一、調度不准問題及修正方式侷限性
在字節跳動的業務生態中,HTTPDNS承擔着為抖音、今日頭條、西瓜視頻等核心應用提供域名解析服務的重任。但目前我們所採用的業界主流緩存機制(火山Cache1.0),卻存在着調度不準的問題:
業界主流緩存機制的問題
緩存粒度:城市-運營商
致命缺陷:當自身IP庫與權威DNS服務器不同,易發生調度不準,可能影響用户體驗
主流調度修正機制的侷限性
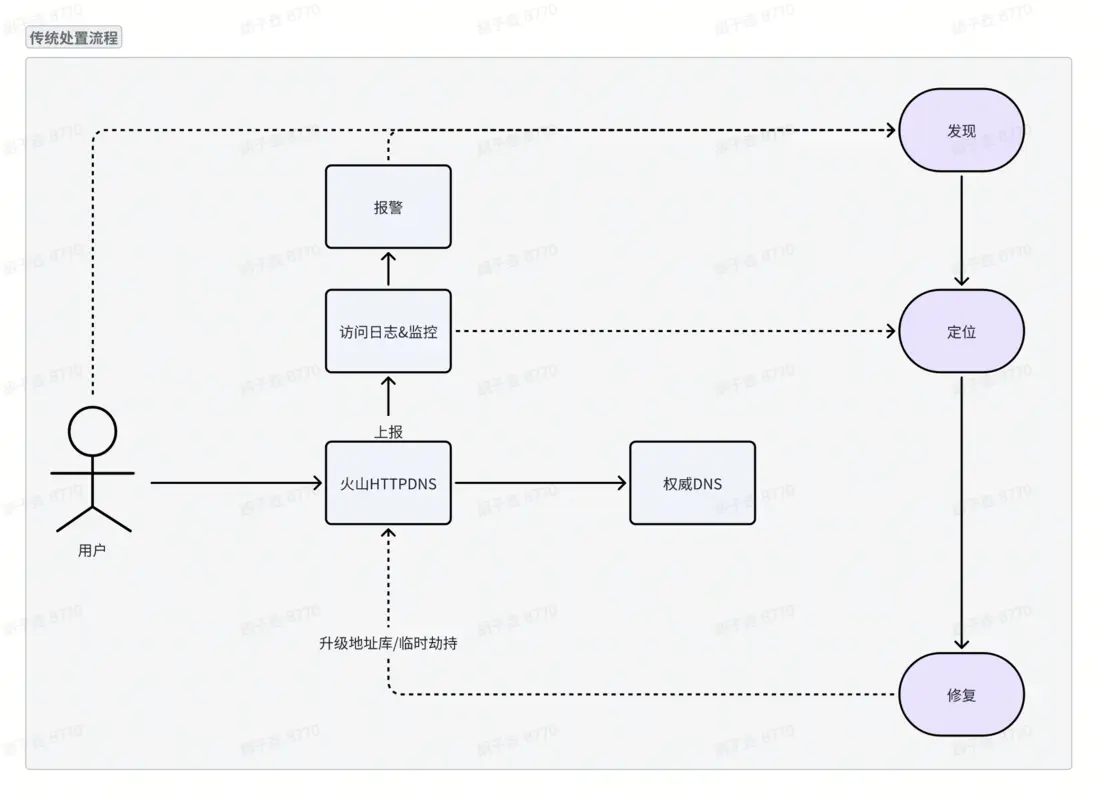
針對 HTTPDNS調度不準風險,業界主流處置流程採用 “發現 - 定位 - 修復” 三步閉環機制,具體如下:
1. 發現:通過監控告警、業務異常反饋等方式,識別存在調度偏差的解析場景;
- 定位:結合訪問日誌、鏈路追蹤數據等,定位調度不準的具體域名、源IP段和目標 IP 段;
-
修復:通過技術手段修正解析結果,核心修復方式包含以下兩類(均存在顯著侷限性):
○ 地址庫升級:基於外部供應商數據聚合構建的 IP 地址庫,即使實時更新,仍難與外部 CDN 廠商的映射保持一致。
○ 臨時劫持:手動配置解析劫持規則修正解析結果,不僅操作流程繁瑣、耗時長,且需人工維護大量靜態配置;若規則未得到及時維護,易引發解析結果異常。
二、Cache2.0 架構優化
緩存粒度技術方案對比
緩存粒度設計直接影響 DNS 解析精準度,主流廠商的方案存在明顯差異:
緩存鍵精細化重構
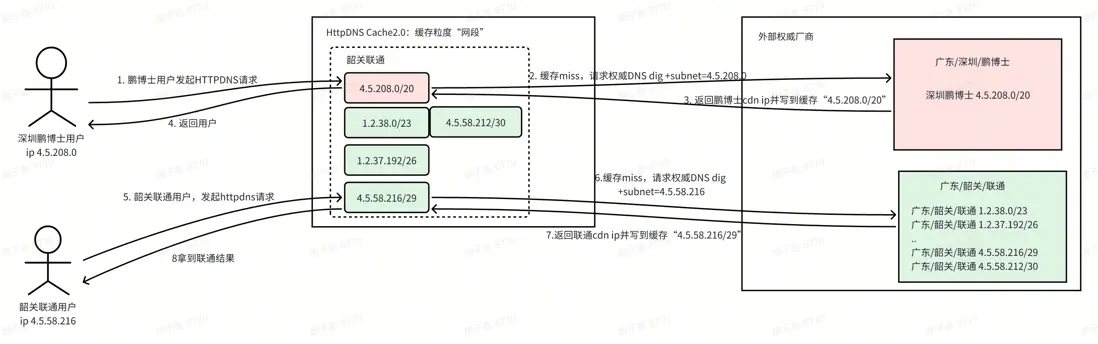
我們綜合考量調度精準度、工程複雜度以及成本,決定將緩存粒度由“城市 + 運營商”細化為“網段”。
傳統方案(國內某廠商/火山Cache1.0)
• 緩存粒度:城市+運營商
• 污染範圍:整個城市運營商
•調度準確性:低
Cache2.0方案
• 緩存粒度:網段
• 污染範圍:單個網段
• 調度準確性:高
網段自適應劃分算法
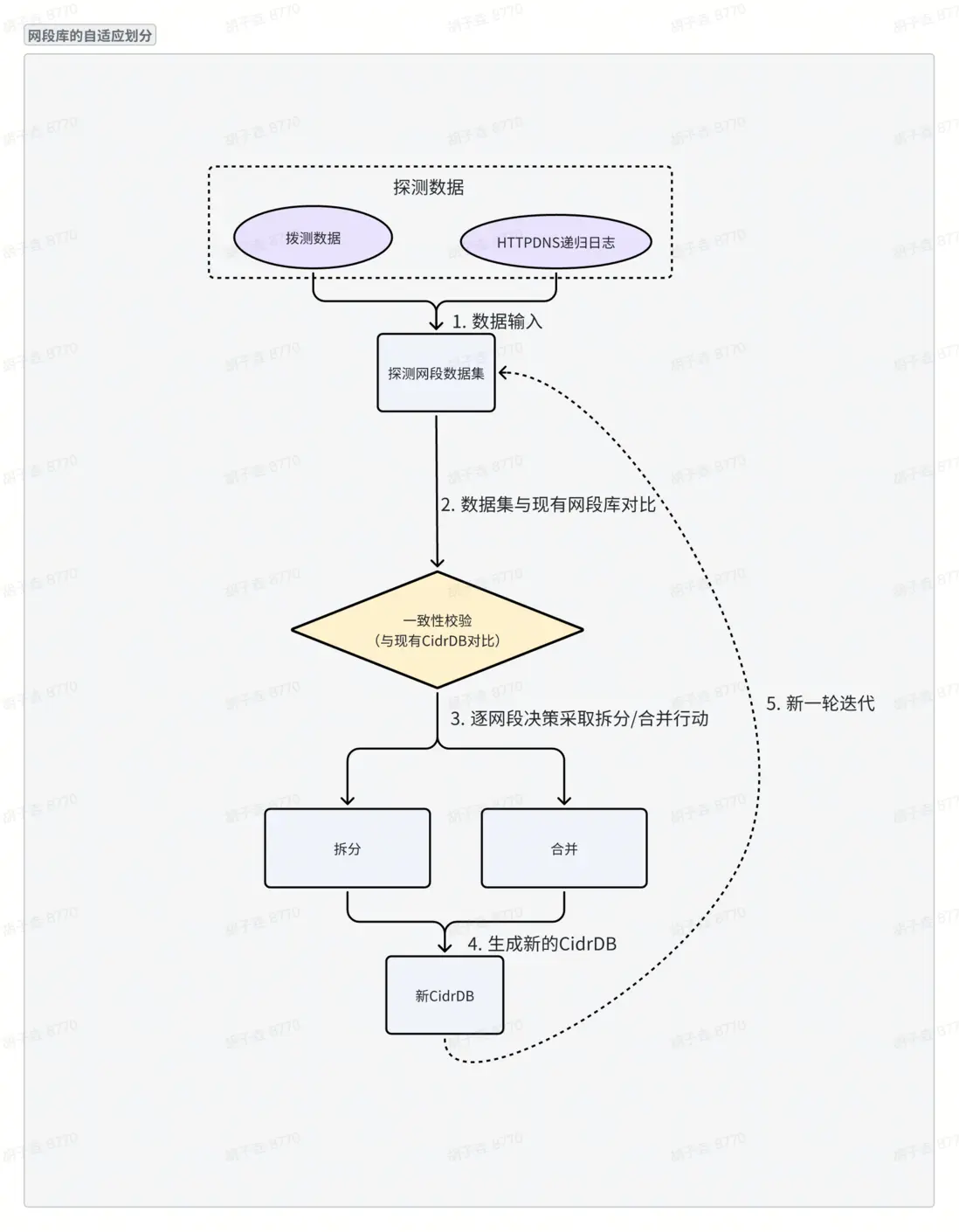
背景:外部 CDN 廠商的調度結果會隨網絡拓撲和調度策略持續變化,而靜態網段庫劃分方式固定,難以實時跟蹤調度結果變化。為解決這一問題,網段庫動態劃分算法通過“數據輸入—一致性校驗—網段調整—結果輸出”的閉環流程,實現了網段庫的自適應動態劃分。
具體流程如下:
1. 數據輸入○
收集客户端IP—CDN IP映射數據
▪ 數據來源:主動撥測結果;HTTPDNS 遞歸節點日誌。
▪ 數據範圍:主流CDN廠商的解析結果。
○ 網段歸屬判斷:▪ 若相鄰客户端IP的CDN IP 歸屬同一運營商,則該組CIP可合併為連續網段。▪ 將合併後的連續網段輸出,作為探測網段數據集。
2. 一致性校驗○
將探測網段數據集與存量CIDRDB網段庫進行逐網段對比,檢查 “映射一致性”。
○ 若存在映射不一致,則觸發網段調整流程。
3. 網段調整
a. 合併:探測數據集的網段比現有庫粗,合併為大網段。
b. 拆分:探測數據集的網段比現有庫細,拆分為小網段。
4. 結果輸出○
生成優化後的新CIDRDB網段庫。
替換存量網段庫,實現動態更新。
5. 持續迭代
a. 重複上述流程,實現網段庫的自適應動態劃分。
緩存策略優化
為解決緩存粒度細化可能導致的命中率下降問題,Cache2.0 引入了四重優化策略,最終實現瞭如下收益:
緩存命中率提高了15%,緩存量、CPU 使用和出網流量降低了約70%。
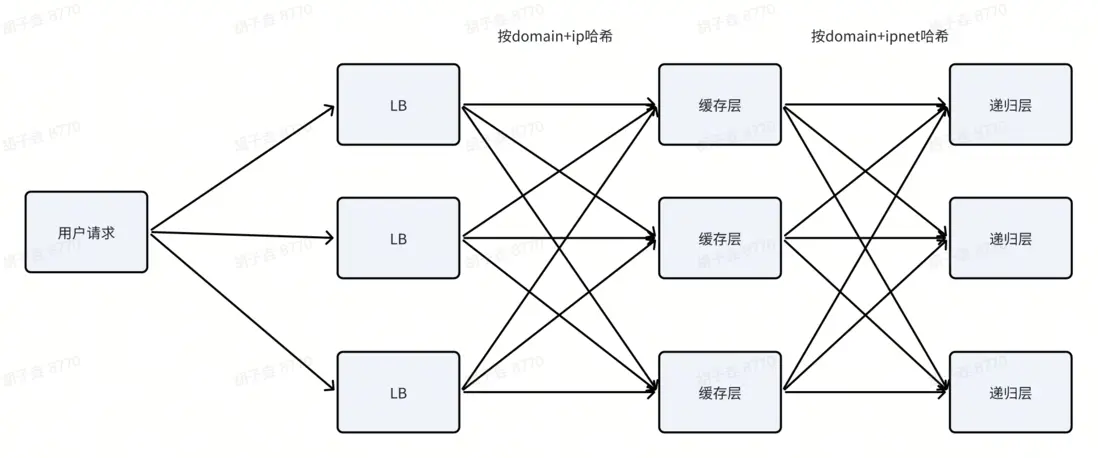
1.兩級一致性哈希分流
火山 HTTPDNS 的流量轉發以一致性哈希思想為核心,將用户請求鏈路(用户→LB→緩存層→遞歸層)拆分為兩級哈希調度:
一級調度(LB→緩存層):以“源 IP + 域名”為哈希鍵。使用LB的一致性哈希策略,將同一用户對同一域名的請求統一路由至固定的 HTTPDNS 節點,避免傳統輪詢導致的請求分散。
二級調度(緩存層→遞歸層):以“域名 + 網段” 為哈希鍵。以 “域名 + 客户端網段” 作為哈希鍵,與緩存粒度完全對齊,確保某一“域名 + 網段”對應的查詢請求均定向到唯一的遞歸層節點。
兩級哈希協同調度,解決了緩存的碎片化問題,同時單一節點故障影響範圍極小。
2.緩存分級管理
在 HTTPDNS 場景中,不同域名對解析精度的需求不同。高優先級域名(如API 調用、直播 / 點播流媒體分發)對解析精準性要求高,跨網可能導致訪問延遲增加;而低精度需求域名(如302域名)採用過細緩存會浪費存儲資源,頻繁回源也會增加權威 DNS 壓力。
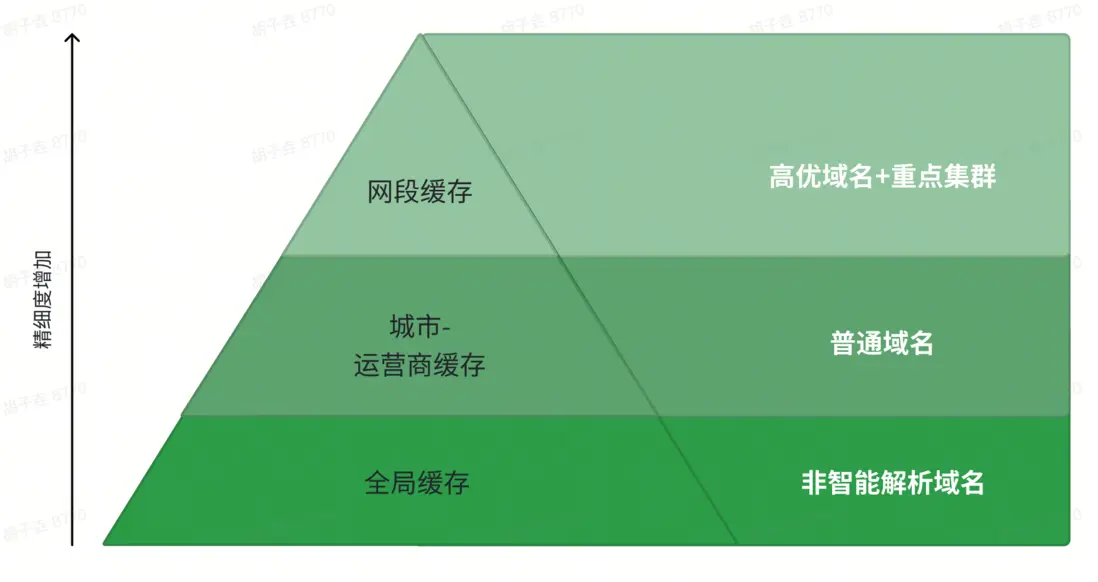
為實現緩存資源的精細化分配,火山 HTTPDNS 將緩存體系劃分為“網段緩存、城市 - 運營商緩存、全局緩存” 三級,各級緩存適配不同應用場景。
• 網段緩存:作為最高精度層級,聚焦高優先級業務場景 :一方面適配高優域名(如抖音 API 調用、圖片分發、點播 / 直播流媒體傳輸等對精準性敏感的域名),另一方面服務重點集羣(如 ToB 企業 HTTPDNS 服務、ToB 專屬公共 DNS 服務),通過網段級細粒度緩存確保解析結果與用户實際網絡鏈路高度匹配,降低訪問延遲。
• 城市 - 運營商緩存:定位中等精度層級,適配普通域名場景:針對調度精準度要求較低的域名,以 “城市 + 運營商” 為緩存單元,平衡緩存命中率與存儲開銷。
• 全局緩存:作為基礎精度層級,專門適配非智能解析域名:針對不支持 CDN 動態調度、解析結果無地域 / 運營商差異的域名(如靜態官網、通用工具類服務域名),採用全局統一緩存策略,所有用户查詢共享同一緩存結果,最大化提升緩存命中率,降低迴源請求壓力。
3.緩存更新分級策略
在 HTTPDNS 系統中,統一的主動刷新策略雖然能保證緩存命中率,但存在明顯問題:對不需要精細調度的域名浪費了存儲資源,增加了下游壓力。
基於以上問題,火山 HTTPDNS引入 “主動刷新 + 被動刷新”分級策略,以域名優先級和業務需求為依據,將緩存更新機制分為兩類:
• 後台線程主動刷新機制:針對高優域名(白名單),保留後台線程主動刷新,確保緩存持續有效、用户請求直接命中最新數據。
• 用户請求被動刷新機制:針對普通域名或非智能解析域名,由請求觸發緩存更新,按需刷新,無需常駐後台刷新線程,降低資源消耗。
通過這種分級更新策略,高優先級域名仍能保證低延遲和高命中率,同時普通域名的刷新開銷顯著降低。
4.緩存預取機制
依託 “緩存空間局部性原理”,火山 HTTPDNS 設計了緩存預取機制。當某條緩存請求(如 A 網段域名解析)觸發更新時,系統不僅刷新目標網段緩存,還會同步更新與其具有 “親緣關係” 的網段緩存(“親緣關係”指地理相鄰、同運營商節點覆蓋的網段)。這種 “單次請求觸發批量預取” 的設計能夠提前將關聯網段緩存置於準備狀態,提升後續請求的命中率。
以抖音直播域名的實際訪問場景為例,預取機制的運作過程如下:
• 本網段更新:當用户 A(IP 歸屬北京聯通 10.0.1.0/24 網段)發起直播域名解析請求時,系統首先刷新其所屬的 10.0.1.0/24 網段緩存。
• 預取更新:系統同時刷新與 10.0.1.0/24 網段具有親緣關係的網段緩存,例如北京聯通下的相鄰網段(10.0.2.0/24、10.0.3.0/24),確保這些網段緩存也處於準備狀態。
隨後,當用户 B(10.0.2.0/24)或用户 C(10.0.10.0/24)發起相同直播域名的解析請求時,由於對應網段緩存已提前預取,無需等待回源即可直接命中緩存,顯著降低訪問延遲。三、全鏈路效能提升
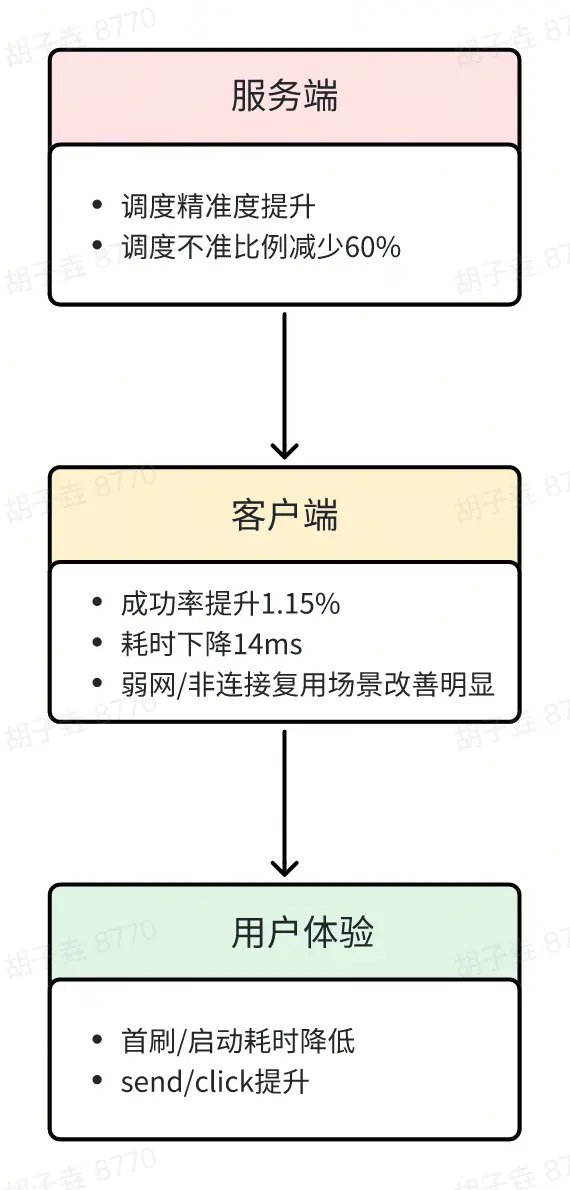
1. 服務端調度精準度提高
藉助網段級緩存,用户獲取的 IP 地址更加精準。按服務端日誌數據口徑,調度不準比例從萬分之六下降至萬分之二,降幅 60%,有效緩解了傳統粗粒度緩存導致的“城市級緩存污染”問題。
2. 客户端性能優化
成功率:核心 feed 接口,在弱網+非連接複用場景下提升 1.15%。
耗時:非連接複用場景耗時減少14ms。
3. 用户體驗提升
性能指標:首刷及啓動耗時下降。
用户指標:用户行為指標(send 與 click)正向,用户活躍度提升。
本方案通過服務端精準調度 → 客户端性能優化 → 用户體驗提升,實現了全鏈路效能提升。四、持續演進方向
共享緩存
目前,各機房的負載均衡策略與緩存策略未能完全對齊(部分採用隨機轉發,部分雖然使用一致性哈希但粒度不一致),導致同一數據在多個實例中被重複緩存,資源利用率偏低,緩存命中率也有待提升。
未來,我們計劃構建一個分層共享的高可用緩存體系:
• 在同一機房內,實例通過一致性哈希協同分工,每台實例既是分片緩存,也能代理轉發請求,從而減少重複存儲並提升命中率。
• 在跨機房層面,按區域部署二級緩存節點,作為容量更大、延遲更低的共享中心,承接一級未命中的請求,降低跨區域訪問和上游壓力。與此同時,引入熱點數據副本、請求合併和故障轉移等機制,保證高併發和異常情況下的穩定性與可用性。
通過這一演進,整體架構將逐步升級為層次化、分佈式且具備高可用能力的緩存網絡,為業務的持續擴展提供堅實支撐。