









作者:Gu Ruinan - 互聯網大數據團隊- Zhao Yongxiang
Erasure Coding(簡稱EC),是一種糾刪碼。EC編碼能夠對部分缺失的數據進行數據恢復,廣泛應用於存儲與通信領域。在Hadoop3.0版本中,作為一種新的冗餘存儲的方式引入進來。使用EC編碼的方式替代原來的三副本存儲,保證數據可靠性的同時可以節約存儲。相應地,付出的代價是讀取性能的下降,對於訪問頻率不高的數據,使用EC編碼很合適。
vivo目前HDFS集羣節點達萬台級別,數據規模接近EB級別,並且業務數據規模還在以較高速度持續增長中。在推進壓縮算法緩解存儲壓力的同時,EC編碼的推進也是存儲降本的一大有力手段。
1分鐘看圖掌握核心觀點👇
一、背景
Reed-Soloman編碼(簡稱:RS碼),是EC裏一種經典的編碼算法。下面簡單介紹一下Reed-Soloman編碼過程(不涉及數學原理的詳細解析)。
假設我們的輸入數據以D1,D2,...D5的向量來表示,矩陣B為編碼矩陣,進行編碼後得到D和C組成的矩陣,其中D為數據塊(data block),C為校驗塊(parity block)。我們的數據寫入都需要經過編碼後才能進行存儲。
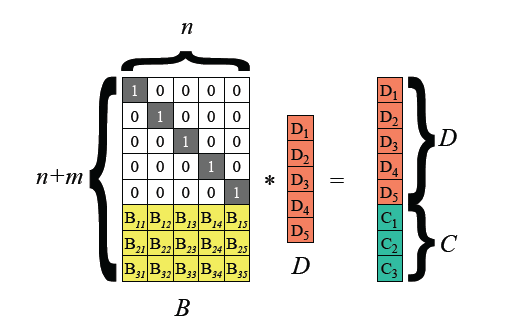
假設我們抹除掉了D1,D4,C2。
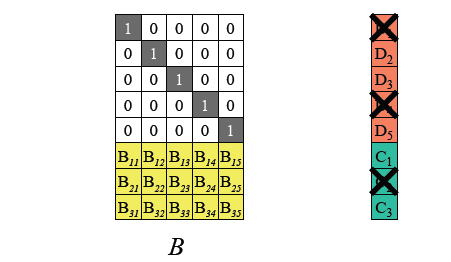
我們能通過編碼矩陣得到一個用於恢復的矩陣,將這個矩陣與剩餘塊相乘,可得到原來完整的輸入數據,再次進行編碼後可恢復C2。
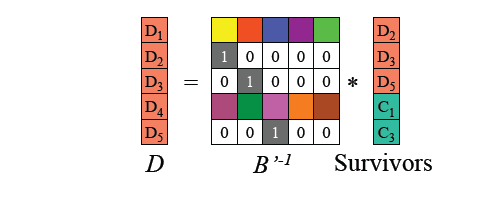
二、存儲佈局的改變
EC編碼對HDFS的應用,使數據塊存儲的結構發生了改變。
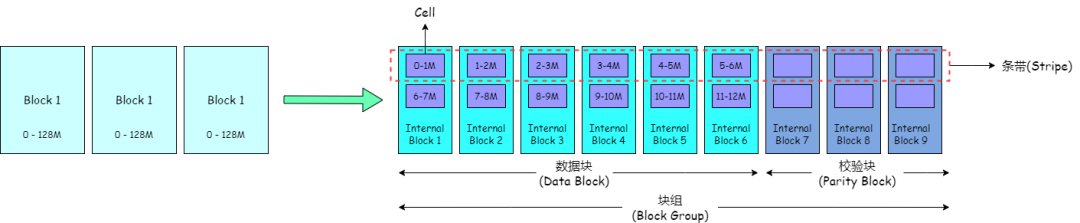
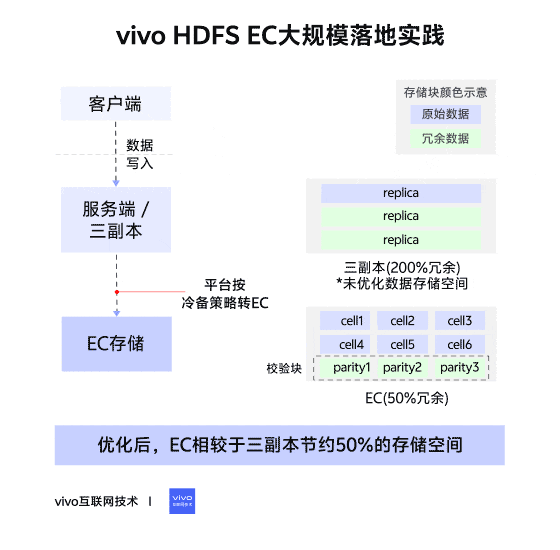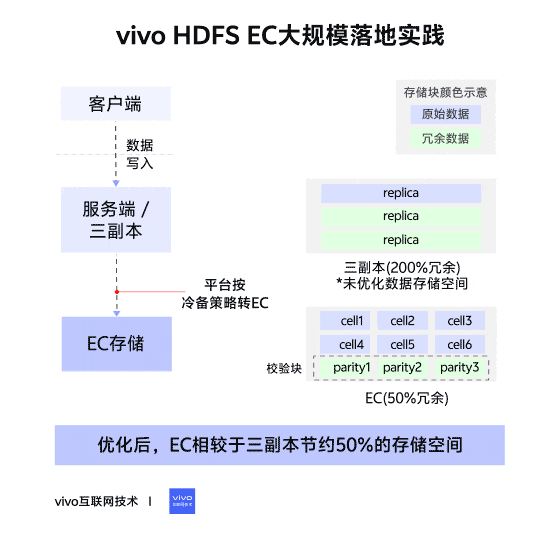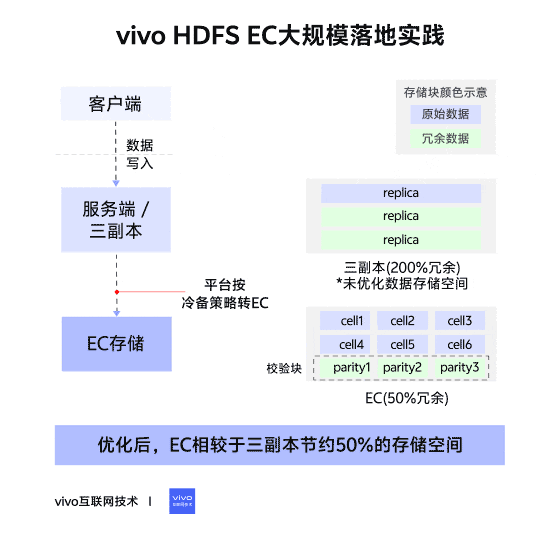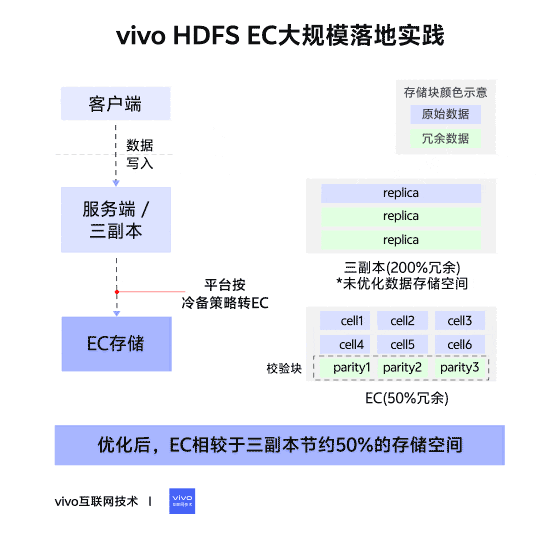
在傳統三副本的策略中,一個文件被劃分為不同的塊(block)進行存儲,一個數據塊對應三個副本(replication),每個副本存儲的內容完全一致,數據的存儲時連續的,這種佈局稱為連續塊存儲佈局(Contigous Block Layout)。
在EC策略中,一個文件被劃分為不同的塊組(Block Group)進行存儲,一個塊組內劃分為多個內部塊(Internal Block),其中,內部塊又分為數據塊(Data Block)和校驗塊(Parity Block)。數據塊存儲文件的數據,校驗塊存儲由數據塊生成的校驗內容。一個塊組內,可容忍的塊丟失數量與校驗塊數量相同,如果丟失塊的數量大於校驗塊數量,則數據不可被恢復。
在塊組中,數據並不像三副本策略一樣連續存儲在一個塊中,而是將連續的數據拆分為多個Cell,分散存儲在不同的內部塊中,形成一個個條帶(Stripe)。這種佈局稱為條帶存儲佈局(Striped Block Layout)。
我們集羣目前採用EC策略RS6-3-1024k,其中6表示塊組中數據塊數量,3表示塊組中校驗塊數量,1024k表示Cell大小。
三副本是HDFS默認的冗餘存儲方式,優點是當有機器宕機,數據丟失時,不會影響用户的讀取,補塊的方式也僅僅是副本的複製,簡單高效。缺點也很明顯,存儲的冗餘度高,三副本的存儲冗餘度達到200%。
EC編碼通過編碼的存儲方式,來進行冗餘存儲。優點是存儲的冗餘度低(具體的冗餘度取決於不同的存儲策略),可靠性高。缺點是寫入需要編碼,造成性能的下降(大概3-4倍),補塊時間長(校驗塊越多,補塊時間越長),讀取時如果遇到DN宕機,也需要額外的資源與時間進行解碼恢復。
三、HDFS EC 碼應用實踐
3.1 兼容性問題
3.1.1 服務端
早在2020年,EC已經在vivo的HDFS集羣中投入使用。EC是Hadoop3.0後推出的新特性,要想正常使用,服務端和客户端都需要升級到3.0或以上版本。
由於離線集羣規模龐大,升級的調研和實施需要耗費比較長的時間。因此,我們臨時搭建了一套基於3.1版本的冷備專用集羣,使用EC來存儲冷備數據,如下圖:
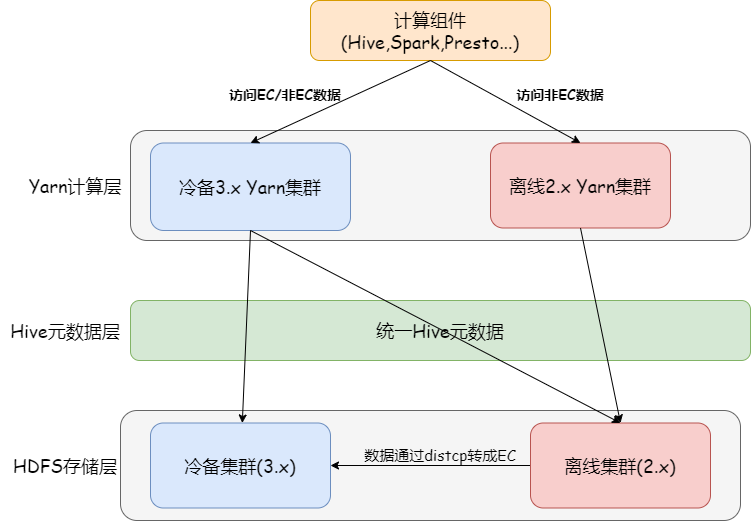
冷備集羣使用3.1版本的Yarn,可以同時訪問熱數據與冷數據,3.1版本的HDFS專門用來存儲EC編碼的冷數據。
由於新增冷備集羣的方案增加了集羣運維的成本,架構也不夠優雅,只是暫時的解決辦法。在2021年,我們離線集羣完成了HDFS從2.6到3.1的全面升級,正式支持EC編碼,在2022年,我們完成絕大部分冷備集羣的數據到離線集羣的遷移,增量數據全部寫到離線集羣中。
3.1.2 客户端
我們沒有對Client2.x客户端訪問EC文件做兼容性的開發,更多是通過推動用户升級客户端來訪問EC文件,例如Spark2任務切換至Spark3任務。該方案增加了用户遷移的成本,但同時也減少了HDFS側的開發成本,用户任務逐步往Spark3遷移也更符合未來的規劃。
3.2 EC 異步轉換
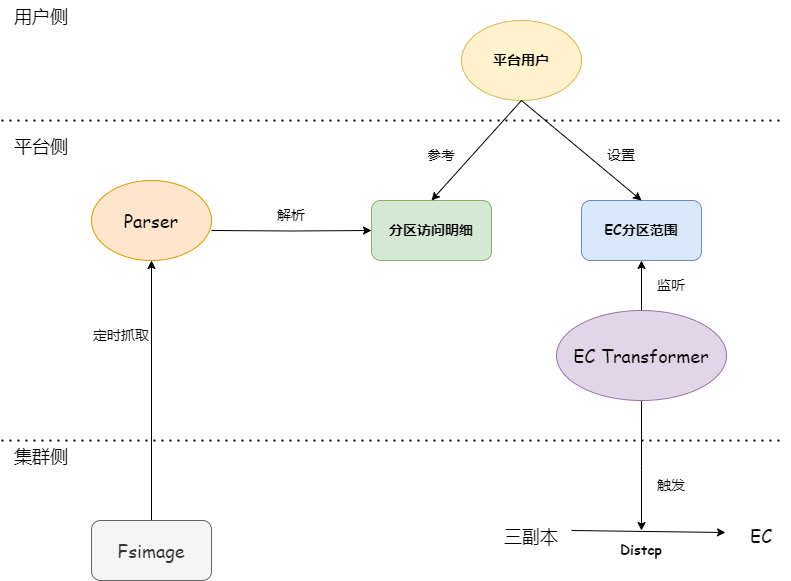
由於EC編碼會帶來對文件讀寫性能的下降,對EC編碼的定位主要應用在冷數據的存儲,業務並不直接寫EC數據,而是採用後台轉儲的方式,把三副本數據轉儲成EC數據。對不同業務而言,對"冷"的標準都不一致,不能用統一的標準來衡量數據的冷熱。在推廣EC編碼的過程中,平台並不用統一的標準來“強制”把用户數據轉為EC,是否轉為EC的最終決定權在用户。我們向用户提供分區訪問頻率的數據作為參考,幫助用户來了解不同分區路徑的訪問頻次,讓用户更好地選擇哪些分區轉為EC編碼。用户可以通過大數據開發者平台(Big data developer platform)設置x天前的數據轉為EC存儲,後台程序會將相應分區通過Hadoop distcp,將三副本寫入到已設置EC策略的目錄中,再用新目錄替換掉原目錄,其中目錄名稱不變,保證了元數據一致,用户無需修改代碼。
3.3 Distcp 數據校驗
先來介紹一下HDFS兩種校驗和的方式。
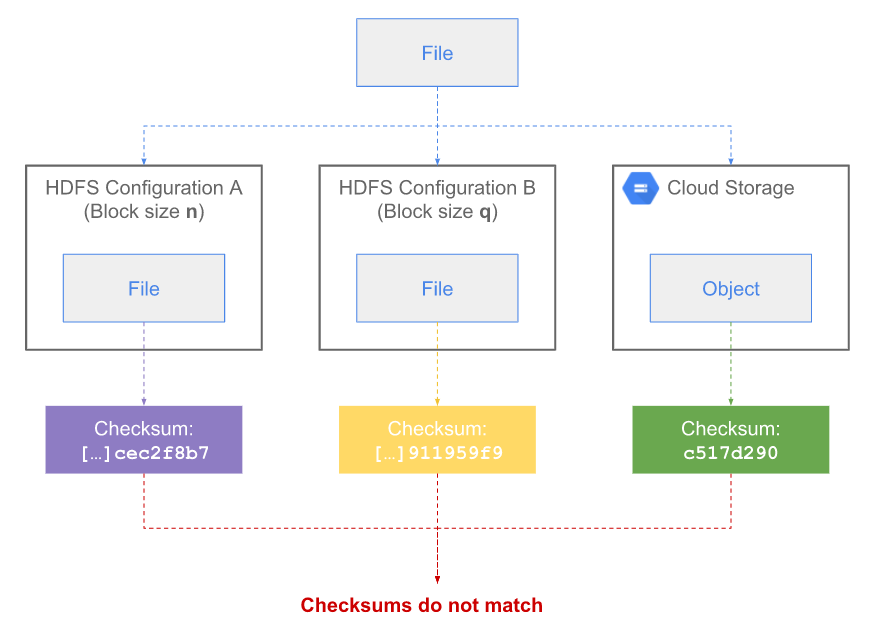
3.3.1 MD5MD5CRC
此方式為HDFS默認的校驗方式,這種校驗方式會進行兩次MD5計算一次CRC計算,從名字就可以反映出來。
-
塊級校驗和:所有chunk CRC的級聯的MD5值。(an MD5 of a concatenation of chunk CRCs)
-
文件級校驗和:所有塊校驗和的級聯的MD5值。(the MD5 of the concatenation of all the block checksums)
由定義可知,這種方式對於HDFS分塊大小敏感,不同的分塊大小塊級校驗和不一樣,導致文件校驗和也會不一樣。
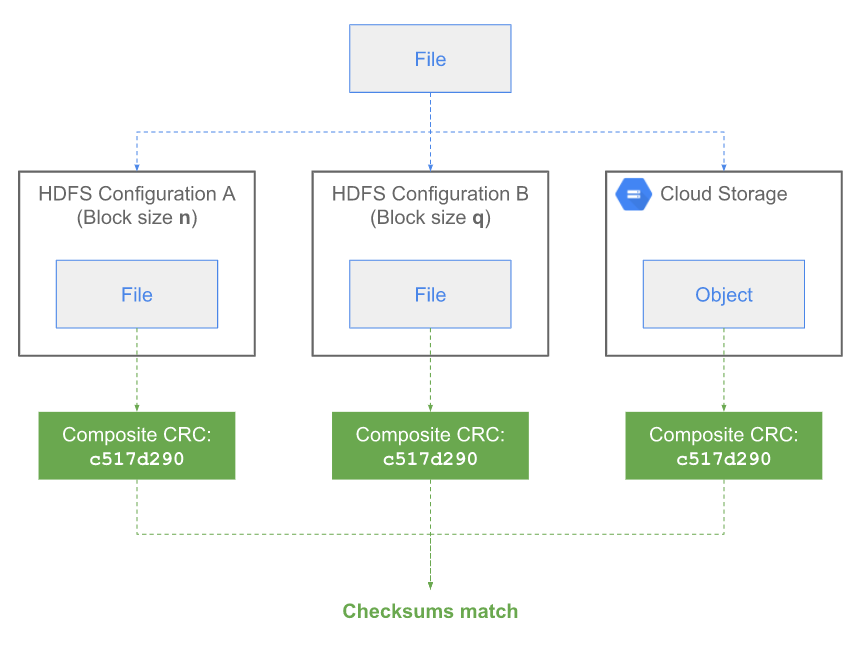
3.3.2 Composite CRC
Composite CRC一個新的校驗和計算方式。
當計算塊校驗和不是簡單地將chunk CRC進行級聯(concatenation),而是將chunk CRC進行數學式的組合(mathematically compose),計算文件校驗和時對文件所有的chunk CRC進行數學式組合。因此,對於文件校驗和,該計算方式對於分塊大小並不敏感。 CRC算法相關論文。
在數據進行distcp的過程中,HDFS會進行校驗和校驗,確保distcp的源數據與新數據一致,但正如前文所説,EC編碼會帶來存儲佈局的改變,相同的文件三副本與EC數據存儲的塊大小,塊數量都不一致,這讓HDFS默認的MD5MD5CRC的方式變得不再適用。
需要將校驗方式改為COMPOSITE CRC。
可通過 dfs.checksum.combine.mode 改變校驗和校驗的方式(MD5MD5CRC(默認值) or COMPOSITE_CRC)。
即使distcp過程中會進行校驗,為了確保萬無一失,我們還會對前後的分區目錄的校驗和校驗。(目錄校驗和計算方式為將目錄下文件MD5值排序,再進行MD5計算)為了保證轉EC前後文件的一致性,多加一道校驗的"工序"是值得的。
3.4 文件損壞與修復
文件損壞與丟塊是HDFS EC應用繞不開的一個話題,原因是在Hadoop EC特性新推出的過程中,有若干與文件損壞相關的bug。EC文件損壞的過程主要發生在補塊階段,計算結果的不準確導致了新補的塊與原來的塊內容不一致。我們在EC推廣的過程中,也狠狠地踩過文件損壞的“坑”。如何避免文件損壞,如何對補塊的結果進行校驗,如何修復損壞文件是三個重要的需要解決的問題。
3.4.1 如何避免文件損壞
通過對社區的調研,我們打了若干的patch來解決文件損壞與丟塊的問題。
3.4.2 對補塊結果的校驗
我們引入了HDFS-15759,Patch提供了一個對EC補塊的校驗功能,在DN執行補塊任務時,對補塊結果進行校驗。如果校驗失敗會拋出異常,並且補塊任務會進行重試。
3.4.3 EC批量校驗工具
我們對開源的EC批量校驗工具進行了定製化的改造,工具能夠對EC目錄進行批量掃描,掃描出目錄中的損壞的EC文件,在此感謝Stephen O'Donnell對工具的開源。
原理大致如下,對數據塊進行EC編碼,通過比對新生成的校驗塊和原來的校驗塊,來驗證是否存在文件損壞。如果比對通過,則沒有文件損壞,如果比對不通過,則存在文件損壞。
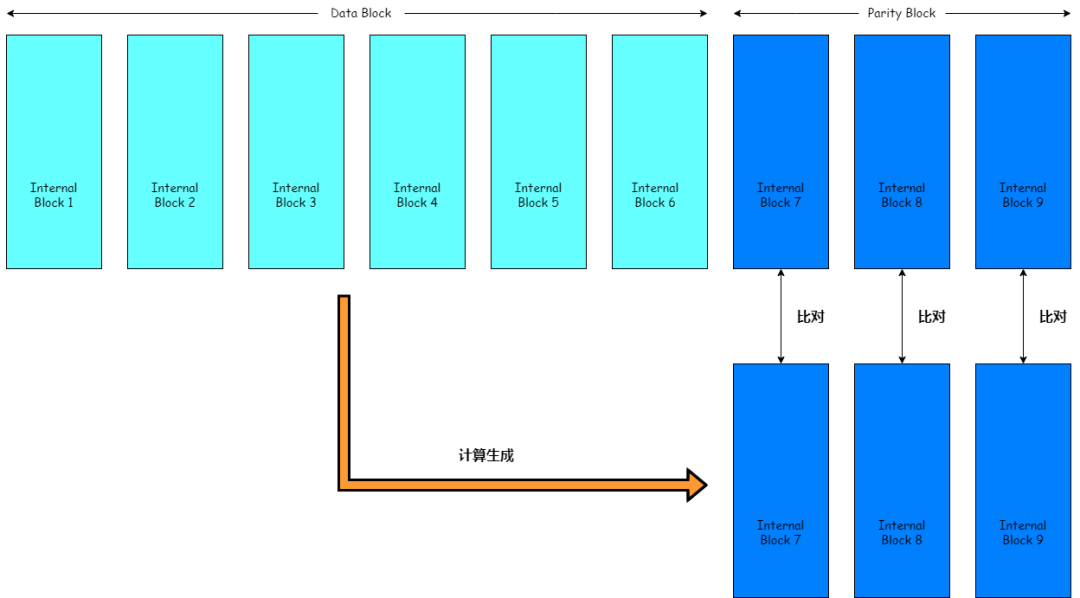
工具支持MR,可以分佈式執行,此外,也可只對一個條帶進行比對,只生成校驗塊的第一個條帶,比對與原校驗塊第一個條帶是否一致,這些都大大提高了批量校驗EC文件的效率。
工具地址:
https://github.com/sodonnel/hdfs-ec-validator
3.4.4 修復損壞文件
在我們的集羣,絕大部分損壞的文件都是ORC文件,ORC文件發生損壞時,由於其元數據分佈的方式,會出現元數據的損壞,ORC無法解析。
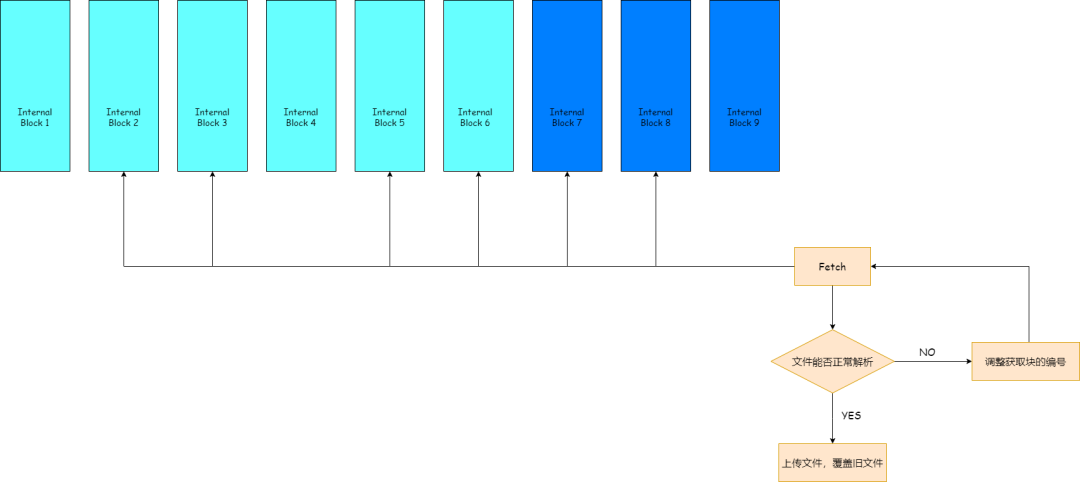
假設一個塊組內,數據塊編號為1~6,校驗塊編號為7~9,數據塊1損壞,我們可以通過讀取數據塊2~6加上任一一個校驗塊,得到"完好"的文件,對於ORC文件而言,判斷是否完好取決於能否正常解析。
HDFS客户端get文件的時候默認只會讀取數據塊,我們通過改造HDFS客户端,使我們能夠讀取塊組內指定編號的塊,通過各種排列組合,得到一個"完好"的文件,之後將"完好"的文件覆蓋掉HDFS上的損壞文件,來達到文件修復的目的。
3.5 機器異構&存儲策略
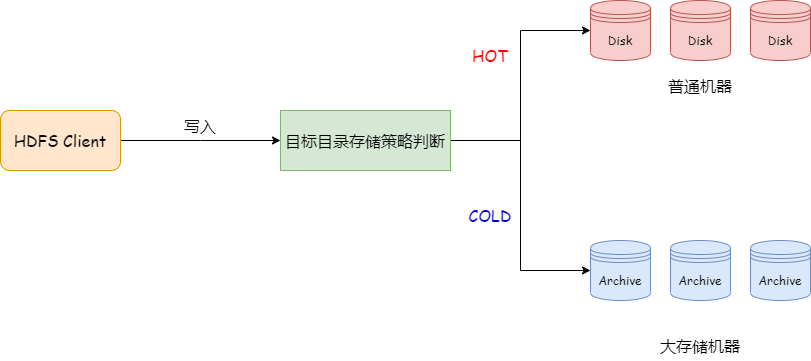
由於EC數據訪問頻率低,將EC數據存儲到大存儲的機器上,利用機器異構降低我們的單位存儲成本。
在HDFS中,如果文件寫入的路徑設置了hot存儲策略的目錄,則會優先把文件存儲到disk存儲介質當中,如果設置了cold存儲策略的目錄,則會優先把文件存儲到archive存儲介質當中。
因此,當我們將大存儲機器的盤都設置為Archive,並且將EC目錄設置為Cold存儲策略,即可將EC數據存放到大存儲機器上,使TCO降低,進一步實現存儲降本。
四、總結與展望
vivo的HDFS集羣已存有幾百PB的數據採用EC-RS6-3-1024k策略存儲,相比三副本EC-RS6-3-1024k方式能帶來50%的存儲收益,節省了數百PB的存儲空間,為公司帶來了巨大的收益。目前我們推薦用户將訪問頻次較少的數據轉為EC,因為EC會帶來讀取性能的下降,如何減少EC帶來的讀取性能下降?以及後續細化對用户數據的冷熱分層,對越冷的數據採用冗餘度越低的EC策略,EC補塊速度優化等,都是後續繼續大規模推進EC需要解決的重要難題。
