









作者: vivo 互聯網大前端團隊- You Chen
本文介紹可以在微信小程序上應用的端智能技術方案,聚焦 TensorFlow.js 推理和微信原生推理,詳細講解這兩種方案在項目中的應用過程,為小程序開發者提供可複用的端智能技術選型策略與工程化解決方案。
1分鐘看圖掌握核心觀點👇

本文提供配套演示代碼,可下載體驗:
Github | weixin-mini-ai
一、背景
隨着AI浪潮的到來,各行各業都在利用AI賦能自身的業務,我們在vivo+雲店項目上也進行了端智能探索,併成功應用到個性化商品推薦業務上,小程序端直接本地調用AI模型進行商品推薦,上線後商品點擊率提升了30%,取得了不錯的業務效果,接下來介紹如何讓微信小程序具備端智能能力。

二、技術選型
在項目啓動之前我們進行了相關技術調研,發現完備的微信小程序端智能方案並不是很多,最終鎖定了 TensorFlow.js 推理和微信原生推理這兩種方案,它們有着相對完善的説明介紹,整體對比如下表所示。

2.1 TensorFlow.js 推理
TensorFlow.js 是谷歌開發的機器學習開源項目,致力於為Javascript提供具有硬件加速的機器學習模型訓練和部署,在小程序端以插件的方式封裝了TensorFlow.js庫,方便小程序進行調用,同時需要配合安裝相應的TensorFlow.js npm包來使用,接入步驟相對繁瑣,但支持更低的微信基礎庫版本。

2.2 微信原生推理
微信原生推理是指調用小程序AI通用接口來進行推理,它是一套官方提供的通用AI模型推理解決方案,開發者無需關注其內部實現,只需要提供訓練好的ONNX模型,小程序內部就可以自動完成推理。該方案接入步驟很少,目前還處於Beta階段,所需要的微信基礎庫版本更高。

三、項目接入
技術方案選定好以後進入到項目接入環節,接下來將會分別介紹 TensorFlow.js 推理和微信原生推理方案的接入細節以及在項目接入過程中遇到的一些問題。
3.1 模型處理
在開始之前需要準備一個訓練好的個性化商品推薦模型,本次模型是基於TensorFlow框架來進行訓練的,模型訓練完保存的格式是默認的SavedModel格式,但這個格式無法在小程序上直接使用,還需要進行相應的格式轉換。
3.1.1 TensorFlow.js 格式
如果使用TensorFlow.js推理方案,要將SavedModel格式轉換成TensorFlow.js格式,可以安裝@tensorflow/tfjs-converter包,這個包專門用來將TensorFlow模型格式轉換成Web端可加載的TensorFlow.js格式,具體轉換命令如下:
tensorflowjs_converter --input_format=keras_saved_model output output/tfjs_model
執行命令後會生成model.json模型拓撲文件和後綴為.bin的二進制權重文件。
3.1.2 ONNX 格式
如果使用微信原生推理方案,同樣要將SavedModel格式轉換成ONNX模型格式,可以安裝tf2onnx庫,這個庫可以將TensorFlow模型格式轉換成ONNX模型格式,具體轉換命令如下:
python -m tf2onnx.convert --saved-model output --output output/model.onnx
執行命令後會生成一個後綴為.onnx的文件。
3.1.3 模型更新
通過前面的操作得到了不同格式的模型文件,我們將這些模型文件放到靜態資源服務器上,小程序端遠程加載模型文件,需要注意模型需要定期用最新的數據進行訓練更新,因此在獲取模型鏈接時我們通過服務端接口來獲取,方便隨時進行更新。
3.2 小程序AI能力封裝
小程序端相對於其它端有很大的不同,小程序代碼包體積受限,單個包體積不能超過2MB,因此在設計AI模型調用方案時需要考慮到代碼體積問題。vivo+雲店項目是基於uniapp框架開發的小程序,接下來介紹不同推理方案的接入細節。
3.2.1 TensorFlow.js推理接入
TensorFlow.js 推理在接入之前需要在小程序管理後台安裝一下TensorFlow.js插件,直接搜索wx6afed118d9e81df9即可完成添加:

接着在項目代碼倉啓用該插件,並安裝TensorFlow.js相關依賴,可以按需加載必要的依賴,本次項目使用了tfjs-core、tfjs-layers、tfjs-backend-webgl和fetch-wechat這幾個包。安裝完相關依賴以後,還需要初始化插件:
const plugin = requirePlugin('tfjsPlugin')
plugin.configPlugin({
// polyfill fetch function
fetchFunc: fetchWechat.fetchFunc(),
// inject tfjs runtime
tf,
// inject webgl backend
webgl,
// provide webgl canvas
canvas: wx.createOffscreenCanvas()
})
初始化完成以後就可以加載使用模型了,然而在小程序打包上傳的時候提示主包體積嚴重超包,原因是TensorFlow.js相關依賴包體積太大了,達到了1.3MB左右,嚴重影響了正常的業務代碼體積,因此還要解決超包問題。我們最終採用了分包異步加載的方式將相關依賴剝離出主包,具體步驟如下:
(1)封裝分包組件
將TensorFlow.js相關依賴的引入和插件初始化邏輯封裝到分包組件當中,採用事件傳遞的方式將引入的TensorFlow模塊傳遞給父頁面。
// 組件路徑/sdkPackages/tensorflow/index
<template>
<div></div>
</template>
<script>
import * as tf from '@tensorflow/tfjs-core'
import * as tfLayers from '@tensorflow/tfjs-layers'
...
export default {
mounted() {
this.initTf()
},
methods: {
initTf() {
// 插件初始化
...
// 將引入的依賴模塊以事件的方式拋出
this.$emit('start', { tf, tfLayers })
}
}
}
</script>
(2)異步分包加載
封裝的組件想要在父頁面中進行異步分包加載,還需要在page.json文件中進行異步分包組件引入配置,設置完成以後直接在父頁面裏使用即可,具體配置如下:
{
"path": "pages/demo/index",
"style": {
"navigationBarTitleText": "demo",
"componentPlaceholder": {
"tf-com": "view"
},
"usingComponents": {
"tf-com": "/sdkPackages/tensorflow/index"
}
}
}
需要注意,父頁面獲取的異步分包組件傳遞的事件值和普通Vue組件傳遞的事件值不太一樣,需要在 e.detail.args[0]中獲取到。
<template>
<div>
<!-- 父頁面引入分包異步組件 -->
<tf-com @start="startTf"></tf-com>
</div>
</template>
<script>
export default {
methods: {
startTf(e) {
//獲取子組件傳遞的Tensorflow模塊
const { tf, tfLayers } = e.detail.__args__[0]
....
}
}
}
</script>
完成上面兩個步驟,TensorFlow.js相關依賴會全部打包到分包當中,不會佔用主包體積。

到這裏 TensorFlow.js 推理相關準備已全部完成,以下是調用示例,主要分為兩個階段:
- 模型加載:調用loadLayersModel方法加載遠程模型
- 模型推理:調用模型的predict方法輸出推理結果
export class TfModel {
modelUrl
modelName
model
hasInited = false
constructor({ modelUrl, modelName, spuIdList}) {
this.modelUrl = modelUrl
this.modelName = modelName
}
// 模型加載
async load() {
this.model = await tfLayers.loadLayersModel(this.modelUrl)
this.hasInited = true
}
// 模型推理
async run(inputList) {
const prediction = this.model.predict(tf.tensor([inputList]))
const values = await prediction.array()
console.log('模型推理結果:', values)
}
}
由上可以看出TensorFlow.js推理方案缺點是接入步驟挺多,需要處理超包問題,但優點是支持的微信版本範圍廣,更重要的是它支持本地開發者工具調試。看到這裏可能有人會疑問為什麼支持本地調試也是優點?繼續往下看就能得到答案。
3.2.2 微信原生推理接入
微信原生推理方案不需要安裝任何依賴,僅使用微信提供的API即可完成模型調用,以下是調用示例:
export class OnnxModel {
modelUrl
modelName
session
hasInited = false// 模型是否初始化完成
constructor({ modelUrl, modelName }) {
this.modelUrl = modelUrl
this.modelName = modelName
},
// 模型加載初始化
load() {...},
// 創建推理會話
createInferenceSession(modelPath) {...},
// 推理運行
run(inputList) {...}
}
整個模型加載推理分為下面3個階段:
(1)模型加載初始化
模型先遠程加載,下載到本地同時創建模型緩存文件,當二次加載時會查看本地是否有緩存的模型文件,如果有緩存就直接使用緩存數據。
load() {
return new Promise((resolve, reject) => {
const modelPath = `${wx.env.USER_DATA_PATH}/${this.modelName}.onnx`
// 判斷之前是否已經下載過onnx模型
wx.getFileSystemManager().access({
path: modelPath,
success: () => {
// 模型有本地緩存
// 創建推理會話
this.createInferenceSession(modelPath)
...
},
fail: (res) => {
// 遠程加載onnx模型
wx.downloadFile({
url: this.modelUrl,
success: (result) => {
wx.getFileSystemManager().saveFile({
tempFilePath: result.tempFilePath,
filePath: modelPath,
success: (res) => {
// 創建推理會話
const modelPath = res.savedFilePath
this.createInferenceSession(modelPath)
...
},
fail: (err) => { reject(err) }
})
}
fail: (err) => { reject(err) }
})
}
})
})
(2)創建推理會話
模型加載完以後調用wx.createInferenceSession創建一個session用來模型推理。
createInferenceSession(modelPath) {
return new Promise((resolve, reject) => {
this.session = wx.createInferenceSession({
model: modelPath
})
// 監聽error事件
this.session.onError((error) => {
reject(error)
})
this.session.onLoad(() => {
resolve()
})
})
}
需要注意,在實際代碼調試時發現本地開發者工具目前還不支持該API,只能真機調試。

(3)執行推理
創建好session以後就可以執行模型推理了,直接調用session.run方法即可。
async run(inputList){
const input = {
type: 'float32',
shape: [1, 8],
data: new Float32Array(inputList).buffer
}
const res = await this.session.run({ input })
console.log('onnx模型推理結果:', Array.from(new Float32Array(res.output.data)))
}
到這裏微信原生推理方案也介紹完了,可以看出它的優點是接入步驟很少,僅佔用很少代碼體積,但它的缺點也很明顯,不能本地調試,而且要求的基礎庫版本高,目前處於Beta階段,還不清楚線上不同系統機型是否都支持。
3.3 組合調用
為了保證小程序端智能的穩定運行和更廣範圍的微信版本支持,同時兼顧本地開發體驗,我們將兩種方案組合起來使用,優先使用接入簡單的微信原生推理,其次使用TensorFlow.js 推理。調用示例如下:
async initAI(){
if (wx.canIUse('getInferenceEnvInfo')) {
// 基礎庫滿足微信原生推理
await new Promise((resolve) => {
wx.getInferenceEnvInfo({
success: async () => {
// 調用微信原生推理
...
resolve()
},
fail: (res) => {
// 調用TensorflowJS推理
...
resolve()
}
})
})
} else if(checkVersion()){
// 檢查基礎庫版本,符合條件調用TensorflowJS推理
...
} else {
// 不支持端智能,兜底處理
...
}
}
通過調用微信getInferenceEnvInfo方法可以獲取通用AI推理引擎版本,如果當前手機支持微信原生推理就會觸發成功的回調,否則會觸發失敗的回調,如果基礎庫不支持微信原生推理就會去判斷是否滿足TensorFlow.js推理調用條件,通過這樣的方式動態選擇當前手機支持的推理方式,如果都不支持就走兜底處理方案。通過該方式,線上90%以上的用户成功走到了端智能場景。
3.4 性能效果
當小程序端智能能力正式上線以後,推薦設計一些埋點監控模型推理執行的性能效果,包括模型推理運行各階段耗時和模型推理異常日誌,方便後續的迭代優化。
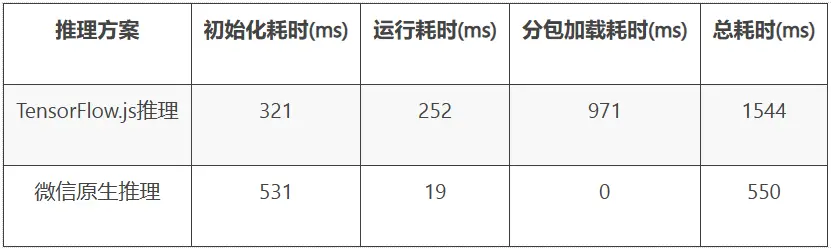
上表是業務上線後兩種推理方案的各階段平均耗時,我們使用的模型大小在110KB左右,從數據表現來看微信原生推理方案性能更好,總耗時僅需要550ms,而TensorFlow.js推理方案總耗時多是因為需要加載異步分包組件,當然可以考慮設置分包預加載來減少前置等待。
四、總結
整體回顧一下,本文介紹了兩種可以在微信小程序上落地實施的端智能工程化解決方案:TensorFlow.js推理和微信原生推理,在項目接入過程中針對以下幾個方面進行了處理:
- 模型格式:一鍵命令格式轉換,適配不同推理方案
- 代碼包體積:異步分包加載,解決TensorFlow.js相關依賴超包問題
- 開發體驗、支持範圍:組合兩種方案,保障開發體驗,最大化覆蓋微信版本範圍
希望本文采取的方案以及處理的問題對你進行小程序端智能技術選型有所幫助,也歡迎在評論區一起交流其它可行性方案。












