

https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html
https://www.bilibili.com/video/BV1US4y1m7if/?spm_id_from=333.337.search-card.all.click&vd_source=99ec55b57f4eeedd9ed62c43e87cb6ff

什麼是虛擬機
java分配了內存之後,自己是不要進行回收的。c和c++要手動回收,會出現重複回收或忘記回收。
虛擬機層面做了一個自動化回收,有10種。java1.8默認的是PS和PO。1.9之後默認G1。
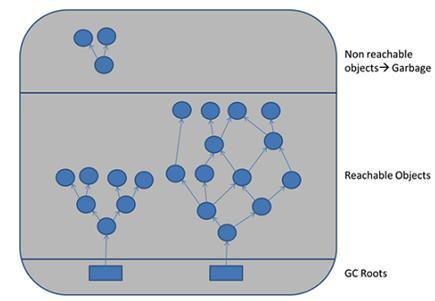
java中定位內存裏什麼是垃圾用的方法是Root Searching根可達,只要順着“小線團“能找到的都不是垃圾。
什麼是GC Roots?main裏面的用到的一定有用。
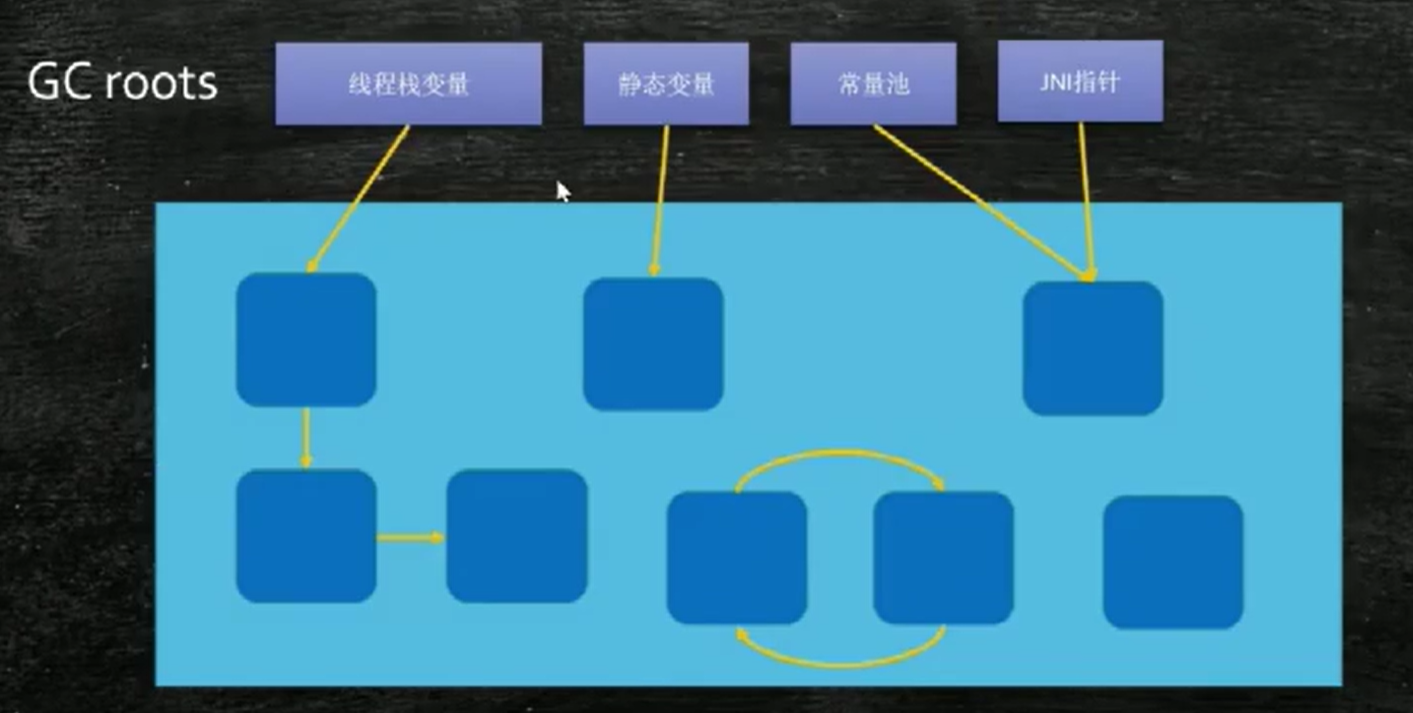
一個對象怎麼才能知道它是一個垃圾?在一個對象頂上寫一個reference count引用計數,如果有其他人引用他則肯定不是垃圾,當一個引用消失,數量就-1。但這種方式有bug,循環引用。在java中我們用了另一種方法定位Root Searching根可達算法,一個方法是從main方法開始運行,在main裏面,new出來的對象(如list,list裏面又可以裝很多對象),順着這個根對象往下找,若有些沒找到的就是垃圾。
垃圾回收算法:標記清除(碎片化)、拷貝(內存浪費)、標記壓縮。
- 標記清除:找出來哪些是垃圾,直接清除,變為可用。簡單,但會有內存碎片。
- 拷貝算法:不管內存多大,把內存分成兩半,每次只使用一半,從在使用的一半里面把活對象拷貝到另一半,然後把原本的區域全部清空。兩邊輪流使用。沒有內存碎片,但浪費了很多空間。
- 標記壓縮:既不產生碎片,又不浪費空間。先標記,然後把活的整理到最前面,然後把後面的都清除。但是效率很低,挪來挪去。
GC的演化是隨着內存的變大而改變。
- 幾兆-幾十兆:serial單線程STW垃圾回收,年輕代、老年代
- 幾十兆-上百兆1G:parallel並行多線程
- 幾十G:concurrent GC
一個垃圾回收器的設計是綜合這三種垃圾回收算法。
1.8裏面用的最多的是分代管理方法,STW是毫秒級。
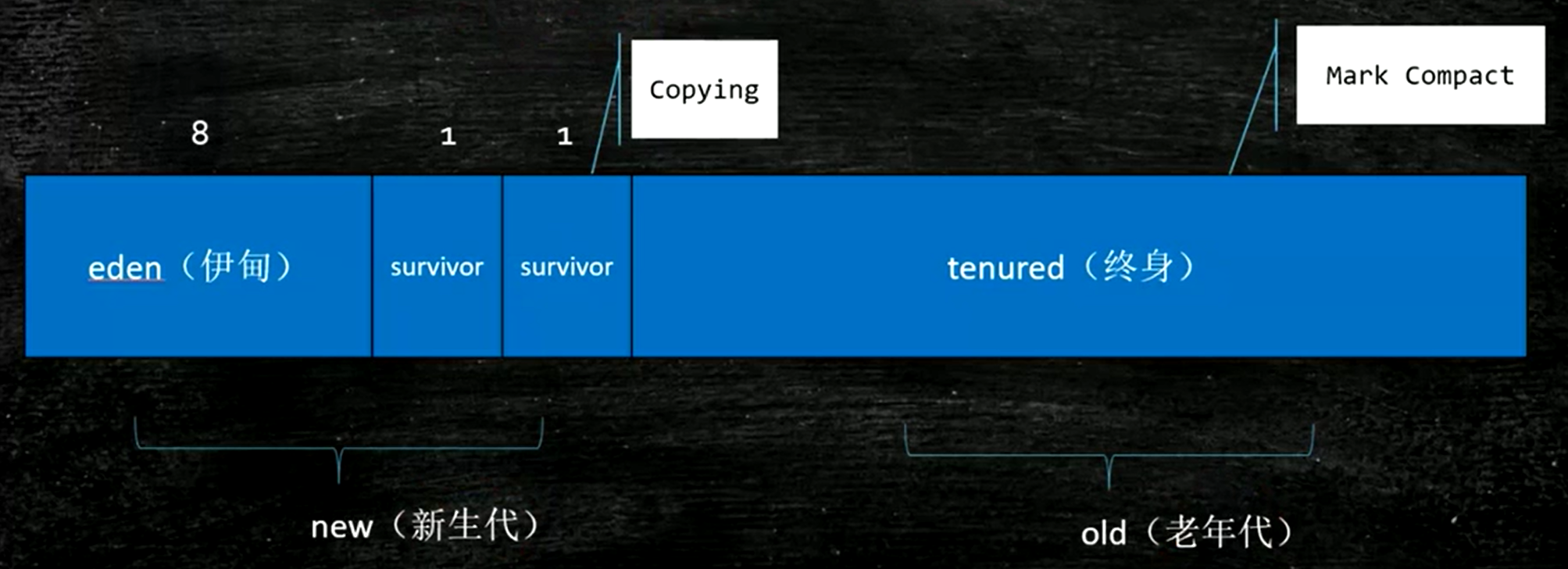
堆內存邏輯分區分為新生代和老年代(大約為1:2的比例,默認),當一個對象誕生的時候,優先在新生代做分配,每個對象會經歷很多次的垃圾回收。那些經歷了很多次垃圾回收都回收不掉的就移到老年代去。等老年代裝滿了就會有針對老年代具體的垃圾回收方法。
JVM調優調的是用各種參數指定這兩個區域的比例。越新的垃圾回收器調優越簡單,但理論就會複雜些。
那年輕代到多少年齡之後就會挪到老年代呢?這個跟使用的垃圾回收算法相關,默認是PS+PO,年齡是15,如果有改動為CMS,年齡為6,G1沒有年齡這個概念因為不分代了。-XX:MaxTenuringThreshold配置
伊甸園區:新創建的對象都放在這。假如現在在伊甸園區有10個對象,經過一次垃圾回收YGC之後幹掉了9個,那麼僅剩的那一個怎麼處理?這個對象會被複制到一個survivor,這樣伊甸園區可以整體清除(效率高)。然後下一次在伊甸園區又產生了一些垃圾,然後跟前面類似的做法進行一次YGC,將伊甸園區活着的對象和survivor1中活着的對象移到survivor2中,然後將eden和survivor1全部清除。不能移動而是複製。下一次就將活的複製到survivor1中。這兩片倖存者空間肯定有一塊是空的。
YGC(發生在年輕代的GC)+LGC(發生在老年代的GC)=FullGC。
那如果survivor不夠大了怎麼辦?默認的eden和survivor的比例是8:1:1。YGC的要求就是效率高。用複製算法(在新生代區):統計學結果發現YGC一般能回收掉90%的對象。原本的複製算法是預留一半的內存,但這樣會浪費,新的方法就不預留那麼多的空間。
在分代的基礎上產生了6種垃圾回收器:Serial、ParNew、Parallel Scavenge(YGC)、CMS、Serial Old、Parallel Old(OGC)。
Serial:只有一個人來幫你回收垃圾。STW是不可避免的。
STW:業務線程不能動,等垃圾回收完了之後才可以繼續主線程。
虛擬機追求:吞吐量、響應時間(我們要關注的)。
隨着內存變大,serial就不太行了。Parallel Scavenge:多線程,但線程數不是越多越好,因為有線程切換過程。到一定的閾值的時候,誕生了一種併發垃圾回收CMS。
CMS(Concurrent Mark Sweep):由於響應時間越來越高。響應時間長的可能會到2天多。就是在運行業務線程的時候不用STW,與此同時會有垃圾回收器幫你回收垃圾。
怎麼知道是在GC?傳統的方式是日誌,監控,JDK14(JFR java事件流)
CMS可以升級成G1(1.8以上)。
java中最複雜的垃圾回收器的算法:三色標記法。
- 黑色:自己和孩子都找到了
- 灰色:孩子沒找全
- 白色:完全沒找到
老年代不能在全部滿了之後才啓動垃圾回收,有參數可以設置達到多少比例就啓動,以前有默認比例是90%,但是這時候已經晚了。當老年代空間滿了之後會啓動STW,用單線程去進行垃圾回收。
第一種情況:A-B引用消失
第二種情況:B-D消失 A-D增加。通過A找不到D,B又找不到D。所以D在垃圾回收器視角看起來就是垃圾(因為A是黑色),但這裏如果垃圾回收器把這個D刪除了,那會發生空指針異常。
CMS解決方案:如果發生了情況二,那就把黑色A標為灰色,這樣垃圾回收器就會找A的孩子。但這個方案有個bug,就是xxx。CMS最後有一個階段叫做remark。
CMS中有浮動垃圾,而且在remark階段會有STW,在業務很複雜的時候時間可能很長。
G1:SATB,有一個灰的對象在運行過程中指向白的引用消失了,把這個引用記錄在棧裏面。當垃圾回收線程回來時,只要看在那個棧中有沒有新記錄誕生,然後就掃一下看有沒有其他對象引用這個白的,如果沒有的話就是垃圾。
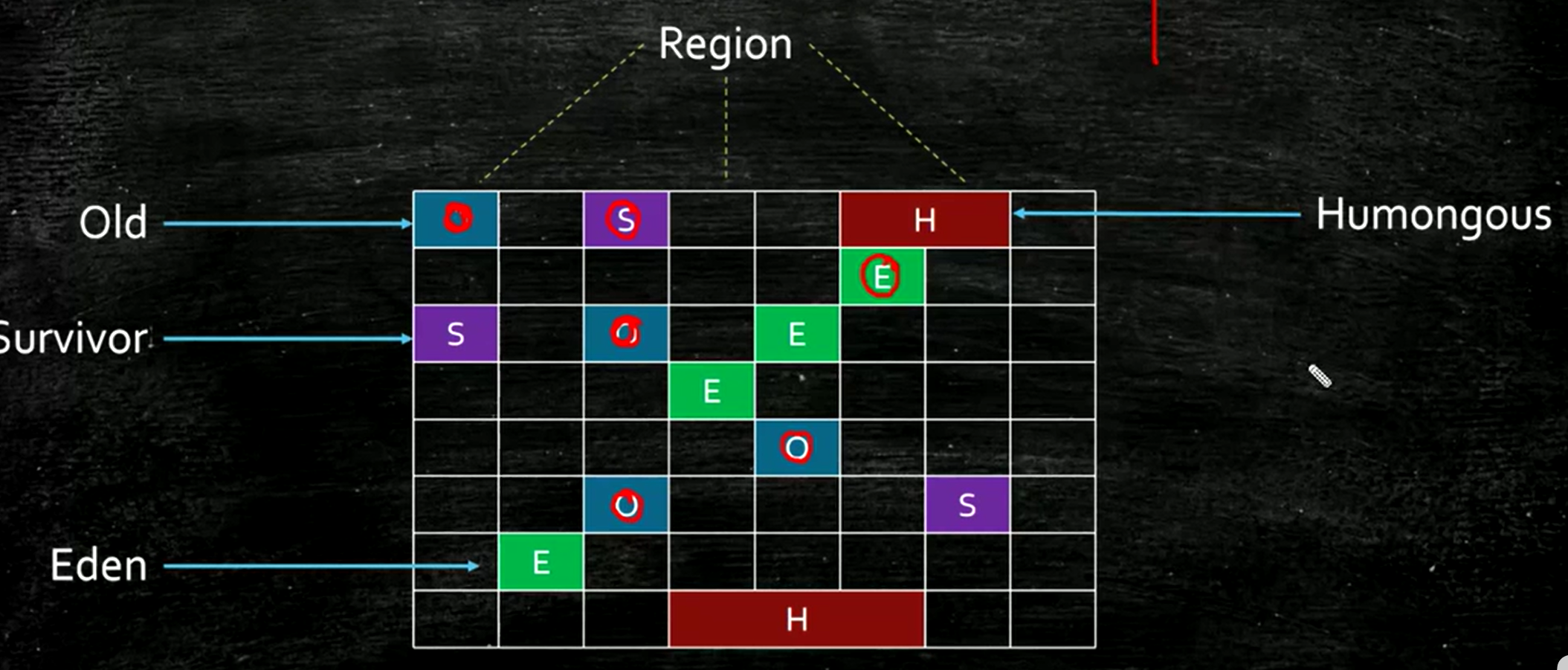
G1:在物理上分區,在邏輯上分代。ZGC:純分區,不分代。在某個區域不夠用的時候,可以把它動態置為其他的區域,比如新生代產生很快的話可以把清空了的區域指定為伊甸園區。
G1追求吞吐量和響應時間(XX:MaxGCPauseMillis 200),對STW進行控制。靈活,分region回收,優先回收花費時間少、垃圾比例高的Region。
G1一般不用手動指定新老年代比例,如果你精確地掌握程序就可以修改,否則不建議修改。G1預測停頓時間的基準。我們只需指定需要將STW控制在多少,而不需要管裏面具體的細節。
工作之後用的JVM版本大多是1.8,默認的垃圾回收器是並行垃圾回收器。目前垃圾回收器可以分為兩大類,一類是分代模型,兩個垃圾回收器混合使用;二類是分區模型。
java -XX:+PrintCommandLineFlags -version 會顯示默認垃圾回收器。
jvm調優:在啓動了java虛擬機之後,進行一系列參數的指定,讓jvm運行在最佳狀態。作為java虛擬機,有多少參數可以調節呢?標準參數10-20個,非標參數有幾十個。常用的有-xmx,-xms。還有不穩定參數,每個垃圾回收器是不同的參數來控制,-XX:PrintFlagsFinal | more,參數非常多,728行。
Serial和SerialOld成對使用,Serial在年輕代使用(複製算法)、SerialOld在老年代使用(標記清除或標記整理),但現在已經不用了,特點是簡單,但問題是效率很低,隨着內存變大,STW時間很長。
Parallel Scavenge和 Parallel Old成對使用,解決小內存的問題。但線程不能太多,線程切換有很大開銷。
JVM調優實戰
涉及到三個層面,根據需求進行JVM規劃和預調優(多大的併發量、峯值到多少,使用什麼垃圾回收器,多大內存等);第二個是優化運行JVM運行環境(慢卡頓,遊戲服務器經常遇到);第三個是解決JVM運行過程中出現的各種問題(OOM)
舉個例子:金融領域風險控制模型,使用了線程池進行風險控制模型的計算。
(GC的日誌)java -Xms200M -Xmx200M -XX:+PrintGC com.mashibing.jvm.gc.T15_FullGC_Problen01, 最大內存200M,最小內存200M,為什麼設置為一樣的?因為這樣會使得這個空間彈性擴縮容,會消耗系統的時間。
常用工具:1)linux自帶的命令和JDK自帶的命令 2)使用專業的工具阿爾薩斯(阿里) 3)圖形界面遠程連接 JProfile、Jconsole,離線MAT
jps:看看有哪些進程,會列出線程號和線程名。
top -Hp 1574:把1574進程裏所有線程列出來,線程佔的cpu和內存。
jstack 1574:把程序中所有的線程列出來,如哪個線程產生了死鎖,哪個線程在玩命地消耗cpu、哪個線程阻塞了(阻塞在某一把鎖上面,狀態是waiting)
阿爾薩斯:裝在服務器上,這個工具一旦啓動後就會找到系統中正在跑的java進程。
dashboard:看看有哪些進程,線程佔的cpu和內存都列出來。
thread:把所有線程列出來,假如發現47號線程消耗cpu很多,Thread 47可以查看線程的調用棧。
定位上面那個例子產生的問題:用jdk自帶的命令:jmap -histo 1574 | head -20,有哪些對象在佔用內存列出來,這裏會觀察到有一個bigdecimal的對象在瘋狂佔用內存。再執行幾次這個命令,這個對象佔用內存會越來越多。

第一次清理了40M左右,後面之清理了15M,説明還有好多沒有清理掉。然後等這個日誌,發現越到後面清理的越來越少,因為對象往這裏一直丟對象,已經清理不出空間了,後面會發生頻繁Full GC,內存泄露,中間會出現out of memory error,這樣阿爾薩斯就會斷掉。剩下的就是讀自己的業務邏輯,為什麼這個類在不斷產生。
Java 垃圾回收(Garbage Collection, GC)機制詳解
一、什麼是虛擬機與垃圾回收
Java 程序運行在 Java 虛擬機(JVM)上,JVM 提供了自動內存管理機制,也就是垃圾回收(GC)。相比 C/C++ 的手動內存管理,Java 免去了手動回收內存帶來的煩惱,減少了重複回收或忘記釋放等問題。
二、什麼是垃圾?如何識別垃圾?
在 Java 中,判斷一個對象是否是“垃圾”,核心機制是:GC Roots 可達性分析(Root Searching)。
1. GC Roots 是什麼?
GC Roots 是一組特殊的對象引用集合,是垃圾回收的“起點”。如下內容屬於 GC Roots:
-
棧幀中的局部變量(如 main 方法中的對象)
-
靜態變量
-
常量池中的引用
-
Native 方法中的引用
-
正在運行的線程對象
2. 判斷垃圾的方法
-
引用計數法(Reference Counting)
為對象維護一個引用計數,有引用+1,引用消失-1,為0即為垃圾。
缺點:無法處理循環引用,因此 Java 不採用此方法。
-
可達性分析法(Reachability Analysis)
從 GC Roots 出發,向下遞歸查找能訪問到的對象鏈,如果某個對象無法從任何 GC Roots 到達,就認為是垃圾。
三、常見垃圾回收算法
1. 標記-清除算法(Mark-Sweep)
-
標記:標記出所有可達對象
-
清除:清除未被標記的對象
-
優點:實現簡單
-
缺點:會產生內存碎片
2. 複製算法(Copying)
-
把內存分為兩塊,一次只用一半,把活的對象複製到另一塊
-
優點:無碎片,效率高
-
缺點:浪費內存(只有一半能用)
3. 標記-整理算法(Mark-Compact)
-
標記活對象 → 把它們壓縮到堆的一端 → 清除其他對象
-
優點:無碎片
-
缺點:效率低,挪動對象開銷大
四、JVM 內存分區與分代回收
1. 堆內存邏輯劃分
-
新生代(Young Generation):Eden + Survivor (S0/S1),使用複製算法
-
老年代(Old Generation):使用標記-整理或標記-清除算法
2. 新生代工作機制(YGC)
-
新生代空間比例約為 Eden:Survivor1:Survivor2 = 8:1:1
-
Eden 中創建新對象 → YGC 後將存活對象複製到 S1
-
下一次 GC 將 Eden + S1 存活對象複製到 S2
-
交替使用,始終有一個 Survivor 是空的
3. 老年代回收(OGC)
-
對象在 Survivor 中達到一定年齡(默認 15,CMS 是 6),會被晉升到老年代
-
老年代空間不足時觸發 Full GC
4. Full GC = YGC + OGC
Full GC(完全垃圾回收)是指:對整個堆空間(包括新生代和老年代)進行的一次全面清理操作。相比 YGC(僅回收新生代),Full GC 代價更高,會觸發 Stop-The-World(STW)暫停整個應用線程,因此必須理解它的觸發機制,避免頻繁發生。
下面是 JVM 中最常見的幾種 Full GC 觸發條件:
| 觸發條件 | 説明 |
|---|---|
| 1. 老年代空間不足 | 新生代晉升對象或直接分配到老年代,發現放不下時 |
2. 顯式調用 System.gc() |
會嘗試觸發 Full GC(默認行為) |
| 3. CMS 回收失敗 | Concurrent Mode Failure:CMS 併發回收沒騰出足夠空間 |
| 4. 元空間(Metaspace)不足 | JDK 8+ 元空間爆滿,無法加載新類,觸發 Full GC |
| 5. G1 回收預測失敗 | G1 無法滿足暫停時間預測,選擇進行 Full GC |
| 6. 大對象直接進入老年代 | 導致老年代空間吃緊,觸發 OGC,再帶動 Full GC |
那怎麼樣實操觸發Full GC?
方法1:設置內存限制+持續分配對象。
java -Xms20M -Xmx20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:gc.log GCFullExample
import java.util.ArrayList; public class GCFullExample { public static void main(String[] args) { ArrayList<byte[]> list = new ArrayList<>(); while (true) { list.add(new byte[1024 * 1024]); // 每次分配 1MB try { Thread.sleep(100); // 降低頻率便於觀察 } catch (InterruptedException e) { e.printStackTrace(); } } } }
-
初始創建對象在 Eden
-
多次 YGC 後,有部分對象晉升到老年代
-
老年代空間不夠了 → 觸發 Full GC
怎麼在日誌中看 Full GC?
[Full GC (Ergonomics) ...]
[Full GC (System.gc()) ...]
[Full GC (Allocation Failure) ...]
你可以使用 -Xloggc:gc.log 保存日誌,再上傳到 https://gceasy.io 分析圖表。
五、常見 GC 回收器
1. Serial / Serial Old 收集器(單線程,Client 默認)
-
新生代使用複製算法,老年代使用標記整理算法
-
優點:實現簡單,單線程高效
-
缺點:停頓時間長,STW 明顯
-
參數:
-XX:+UseSerialGC
2. ParNew 收集器(新生代多線程)
-
ParNew 是 Serial 的並行版,僅適用於新生代
-
常與 CMS 搭配使用
-
參數:
-XX:+UseParNewGC
3. Parallel Scavenge / Parallel Old(吞吐量優先)
-
全部並行:新生代和老年代都多線程並行回收
-
特點:關注高吞吐量,適合後台任務
-
參數:
-XX:+UseParallelGC、-XX:+UseParallelOldGC
4. CMS(Concurrent Mark Sweep)
-
CMS(Concurrent Mark Sweep)回收器採用 標記-清除算法,它的核心目標是 減少停頓時間,尤其適合對響應時間敏感的大型服務端應用。CMS 老年代的回收過程分為以下四個階段:
- 初始標記:STW階段,只標記GC Roots可達的第一層對象。標記工作量小,因此暫停時間短。
- 併發標記:與應用線程併發執行,從初始標記的對象繼續向下掃描對象圖,找出可達對象。這個過程時間較長,但不影響用户線程運行。
- 重新標記(remark):CMS中最重要的STW階段之一!修正併發標記階段遺漏的標記變更,因為在併發標記過程中,用户線程可能新增了對象引用,這可能會導致某些對象在併發標記中被誤判為垃圾。為確保準確性,CMS需要在這一步對所有”發生引用變動“的對象進行再次掃描。技術上使用”增量更新:寫屏障機制來記錄這些變動。
-
這一階段如果對象圖很複雜(引用關係多、寫入頻繁),remark 停頓時間可能較長,甚至幾百毫秒以上
-
是 CMS 最大的短板
-
- 併發清除:與併發線程併發執行,清除所有在標記階段未被標記的對象(垃圾),不做對象移動,因此可能會產生內存碎片。
-
缺點:容易產生碎片,有失敗回退(觸發 Serial Old)
-
參數:
-XX:+UseConcMarkSweepGC - 最後一個階段是remark,
5. G1(Garbage First)
-
JDK 9+ 默認回收器,邏輯分代+物理分區
-
支持預測最大停頓時間(
-XX:MaxGCPauseMillis),我們只需告訴它我們的需求(比如100ms內完成垃圾回收),G1會自動去執行。 -
優先回收垃圾比例高、耗費時間短的 Region,效率高。
6. ZGC(Z Garbage Collector)
-
JDK 11+ 引入的超低延遲 GC,GC 停頓通常 <10ms
-
分區式、併發、壓縮型 GC
-
適合大內存、高響應需求場景
-
參數:
-XX:+UseZGC
7. Shenandoah
-
RedHat 提供的併發低延遲 GC,JDK 12+ 開始支持
-
類似 ZGC,主打併發、低 STW 時間
-
參數:
-XX:+UseShenandoahGC
六、JVM 調優與工具
1. JVM 調優層面
-
根據系統併發量、響應時間,選擇合適的 GC 回收器和參數
-
調整堆大小比例(-Xms,-Xmx,-XX:NewRatio,-XX:SurvivorRatio)
-
設置 Full GC 觸發閾值(-XX:InitiatingHeapOccupancyPercent)
2. 常用調試命令
-
jps:查看所有 Java 進程 -
jstack pid:查看線程棧,定位死鎖、阻塞 -
jmap -histo pid:查看對象佔用內存情況 -
jmap -dump:file=heap.bin:生成堆快照 -
top -Hp pid:查看每個線程 CPU 佔用
3. 可視化工具
-
VisualVM:查看 GC 活動、堆內存、線程等
-
JConsole / JFR:監控實時性能
-
MAT:分析堆轉儲文件(heap dump)
-
阿里 Arthas:排查運行中問題
七、GC 日誌與診斷
常用參數
-Xms512M -Xmx512M -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
可上傳 gc.log 到 gceasy.io 自動分析
八、三色標記法(Tri-Color Marking)
現代併發垃圾回收器(如 CMS、G1、ZGC)在可達性分析中廣泛採用三色標記法,幫助在併發標記階段準確判斷哪些對象可達、哪些是垃圾。
三種顏色含義:
-
白色(White):初始狀態,表示“可能是垃圾”
-
灰色(Gray):已被標記為可達,但它引用的對象還沒掃描完
-
黑色(Black):已被標記為可達,且它引用的對象也都掃描完
標記流程:
-
所有對象初始為白色;
-
從 GC Roots 開始,把直接可達對象標記為灰色;
-
每處理一個灰色對象,就把它變成黑色,並將它引用的對象(若是白色)也變成灰色;
-
最終,未被染成黑或灰的白色對象就是不可達的垃圾。
寫屏障與增量更新:
在併發標記過程中,用户線程可能會修改對象引用(比如把一個對象 A 指向了新對象 B)。此時垃圾回收線程可能還沒掃描 A,從而“錯過”了 B。
為解決這個問題,引入寫屏障機制,主要有:
-
增量更新(Incremental Update):記錄“黑對象引用了白對象”,重新標記
-
SATB(Snapshot-At-The-Beginning):記錄“原始引用”,忽略新引用變化
G1 使用 SATB,CMS 使用增量更新。
總結
-
Java 使用 GC Roots 可達性分析來判斷對象是否可以回收
-
主流算法包括:標記清除、複製、標記整理
-
分代策略下,採用不同算法適配不同生命週期的對象
-
常見回收器有 Serial、Parallel、CMS、G1、ZGC 等
-
可通過日誌、工具、命令結合調優 GC 表現,排查內存問題
引用:
https://www.cnblogs.com/xdcat/p/13040725.html
馬士兵











