








1,應用場景
SQLServer中一個大表(測試環境千萬級,實際情況下會更多,達到10億級),刪除其中大部分數據。然後測試分批多次刪除和一次性全部刪除產生的transaction log的日誌大小的問題。
另:受限於相關的表做了複製分發,因此無法通過備份部分數據後truncate table的方式來實現,也無法通過新建一個表,通過rename的方式來交換實現,這兩種方式不再考慮範圍之內,也不是本文的重點。
以下為生成測試數據庫前置條件:
1,數據庫為SQLServer 2019標準版
2,測試文件所在的磁盤為普通普通SSD(非NVME類型SSD)
3,創建兩個一樣的數據庫,保持數據庫的初始大小,增長大小一致;日誌的初始大小,增長大小一致,兩個數據庫均為full recovery模式
4,兩個庫中定義完全一樣的表,寫入完全一致的測試數據,最低1000W起步,否則測試意義不大
以下為測試腳本
USE [master]
GO
CREATE DATABASE [TransactionTest_01] ON PRIMARY
( NAME = N'TransactionTest_01_Data', FILENAME = N'D:\MSSQL\Data\TransactionTest_01.mdf' , SIZE = 32768KB , MAXSIZE = UNLIMITED, FILEGROWTH = 32768KB)
LOG ON
( NAME = N'TransactionTest_01_Log', FILENAME = N'D:\MSSQL\Log\TransactionTest_01_Log.ldf' , SIZE = 65536KB , MAXSIZE = UNLIMITED, FILEGROWTH = 131072KB )
GO
USE [master]
GO
CREATE DATABASE [TransactionTest_02] ON PRIMARY
( NAME = N'TransactionTest_02_Data', FILENAME = N'D:\MSSQL\Data\TransactionTest_02.mdf' , SIZE = 32768KB , MAXSIZE = UNLIMITED, FILEGROWTH = 32768KB)
LOG ON
( NAME = N'TransactionTest_02_Log', FILENAME = N'D:\MSSQL\Log\TransactionTest_02_Log.ldf' , SIZE = 65536KB , MAXSIZE = UNLIMITED, FILEGROWTH = 131072KB )
GO
use [TransactionTest_01]
go
create table test01
(
c1 int identity(1,1),
c2 varchar(100),
c3 varchar(100),
c4 varchar(100),
c5 varchar(100),
c6 varchar(100),
c7 varchar(100),
c8 varchar(100),
c9 varchar(100),
c10 datetime2,
constraint pk_test01 primary key(c1)
);
use [TransactionTest_02]
go
create table test01
(
c1 int identity(1,1),
c2 varchar(100),
c3 varchar(100),
c4 varchar(100),
c5 varchar(100),
c6 varchar(100),
c7 varchar(100),
c8 varchar(100),
c9 varchar(100),
c10 datetime2,
constraint pk_test01 primary key(c1)
);
go
--生成測試數據,這裏是5千萬,如果磁盤太慢或者其他原因,可以減小@i參數的值,少生成一些數據
declare @i int = 0
begin tran;
while @i<50000000
begin
declare @var varchar(100) = newid();
declare @currentdatetime datetime2 = sysdatetime();
insert into TransactionTest_01..test01 values (@var,@var,@var,@var,@var,@var,@var,@var,@currentdatetime);
insert into TransactionTest_02..test01 values (@var,@var,@var,@var,@var,@var,@var,@var,@currentdatetime);
set @i = @i + 1;
if @i%10000=0
begin
commit;
begin tran;
end
end
if @@trancount > 0
commit;
go
--驗證數據的一致性
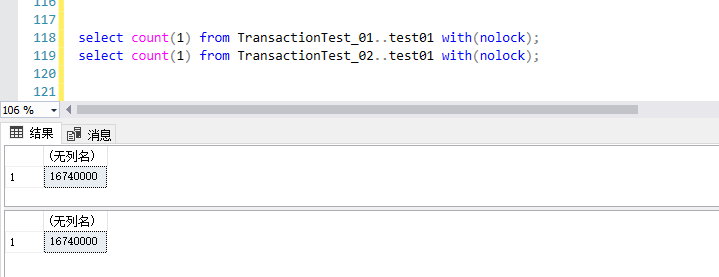
select count(1) from TransactionTest_01..test01 with(nolock);
select count(1) from TransactionTest_02..test01 with(nolock);
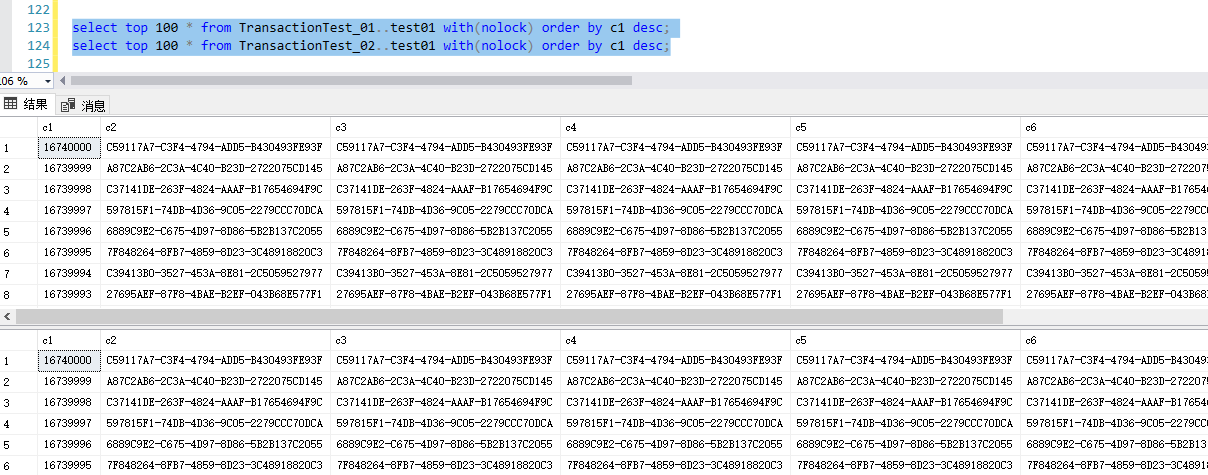
select top 100 * from TransactionTest_01..test01 with(nolock) order by c1 desc;
select top 100 * from TransactionTest_02..test01 with(nolock) order by c1 desc;
場景1:
--批量刪除,執行前重啓SQLServer服務
while 1>0
begin
delete top (5000) from TransactionTest_01..test01 where c1 < 15740000
if @@rowcount=0
begin
break
end
end
場景2:
--全量刪除,執行前重啓SQLServer服務
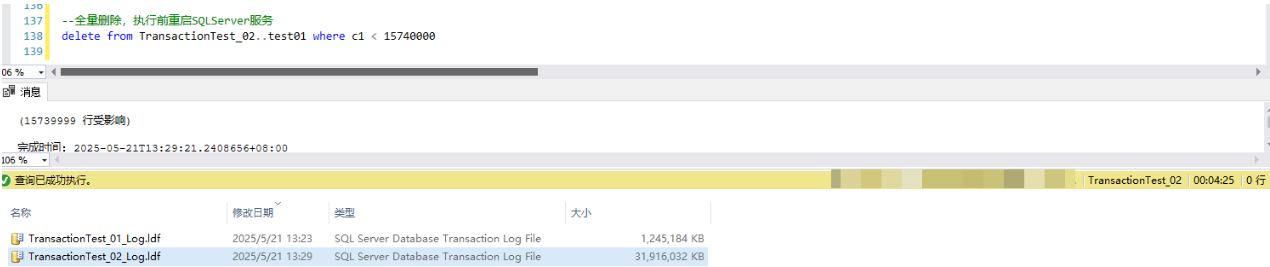
delete from TransactionTest_02..test01 where c1 < 15740000以下為生成的測試數據(受時間限制,僅生成了16百萬的數據):
2,測試數據
兩個庫中,生成測試數據後,測試表的數據庫完全一致
3,測試數據庫的文件大小
兩個庫中,生成測試數據之後,測試數據的數據文件和日誌文件完全一致。


4,刪除數據後的事務日誌大小(刪除前後均不做事務日誌備份)
4.1,批量刪除測試庫1中的數據,事務日誌增加了400MB左右
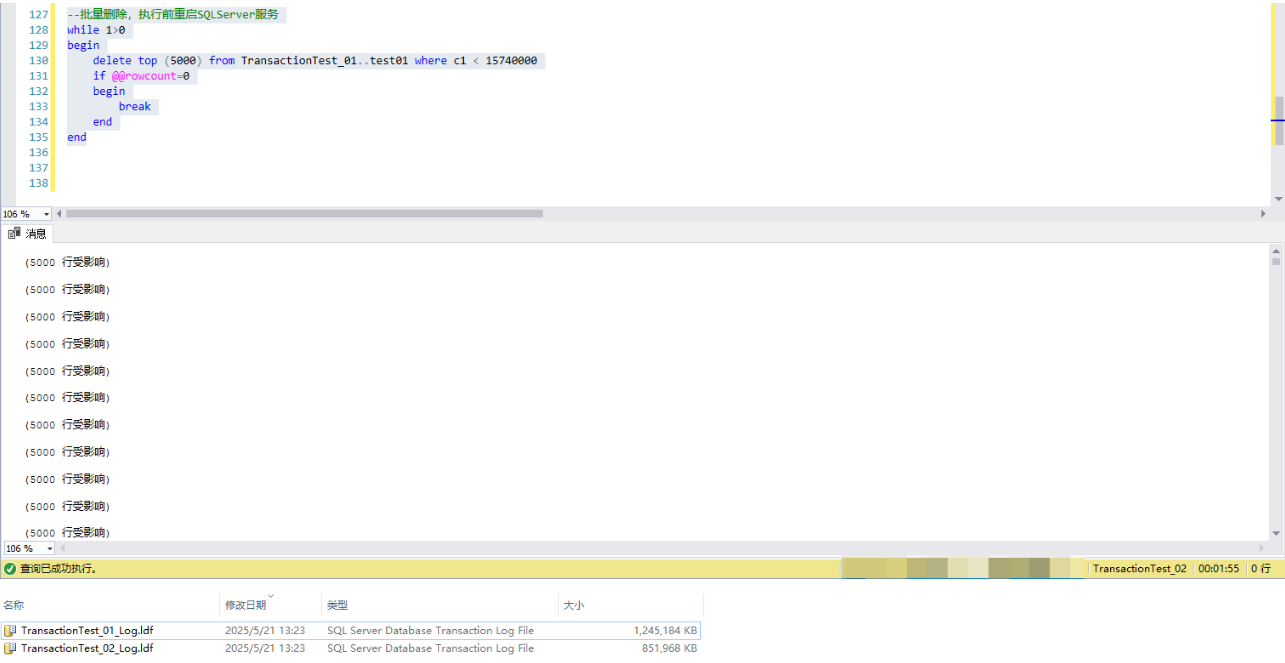
4.2,整體刪數測試庫2中的數據,事務日誌增加了31G左右
5,結論
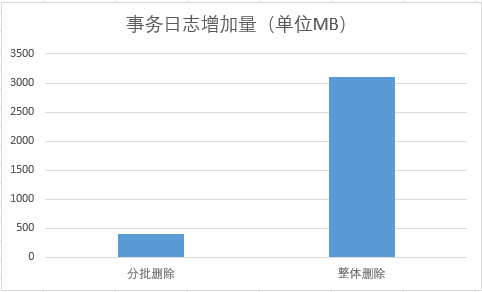
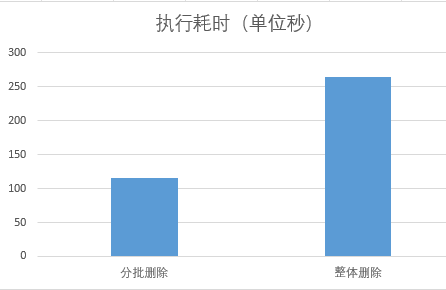
對於完全一樣的表,通過分批多次刪除,和一次性刪除,刪除同樣多的數據的情況下:
1,事務日誌增長量400MB VS 31000MB,
2,執行耗時,115秒 VS 265秒
6,相關參考
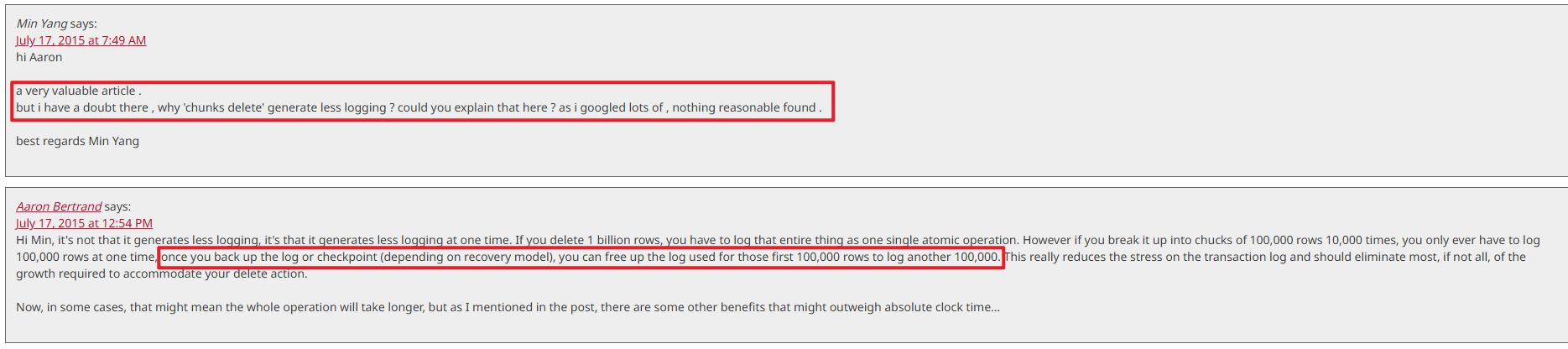
這裏有一篇相關性的文章,已經有十幾年了,Break large delete operations into chunks(https://sqlperformance.com/2013/03/io-subsystem/chunk-deletes),也提到單次刪除和分批刪出的差異性,這篇文測試了很多的場景。
下面這個場景跟本文的場景類似:full recovery模式,單次刪除和分批多次刪除的對比,
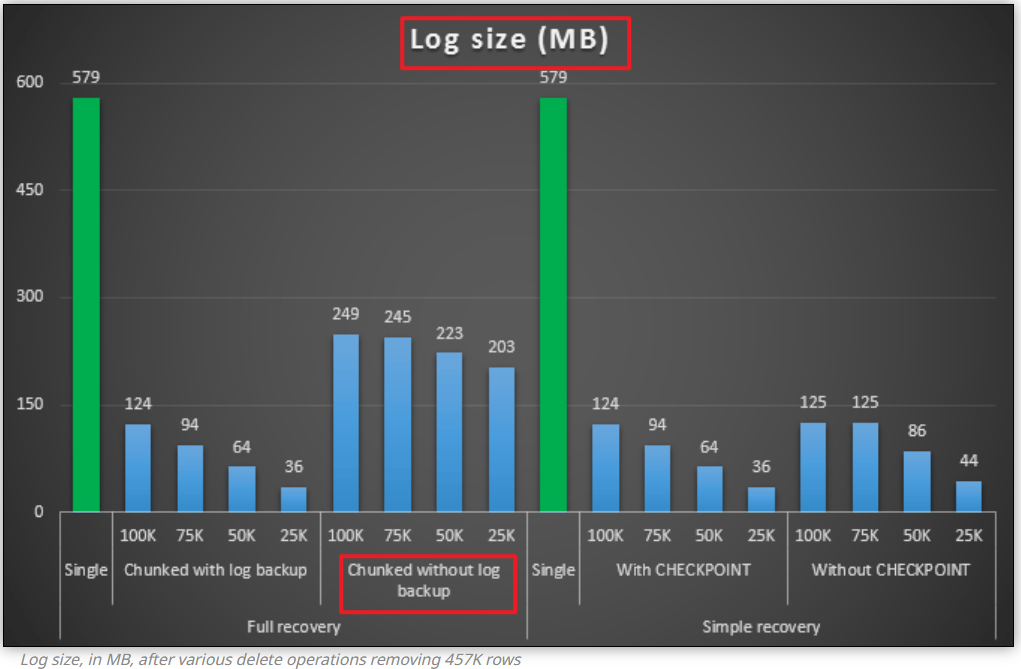
文章的評論區有人問道:why 'chunks delete' generate less logging但回答是説批量刪除備份日誌,然後日誌重用,這個回答並沒有解釋,在如上圖的測試結果中,為什麼沒有日誌備份的情況下,批量刪除的日誌量遠小於單次刪除
最終也沒有解釋出來根本原因:完整恢復模式下,不做日誌備份,刪除同樣多的數據,單次刪除和批量多次刪除事務日誌差異性的原因。
希望有看到的大佬指點一二