










🏆🏆🏆教程全知識點簡介:1.APScheduler任務調度涵蓋安裝配置、使用方式、調度器Scheduler、執行器executors、觸發器Trigger等核心組件。2. RPC遠程過程調用包括RPC概念、背景用途、優缺點分析。3. Protocol Buffers數據序列化涉及文檔結構、註釋語法、數據類型、枚舉類型、消息類型(字段編號、字段規則、嵌套類型、保留字段、默認值)。4. 客户端開發包含頭條首頁新聞推薦接口編寫。5. 即時通訊技術涵蓋需求場景、傳統推送實現、Socket.IO(Python服務器端開發、事件處理)。6. Elasticsearch搜索引擎包括簡介原理、倒排索引、分析器、相關性排序、集羣概念、IK中文分析器、索引類型、文檔操作(索引文檔、獲取文檔、判斷存在、更新刪除)、Logstash數據導入、查詢(基本查詢、高級查詢)、全文檢索實現、Python客户端使用、聯想提示(拼寫糾錯、自動補全)。7. 單元測試涵蓋測試分類、基本寫法、測試必要性。8. 服務器部署包括Gunicorn、Supervisor配置管理。9. 項目開發流程涉及產品介紹、原型圖UI圖、技術架構、開發環境(ToutiaoWeb虛擬機、Pycharm遠程開發)。10. 數據庫技術包含ORM理解、SQLAlchemy映射構建、數據庫連接設置、模型類字段選項。11. 分佈式系統涵蓋分佈式ID方案選擇、Twitter Snowflake算法(64位ID劃分、最大取值計算、移位偏移計算、序號循環掩碼、時間戳處理)。12. Redis數據庫包括Redis持久化機制。13. Git工作流涵蓋Gitflow工作流(工作方式、歷史分支、功能分支、發佈分支、維護分支)、調試方法。14. 身份認證技術包含JWT、JWS、JWE概念、Python庫使用、項目封裝實施方案。15. 對象存儲涉及OSS對象存儲、七牛雲存儲服務。16. 緩存系統包括緩存架構、緩存數據保存方式、緩存有效期TTL、緩存淘汰策略、緩存問題(緩存穿透、緩存雪崩)、頭條項目緩存設計(User Cache、Article Cache、Announcement Cache)、持久存儲設計(閲讀歷史、搜索歷史、統計數據)。

📚📚👉👉👉本站這篇博客: https://segmentfault.com/a/1190000046610029 中查看
📚📚👉👉👉本站這篇博客: https://segmentfault.com/a/1190000046610029 中查看
<!-- end:bj1 -->
✨ 本教程項目亮點
🧠 知識體系完整:覆蓋從基礎原理、核心方法到高階應用的全流程內容
💻 全技術鏈覆蓋:完整前後端技術棧,涵蓋開發必備技能
🚀 從零到實戰:適合 0 基礎入門到提升,循序漸進掌握核心能力
📚 豐富文檔與代碼示例:涵蓋多種場景,可運行、可複用
🛠 工作與學習雙參考:不僅適合系統化學習,更可作為日常開發中的查閲手冊
🧩 模塊化知識結構:按知識點分章節,便於快速定位和複習
📈 長期可用的技術積累:不止一次學習,而是能伴隨工作與項目長期參考
🎯🎯🎯全教程總章節


🚀🚀🚀本篇主要內容
Elasticsearch
簡介與原理
You know, for search!
文檔 https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
1 簡介
Elasticsearch是一個基於Lucene庫的搜索引擎。
它提供了一個分佈式、支持多用户的全文搜索引擎,具有HTTP Web接口和無模式JSON文檔。所有其他語言可以使用 RESTful API 通過端口 9200 和 Elasticsearch 進行通信
Elasticsearch是用Java開發的,並在Apache許可證下作為開源軟件發佈。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和許多其他語言中都是可用的。
根據DB-Engines的排名顯示,Elasticsearch是最受歡迎的企業搜索引擎,其次是Apache Solr,也是基於Lucene。
Elasticsearch可以用於搜索各種文檔。它提供可擴展的搜索,具有接近實時的搜索,並支持多租户。
Elasticsearch是分佈式的,這意味着索引可以被分成分片,每個分片可以有0個或多個副本。每個節點託管一個或多個分片,並充當協調器將操作委託給正確的分片。再平衡和路由是自動完成的。相關數據通常存儲在同一個索引中,該索引由一個或多個主分片和零個或多個複製分片組成。一旦創建了索引,就不能更改主分片的數量。
Elasticsearch 是一個實時的分佈式搜索分析引擎,它被用作全文檢索、結構化搜索、分析以及這三個功能的組合
- Wikipedia 使用 Elasticsearch 提供帶有高亮片段的全文搜索,還有 search-as-you-type 和 did-you-mean 的建議。
- 衞報 使用 Elasticsearch 將網絡社某交數據結合到訪客日誌中,實時的給它的編輯們提供公眾對於新文章的反饋。
- Stack Overflow 將地理位置查詢融入全文檢索中去,並且使用 more-like-this 接口去查找相關的問題與答案。
- GitHub 使用 Elasticsearch 對1300億行代碼進行查詢。
Lucene 僅僅只是一個庫,然而,Elasticsearch 不僅僅是 Lucene,並且也不僅僅只是一個全文搜索引擎。 它可以被下面這樣準確的形容:
- 一個分佈式的實時文檔存儲,每個字段 可以被索引與搜索
- 一個分佈式實時分析搜索引擎
- 能勝任上百個服務節點的擴展,並支持 PB 級別的結構化或者非結構化數據
屬於面向文檔的數據庫
Elasticsearch 是 面向文檔 的,意味着它存儲整個對象或 文檔。Elasticsearch 不僅存儲文檔,而且索引每個文檔的內容使之可以被檢索。在 Elasticsearch 中,你 對文檔進行索引、檢索、排序和過濾--而不是對行列數據。
Elasticsearch 有2.x、5.x、6.x 三個大版本, 在黑馬頭條中使用5.6版本。
2 搜索的原理——倒排索引(反向索引)、分析、相關性排序
倒排索引
倒排索引(英語:Inverted index),也常被稱為反向索引、置入檔案或反向檔案,是一種索引方法,被用來存儲在全文搜索下某個單詞在一個文檔或者一組文檔中的存儲位置的映射。它是文檔檢索系統中最常用的數據結構。
假設 有兩個文檔,每個文檔的 content 域包含如下內容:
- The quick brown fox jumped over the , lazy+ dog
- Quick brown foxes leap over lazy dogs in summer
正向索引: 存儲每個文檔的單詞的列表
| Doc | Quick | The | brown | dog | dogs | fox | foxes | in | jumped | lazy | leap | over | quick | summer | the |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Doc1 | X | X | X | X | X | X | X | X | X | ||||||
| Doc2 | X | X | X | X | X | X | X | X | X |
反向索引:
Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
------------------------如果 想搜索 quick brown , 只需要查找包含每個詞條的文檔:
Term Doc_1 Doc_2
-------------------------
brown | X | X
quick | X |
------------------------
Total | 2 | 1兩個文檔都匹配,但是第一個文檔比第二個匹配度更高。如果 使用僅計算匹配詞條數量的簡單 相似性算法 ,那麼, 可以説,對於 查詢的相關性來講,第一個文檔比第二個文檔更佳。
分析
上面不太合理的地方:
Quick和quick以獨立的詞條(token)出現,然而用户可能認為它們是相同的詞。fox和foxes非常相似, 就像dog和dogs;他們有相同的詞根。jumped和leap, 儘管沒有相同的詞根,但他們的意思很相近。他們是同義詞。
進行標準化:
Quick可以小寫化為quick。foxes可以 詞幹提取 --變為詞根的格式-- 為fox。類似的,dogs可以為提取為dog。jumped和leap是同義詞,可以索引為相同的單詞jump。
標準化的反向索引:
Term Doc_1 Doc_2
-------------------------
brown | X | X
dog | X | X
fox | X | X
in | | X
jump | X | X
lazy | X | X
over | X | X
quick | X | X
summer | | X
the | X | X
------------------------對於查詢的字符串必須與詞條(token)進行相同的標準化處理,才能保證搜索的正確性。
分詞和標準化的過程稱為 分析 (analysis) :
- 首先,將一塊文本分成適合於倒排索引的獨立的 詞條 , -> 分詞
- 之後,將這些詞條統一化為標準格式以提高它們的“可搜索性” -> 標準化
分析工作是由分析器 完成的: analyzer
- 字符過濾器
首先,字符串按順序通過每個 字符過濾器 。他們的任務是在分詞前整理字符串。一個字符過濾器可以用來去掉HTML,或者將 & 轉化成 and。
- 分詞器
其次,字符串被 分詞器 分為單個的詞條。一個簡單的分詞器遇到空格和標點的時候,可能會將文本拆分成詞條。
- Token 過濾器 (詞條過濾器)
最後,詞條按順序通過每個 token 過濾器 。這個過程可能會改變詞條(例如,小寫化 Quick ),刪除詞條(例如, 像 a, and, the 等無用詞),或者增加詞條(例如,像 jump 和 leap 這種同義詞)。
相關性排序
默認情況下,搜索結果是按照 相關性 進行倒序排序的——最相關的文檔排在最前。
相關性可以用相關性評分表示,評分越高,相關性越高。
評分的計算方式取決於查詢類型 不同的查詢語句用於不同的目的: fuzzy 查詢(模糊查詢)會計算與關鍵詞的拼寫相似程度,terms 查詢(詞組查詢)會計算 找到的內容與關鍵詞組成部分匹配的百分比,但是通常 説的 相關性 是 用來計算全文本字段的值相對於全文本檢索詞相似程度的算法。
Elasticsearch 的相似度算法 被定義為檢索詞頻率/反向文檔頻率, TF/IDF ,包括以下內容:
- 檢索詞頻率
檢索詞在該字段出現的頻率?出現頻率越高,相關性也越高。 字段中出現過 5 次要比只出現過 1 次的相關性高。
- 反向文檔頻率
每個檢索詞在索引中出現的頻率?頻率越高,相關性越低。檢索詞出現在多數文檔中會比出現在少數文檔中的權重更低。
- 字段長度準則
字段的長度是多少?長度越長,相關性越低。 檢索詞出現在一個短的 title 要比同樣的詞出現在一個長的 content 字段權重更大。
Elasticsearch
概念與集羣
概念
存儲數據到 Elasticsearch 的行為叫做 索引 (indexing)
關於數據的概念
Relational DB -> Databases 數據庫 -> Tables 表 -> Rows 行 -> Columns 列
Elasticsearch -> Indices 索引庫 -> Types 類型 -> Documents 文檔 -> Fields 字段/屬性一個 Elasticsearch 集羣可以 包含多個 索引 (indices 數據庫),相應的每個索引可以包含多個 類型(type 表) 。 這些不同的類型存儲着多個 文檔(document 數據行) ,每個文檔又有 多個 屬性 (field 列)。
Elasticsearch 集羣(cluster)
Elasticsearch 儘可能地屏蔽了分佈式系統的複雜性。這裏列舉了一些在後台自動執行的操作:
- 分配文檔到不同的容器 或 分片 中,文檔可以儲存在一個或多個節點中
- 按集羣節點來均衡分配這些分片,從而對索引和搜索過程進行負載均衡
- 複製每個分片以支持數據冗餘,從而防止硬件故障導致的數據丟失
- 將集羣中任一節點的請求路由到存有相關數據的節點
- 集羣擴容時無縫整合新節點,重新分配分片以便從離羣節點恢復
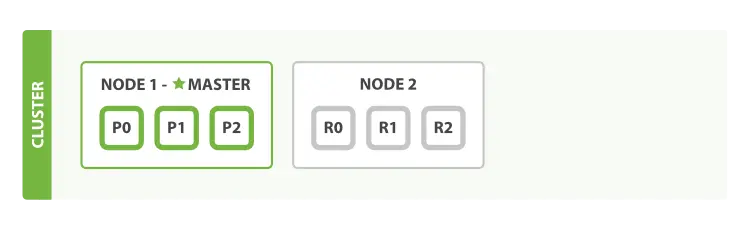
節點(node)
一個運行中的 Elasticsearch 實例稱為一個 節點,而集羣是由一個或者多個擁有相同 cluster.name 配置的節點組成, 它們共同承擔數據和負載的壓力。當有節點加入集羣中或者從集羣中移除節點時,集羣將會重新平均分佈所有的數據。
當一個節點被選舉成為 主 節點(master)時, 它將負責管理集羣範圍內的所有變更,例如增加、刪除索引,或者增加、刪除節點等。 而主節點並不需要涉及到文檔級別的變更和搜索等操作,所以當集羣只擁有一個主節點的情況下,即使流量的增加它也不會成為瓶頸。 任何節點都可以成為主節點。 的示例集羣就只有一個節點,所以它同時也成為了主節點。
作為用户, 可以將請求發送到 集羣中的任何節點 ,包括主節點。 每個節點都知道任意文檔所處的位置,並且能夠將 的請求直接轉發到存儲 所需文檔的節點。 無論 將請求發送到哪個節點,它都能負責從各個包含 所需文檔的節點收集回數據,並將最終結果返回給客户端。 Elasticsearch 對這一切的管理都是透明的。
分片(shard)
一個 分片 是一個底層的 工作單元 ,它僅保存了 全部數據中的一部分。
索引實際上是指向一個或者多個物理 分片 的 邏輯命名空間 。
文檔被存儲和索引到分片內,但是應用程序是直接與索引而不是與分片進行交互。
Elasticsearch 是利用分片將數據分發到集羣內各處的。分片是數據的容器,文檔保存在分片內,分片又被分配到集羣內的各個節點裏。 當你的集羣規模擴大或者縮小時, Elasticsearch 會自動的在各節點中遷移分片,使得數據仍然均勻分佈在集羣裏。
主分片(primary shard)
索引內任意一個文檔都歸屬於一個主分片,所以主分片的數目決定着索引能夠保存的最大數據量。
複製分片(副分片 replica shard)
一個副本分片只是一個主分片的拷貝。 副本分片作為硬件故障時保護數據不丟失的冗餘備份,併為搜索和返回文檔等讀操作提供服務。
在索引建立的時候就已經確定了主分片數,但是副本分片數可以隨時修改.
初始設置索引的分片方法
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}- number_of_shards
每個索引的主分片數,默認值是 5 。這個配置在索引創建後不能修改。
- number_of_replicas
每個主分片的副本數,默認值是 1 。對於活動的索引庫,這個配置可以隨時修改。
2 個節點












