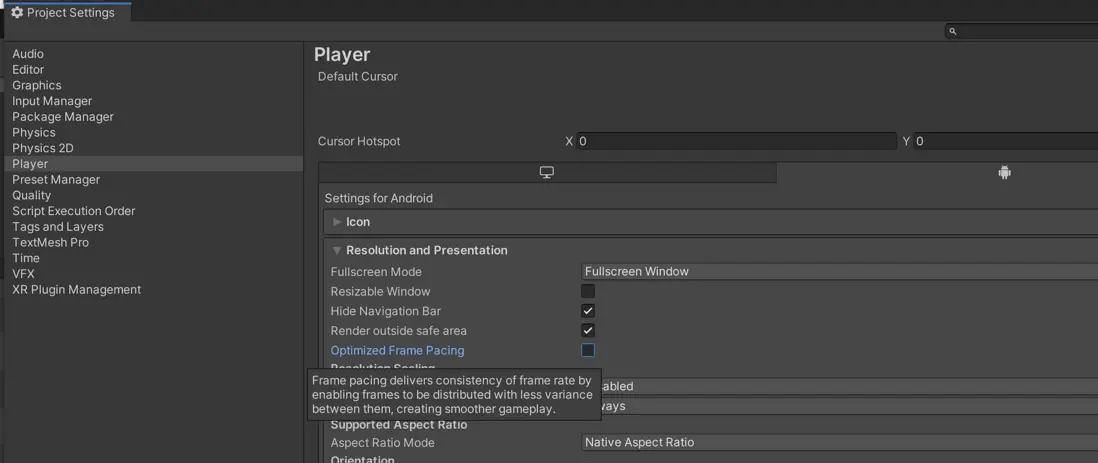
此方案核心是通過兩個EGL拓展來達成它的目的:
- 通過setPresentationTime,為Buffer設置一個時間戳,避免此Buffer被過快消耗掉。
回到之前我們的例子,如果這裏設置了一個允許被消耗的時間戳,那麼這裏不會存在1個週期就消耗掉的情況:
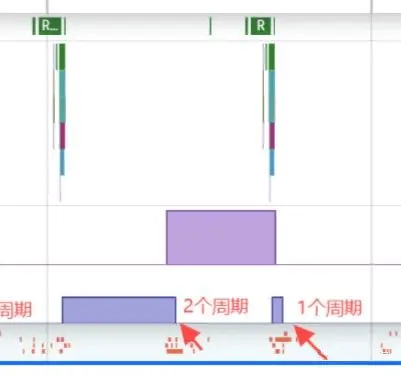
- 利用EGL_KHR_fence_sync,可以追蹤上一幀GPU處理完畢再將當前幀Swap進去。由於實際遊戲運行過程中不會是平穩地每次33.3ms Swap一次,會有波動,此策略可以避免局部生產過快導致的BufferQueue堆積。
Hook了Swappy中的一些函數,將其標註到了Perfetto中以觀察其運行過程:
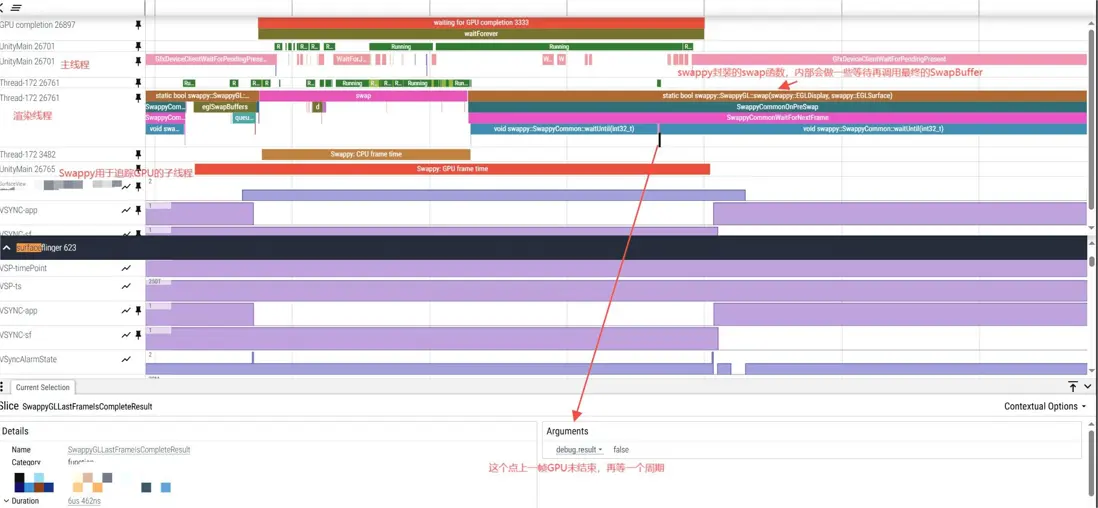
當然,筆者在實際使用過程中,也是遇到了不少問題:
- 掉幀,常見於開60幀的情況,因為要等上一幀GPU結束,不同手機追蹤到的GPU時間差異大,有的要10幾ms,再加上Swappy是以週期為單位進行等待的,很容易延後的時間太多,最終導致幀率下降嚴重,所以建議60幀時不啓用Swappy機制。
- 延遲明顯,一方面是渲染線程進行Swap的平均時間是要延後很多的,另一個方面是主線程是先做邏輯Update,然後通過WaitForPendingPresent等待上一幀渲染線程結束後,再繼續,從Update到最終呈現的鏈路多了一個流程,30幀時預估延遲會增加30~40ms左右,體感明顯。
- 不穩定,不同機型效果差異很大,觀察了一下發現有些機型setPresentationTime調用後,實際生效的時間並不精確,還有些機型60hz的屏幕刷新率但程序返回的值是59、58這些奇怪的值,可能會導致功能失效、鎖幀之類的問題。
總的來説Swappy對畫面抖動是有一定效果的,上述問題有些也好處理,只是此方案雖然開啓簡單,但決策前仍然要權衡、多機型實測評估。
2. 渲染線程同步方案
這是我在《王者榮耀》上發現的,他們使用了一種不同的方案來解決這個問題。
王者開30幀時的表現:
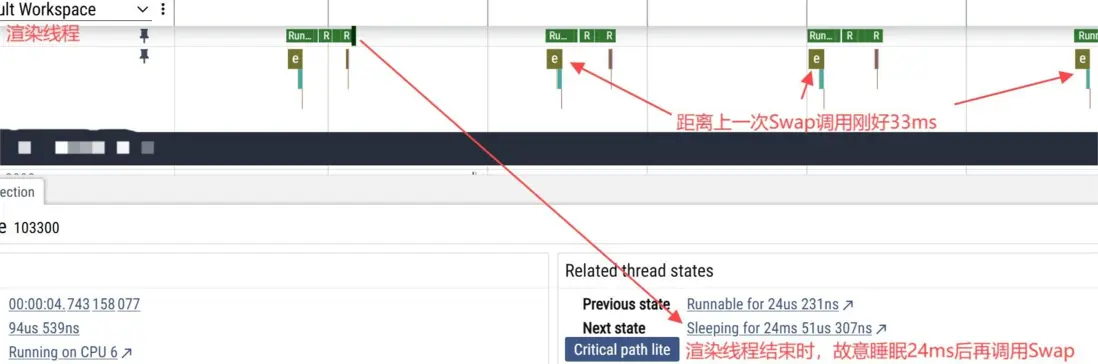
此方案是通過讓應用端畫面生產節奏保持絕對的均勻,來間接讓SurfaceFlinger消耗的節奏均勻,需要改一下引擎實現:
- 渲染線程每次Swap調用前留一個時間戳,如果下一次Swap前的間隔時間小於33ms,則Sleep補全時間後再Swap。另外主線程WaitForTargetFPS的邏輯要去掉,依賴渲染線程控制輸出節奏。
- 還有個小細節,我通過逆向分析發現王者主線程等待上一個渲染線程結束的Sync點調整到了邏輯Update前,這樣雖然降低了主線程、渲染線程的並行程度,但延遲上有優勢,因為從邏輯Update到Swap中間沒有WaitForPendingPresent。
這個辦法簡單易行,筆者實測是有效的,當然延遲還是不可避免會增加,30幀時預估延遲會增加16ms左右,仍然比Swappy少很多,算是一個平衡的方案,值得參考。
四、後續探索
很慚愧,目前對於這一問題,筆者尚未找到一個完全理想的解決方案。雖然“渲染線程同步”方案在實際測試中確實能夠改善畫面抖動,但仍存在不可忽視的侷限:一方面,這一方案本質上是通過延長時間來達到輸出節奏的均勻,導致整體延遲有所增加,另一方面,對於抖動的緩解效果其實也是有限的。
同時,Swappy庫作為Google官方提供的開源方案,內部實現中有許多值得借鑑的點,它能推算出Vsync-sf信號點時間。所以筆者計劃在現有“渲染線程同步”方案上進行進一步優化,結合推算出的Vsync-sf信號點時間信息來減少渲染線程Sleep的量,降低延遲,提升精準度。希望通過不斷的迭代,能逐步逼近一個更加完美、兼顧效果與延遲的方案。
五、附錄:Perfetto中量化統計畫面抖動的SQL
WITH ValueChange AS (
SELECT
c.ts,
t.name,
c.value,
LAG(c.value) OVER (PARTITION BY c.track_id ORDER BY c.ts) AS previous_value,
process.name
FROM
counter AS c
JOIN process_counter_track AS t ON c.track_id = t.id
JOIN process ON t.upid = process.upid
WHERE
t.name LIKE "%SurfaceView%" and process.name LIKE "%SurfaceFlinger%"
),
ValueChange2 AS (
SELECT
ts,
name,
value
FROM
ValueChange
WHERE
value < previous_value
),
intervals AS (
SELECT
ts - LAG(ts) OVER (ORDER BY ts) AS interval_ns
FROM ValueChange2
),
intervals_ms AS (
SELECT
interval_ns / 1000000.0 AS interval_ms -- 將納秒轉換為毫秒
FROM intervals
WHERE interval_ns IS NOT NULL and interval_ns < 100000000
),
stats AS (
SELECT
COUNT(interval_ms) AS count_interval,
AVG(interval_ms) AS mean_interval,
AVG(interval_ms * interval_ms) AS mean_square_interval
FROM intervals_ms
)
SELECT
mean_interval AS avg_consume_interval_ms,
SQRT(mean_square_interval - mean_interval * mean_interval) AS stddev_consume_interval_ms
FROM stats;這是侑虎科技第1894篇文章,感謝作者其樂陶陶供稿。歡迎轉發分享,未經作者授權請勿轉載。如果您有任何獨到的見解或者發現也歡迎聯繫我們,一起探討。(QQ羣:793972859)
作者主頁:https://www.zhihu.com/people/jun-yan-76-80
再次感謝其樂陶陶的分享,如果您有任何獨到的見解或者發現也歡迎聯繫我們,一起探討。(QQ羣:793972859)



