









本文是 2021 年 12 月 26 日,第三十五屆 - 前端早早聊【前端搞 Node.js】專場,來自螞蟻金服 語雀前端團隊 —— 小琿的分享。感謝 AI 的發展,藉助 GPT 的能力,最近我們終於可以非常高效地將各位講師的精彩分享文本化後,分享給大家。(完整版含演示請看錄播視頻和 PPT):https://www.zaozao.run/video/c35
完整 PPT 請聯繫小助手(vx:zzleva)獲取
正文如下
大家好,我是來自語雀的小琿,是一名全棧開發工程師。
在本次分享的內容如下:
- 解釋什麼是 ORM,以及它在Node.js web 應用中的使用和優缺點。
- 大致介紹目前比較常見的兩種 ORM 模式 - Active Record 和 Data Mapper,並對它們進行簡單對比。
- 用架構圖和偽代碼來詳細介紹 ORM 的結構,包括其中的重要部分和相關實現。
- 使用 ORM 時可能遇到的問題以及相應的優化措施。

什麼是 ORM
為了照顧純前端的同學,我將先展示一個簡單的 demo 來演示 ORM 的使用。我們假定有三張表,用户表、文章表和評論表,它們之間的關係可以用圖表現出來。每篇文章只能有一個作者,每個文章可以有多條評論,每一條評論只能屬於某一篇文章。接下來我們來看看 ORM 在使用時,如何表達數據庫中的關係,並使用它進行業務查詢和展示。
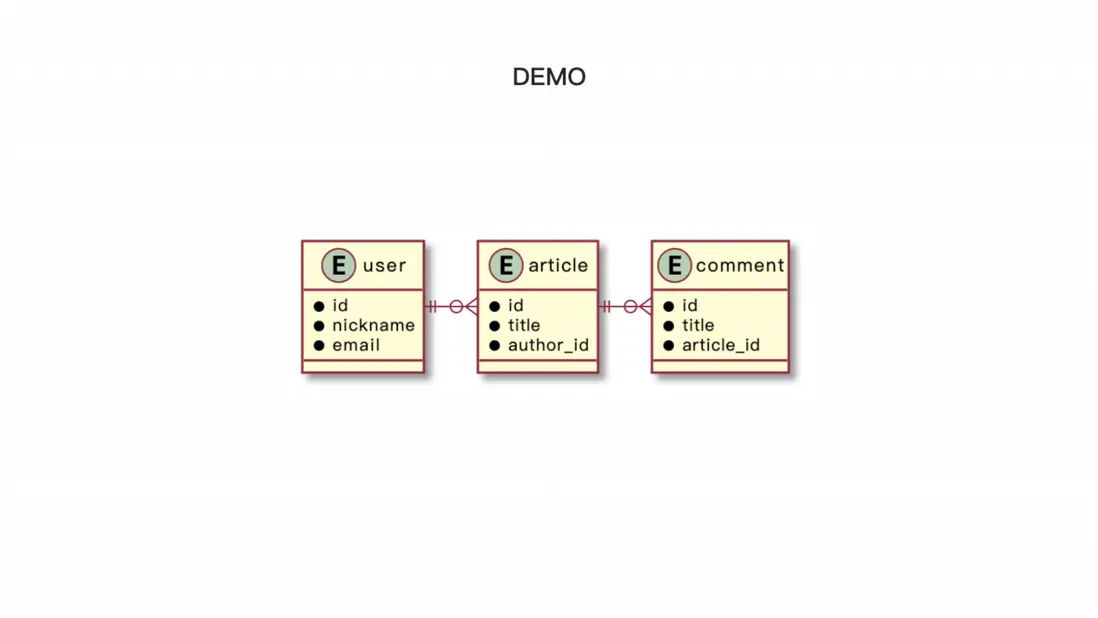
首先,我們會使用 ORM 來描述三個實體,包括用户、文章和評論。我們將使用 user 類來對應用户實體,使用 comment 類對應評論實體,使用 article 類對應文章實體。在 article 類中,我們將描述剛剛提到的兩個關係,即每篇文章有一個作者,每篇文章有多條評論。我們將根據本地數據庫的設置,連接到數據庫,進行初始化操作。在初始化函數中,我們會首先連接到數據庫,然後對這三張表進行數據清理。接下來,我們將演示如何使用 ORM 進行增刪改查操作。
我們將先創建一個用户,並使用 ORM 功能查詢出該用户,然後對其進行簡單修改,並重新查詢結果。接着,我們將創建一個文章,並添加兩個評論。然後,我們將使用三種不同的方式來查詢文章以及與之相關的作者和評論。在執行結果中,我們可以看到每個操作所對應的SQL語句和調用,以及查詢到的結果。在下面的三個不同的API調用方式中,生成的 SQL 語句都是相似的。最終,我們將得到一篇文章及其相關的作者、評論以及其他信息。通過這個 demo,我們可以看到如何在 Node.js 中使用 ORM 進行增刪改查操作。
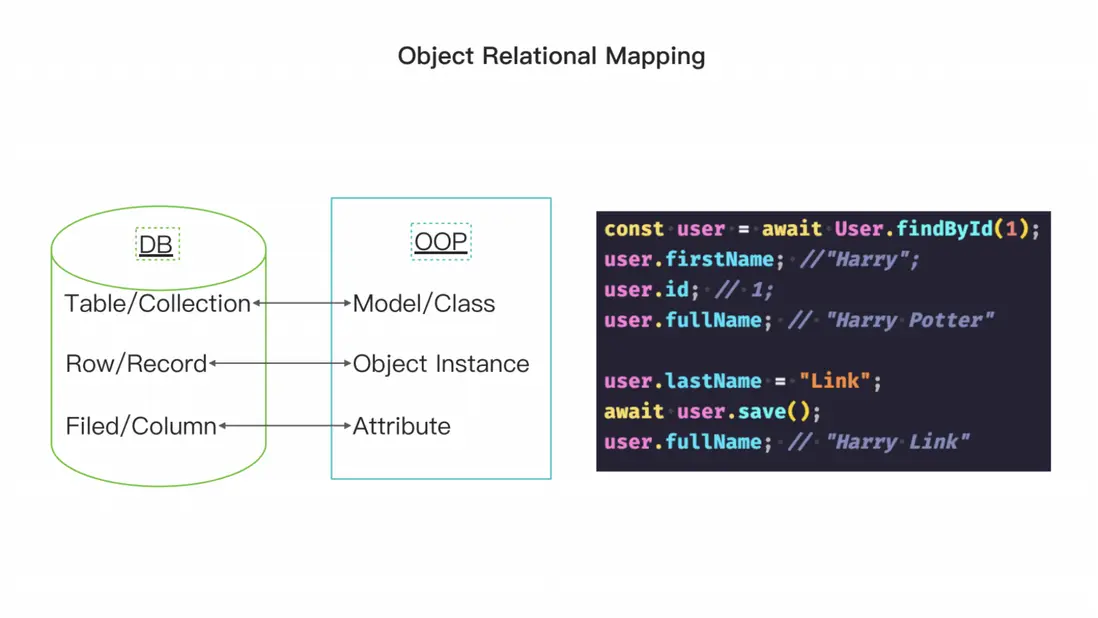
回到主題什麼是 ORM? ORM 是對象關係映射(Object Relation Mapping)的縮寫,它將數據中表對應着的開發代碼或內存中的 model 類與數據庫中的某一張表對應。數據表中的每一條數據對應着 model 類的一個實例,數據表中的某個字段對應着 model 類的一個成員變量。使用 ORM 可以將數據庫中的數據映射到開發代碼中,從而方便地操作數據庫的增刪改查。
使用 ORM 有很多優點,例如 ORM 會對查詢和更新操作進行數據預處理,從而防止 SQL 注入的風險。另外,ORM 屏蔽了直接編寫 SQL 的細節,使得開發人員不必自己寫 SQL,這對於 SQL 不熟練的人來説是一個好處。此外,由於ORM以模型為基礎,因此支持 MVC 的開發架構,並且可以映射所有數據庫表到內存的 model 中,這有助於組織和複用代碼,避免了到處寫SQL的尷尬處境。
然而,使用 ORM 也存在一些缺點。例如,由於 ORM 定製以及組合 API 生成的 SQL 的特性,有時自動生成的 SQL 可能不是最優的方案,這可能會導致性能問題。此外,為了處理各種複雜的邏輯,model 也會變得很複雜,處理查詢結果可能會有不必要的對象深拷貝,這會影響應用的性能。同時,ORM 為了適配 SQL 滿足的各種業務場景,有很多 API 需要學習,這也是一種成本。另外,對於一些奇怪的查詢需求,ORM 可能無法滿足,此時只能手寫 SQL。這些是我總結 ORM 的一些優點和缺點。

Active Record & Data Mapper
接下來介紹兩種常見的 ORM 模式:Active Record 和 Data Mapper。Active Record 翻譯成中文就是主動記錄模式,是一種架構模式。之前展示的 ORM 是 Active Record 模式的。

Active Record 的簡單總結是一個對象,同時包含了數據庫對應的屬性字段和相應的業務的增刪改查操作,也就是説 model 打包了這一個域該有的所有功能。比如,用户有了 user model 就可以直接使用它,並對它以及 user model 實例進行一些業務的編碼。這種類型的 ORM 幾乎都有一個特點,就是所有 CRUD 操作都打包在一個 model 中。業務中只需要根據自己的項目和數據庫設計去派生出對應的 base model 的子類。user model 繼承了 base model 所有的 API,同時也會包含自己特有的業務 API,比如查詢某個性別的用户、某個年齡段用户等等。

Active Record 類型的 ORM 使用上更加符合我們的直覺,使用起來更方便。數據庫有多少張表,就對應多少個 model,每個 model 有哪些操作,都在這個派生出來的 model 中實現。它代表的是我們的數據結構與模型對象高度耦合,因此可能更適合一些業務邏輯比較簡單的中小型應用。
我們之前已經展示了一個屬於 Active Record 類型的ORM demo,因此在這裏就不再多作解釋。接下來,我們將介紹另一種 ORM 類型,即 Data Mapper類型。我們將通過一個 demo 來説明這種類型的 ORM,其中涉及到的模型包括 user、article 和 comment。回顧一下它們之間的關係:每篇文章有一個作者,每個用户可以有多篇文章,每篇文章有多條評論,每條評論只能歸屬於一篇文章。雖然 Data Mapper 類型的 ORM 在 JavaScript 中並不是很流行,但我們將使用一個名為 TypeORM 的常用 ORM 來進行演示。
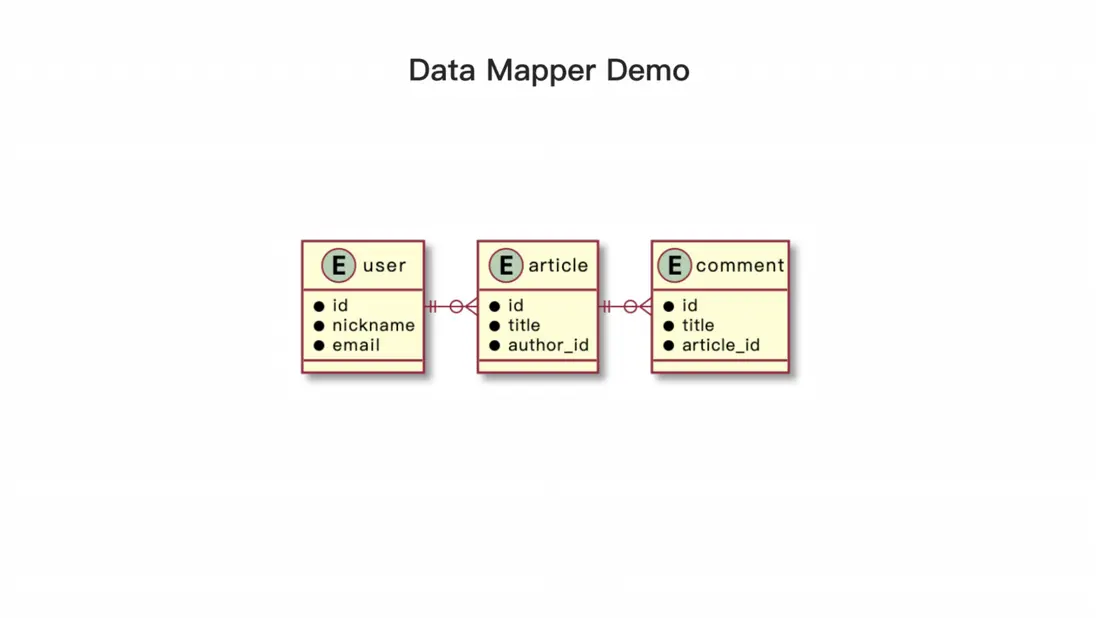
首先,我們需要聲明實體,分別是用户(user)、文章(article)和評論(comment)。在每個實體中,我們聲明可能用到的屬性和實體之間的關係。例如,用户可能會有多篇文章,而一篇文章只能有一個作者和多個評論,每個評論只能屬於一篇文章。這與之前講過的 Active Record ORM 類似,但有一個不同點是這些模型不再包含基礎的數據操作(例如增刪改查),而只用於展示數據,例如名字的展示可能需要加上大寫等特殊的展示。
Data Mapper 的實現主要是為了適配某個實體或幾個實體的一些基礎業務操作。我們以文章(article)為例,實現一個 Data Mapper,裏面會有一個 API,用於根據當前文章的 ID 獲取其作者(article)和評論(comment)。在 API 中,我們使用 Data Mapper 提供的基礎 API 去做一個簡單的查詢。由於數據庫中已經有了數據,我們直接去查詢,然後生成一個circle並查找到想要的文章,其中包含作者和兩個評論。
Data Mapper 模式與 Active Record 模式的不同點在於,它將數據存儲層與領域層解耦,模型不再承擔增刪改操作的功能。Data Mapper 可以同時處理一個或多個實體類的應用,例如連表查詢和統一的數據插入操作等業務操作。如果某個業務需要對數據一致性有較強的要求,並涉及多個實體,Data Mapper 可以直接在其中進行操作。
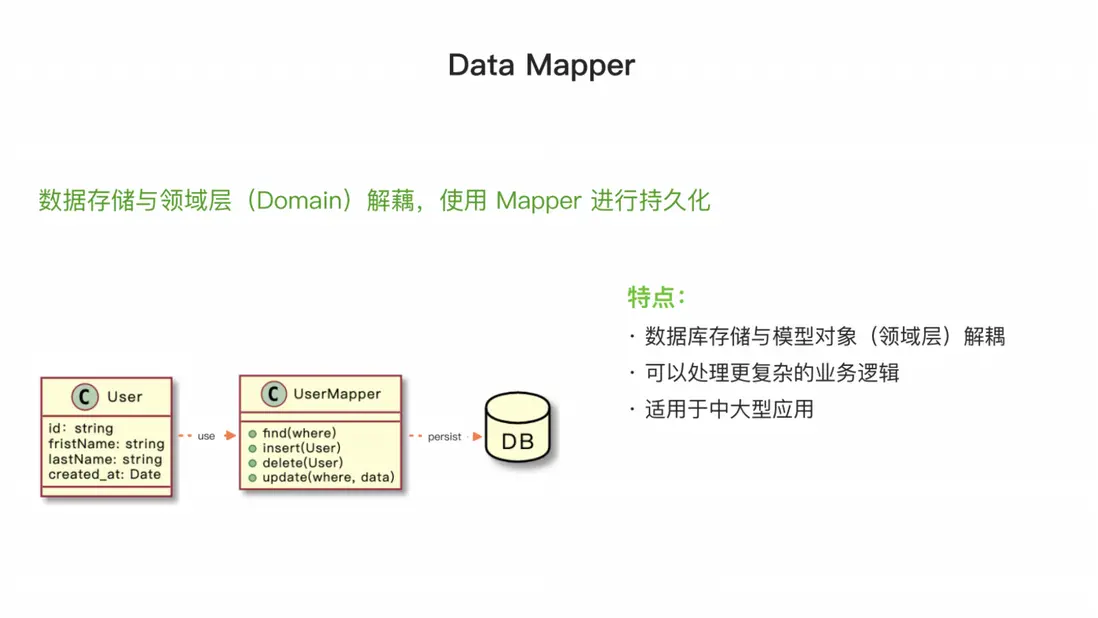
與之前的 Active Record ORM 不同,如果涉及多個模型,我們可能需要單獨使用一個服務(Service)將這些模型結合起來進行處理。因此,Data Mapper ORM 更適合處理多實體類的應用。

ORM 的構成
我們接下來將講解 ORM 的構成,其中我們將重點講解 Active Record ORM,這是我們常用的一種類型。這些例子都是偽代碼。
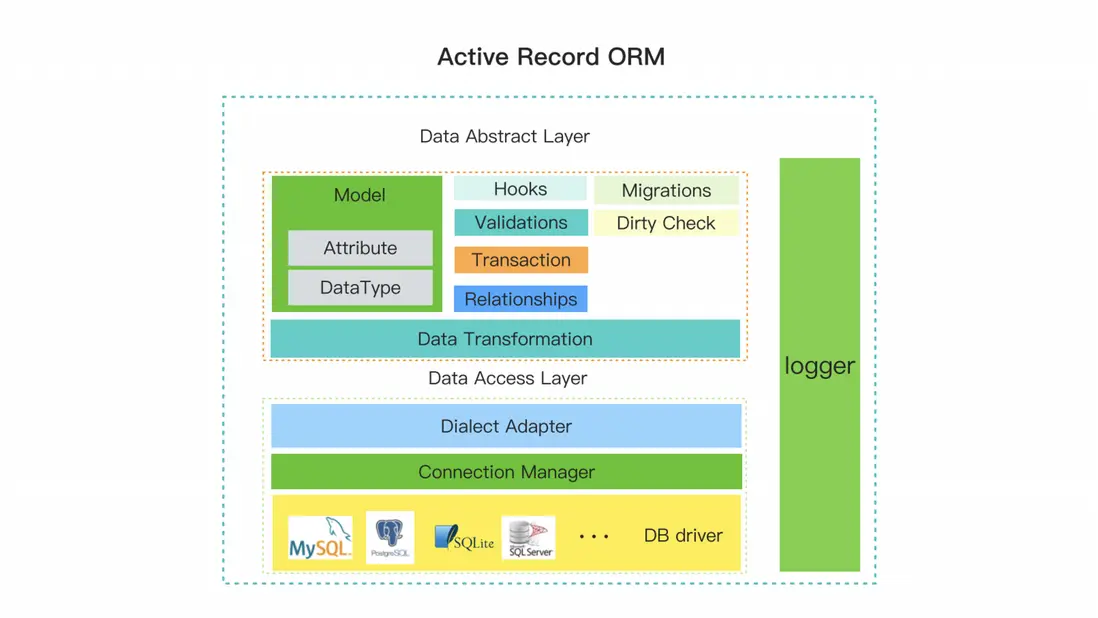
我將 Active Record ORM 的結構分為兩層,第一層為數據抽象層,包含常用的 Base Model,通過繼承 Base Model 來創建業務 model。
- API 都通過 Base Model 進行調用,其他基礎功能依附於Base Model。
- Hooks 是插入到 API 執行過程中的鈎子函數,可以對特定 model 的字段在執行某個操作時進行通用處理。
- Validations 是 ORM 進行數據預處理的必要部分,使用它可以提高應用的安全性和降低數據庫執行 SQL 時的數據類型轉換壓力。
- Transaction 是對數據事務的抽象和實現,對於一些數據一致性要求高的業務很有必要。
- Relationships 是關係型數據庫的核心,每個 model 與 model 之間的關係對應數據庫的 ERD。
- Migrations 是 ORM 的一個工具類型的功能,用於同步數據表結構以及數據訂正。
- Dirty Check 是檢查數據是否更新的功能,在 Hooks 中使用較多。
- Data Transformation 是將查詢結果轉換為 model 實例,或將查詢條件轉換為數據庫能夠識別的數據類型的功能。
第二層為數據訪問層。
- Dialect Adopter 是核心功能,將 model 的 API 調用轉換成對應的 SQL,並在轉換過程中抹平 ORM 會適配的不同數據庫之間的方言差異。
- Connection Manager用於管理ORM在應用中的數據庫連接。
- DB Driver是數據工具,用於與數據庫進行交互。
日誌模塊是開發和運維中必須的,貫穿整個架構。
數據抽象層
在 Base Model 中,數據表中的某個字段對應着 model 類的成員變量,這是對象關係映射中的重要關係映射。
DataType(數據類型)主要用於表現數據類型,作為 JS 基礎類型與數據庫數據類型的橋樑,記錄了數據庫類型和對應的 JS 數據類型,並能在兩種語言之間轉換數據類型。它還需要表達該類型的 SQL,例如,如果數據類型是 integer,在 MySQL 中表現是什麼樣子的,在 post Grace 或 circulate 中表現又是什麼樣子的類型。這樣,最小的 ORM 最小單位類就成型了。
Attribute (屬性)用於表達數據表中的數據字段,它能夠與數據表中的字段設置大致一致,包括是否允許為空、是否有默認值、數據類型等。在 ORM 中,Attribute 還有一個重要的功能,就是數據驗證,可以設置一些預置的規則或用户自定義的規則來驗證數據的合法性。

在 Active Record ORM 中,Base Model 是其核心組成部分之一。它包含了 CRUD 在內的所有基礎 API,同時還要能夠讀取用户派生的 model。在 Base Model 中,還有針對數據庫與應用開發語言之間的不同命名習慣的 name 和 column 成員變量。初始化 model 時,還會有用户設置的 Hooks 和 Validation,用户可以自定義 set/get 方法來對某個字段做一些自定義的操作,在設置字段值的時候自動執行相應操作,比如用 text 類型數據庫的字段來存儲 JSON 字符串。此外,base model 還會記錄各個 model 之間的關係,如 has_one、has_many 等關係。

Hooks 是指一些在函數執行前或執行後需要執行的操作,Hooks 的使用則可以降低業務代碼的複雜度,減少工作量,它需要注意一下幾點。
- Hooks 需要能夠疊加某個操作,以便處理多種邏輯,這些邏輯不會相互影響。
- Hooks 需要有一個原函數,它的入參和返回值類型不能被修改。Hooks 的實現方式有很多種,其中比較直觀的一種方式是面向切面編程。在 ORM 的 API 中,一些 API 可以配置或需要配置 hooks,例如 create、update、destroy 等。
- Hooks 的實現需要注意不同的 API 入參和返回值可能不同。
- 實現 Hooks 時需要注意靜態成員方法和成員方法、函數執行上下文等問題。
- 在使用 AOP 實現 Hooks 時,我們還需要考慮如何跳過 Hooks 的執行。

接着我們來看一下 Transaction 的簡單實現。在 SQL 語法中實現事務並不複雜,一般使用 begin 開始事務,執行業務 SQL,然後使用 commit 提交或 rollback 回滾事務。在代碼中實現事務,我們可以提供一些基礎的 API,如 begin、commit 和 rollback。在事務開始時,可能需要設置事務的隔離級別。通過這些 API,我們可以保持業務代碼的數據一致性。然而,在實現事務時,我們需要考慮如何自動 commit 和 rollback,而不需要手動調用 commit 和 rollback。

數據訪問層
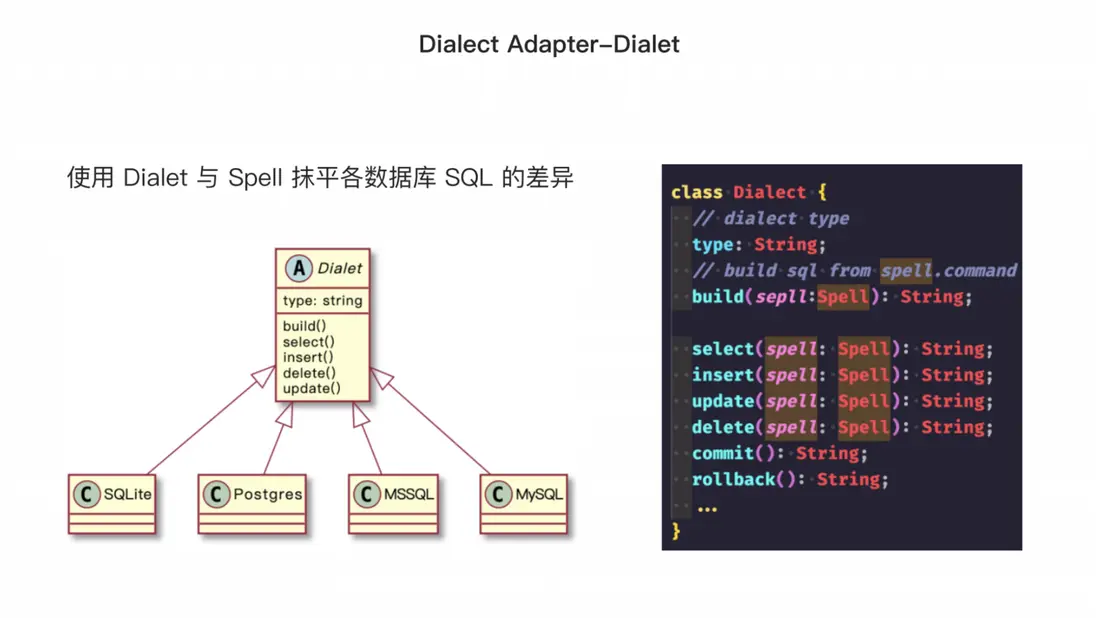
在數據抽象層中,為了適配常用的數據庫類型,需要一箇中間態去表達 ORM API,這個中間態被稱為 Spell。它可以表達實際的 SQL 命令,根據模型的類型去判斷操作的數據表,表達查詢所需的字段以及常用的 SQL 關鍵詞表達式。

Dialect 需要解析 Spell 表達式,根據方言類型生成特定的 SQL。例如,ORM 需要官方提供支持的MySQL、Postgres、SQL Server和 SQLite 的 Dialect。因此,需要為每種數據庫類型編寫一個dialect。我們可以將 Spell 表達式的解析抽象成標準的接口,這樣開發者就可以實現自己的方言,甚至不僅限於 SQL,還可以是其他類型的查詢語言。這樣我們就可以使用 ORM 的 API 進行各種類型的查詢。
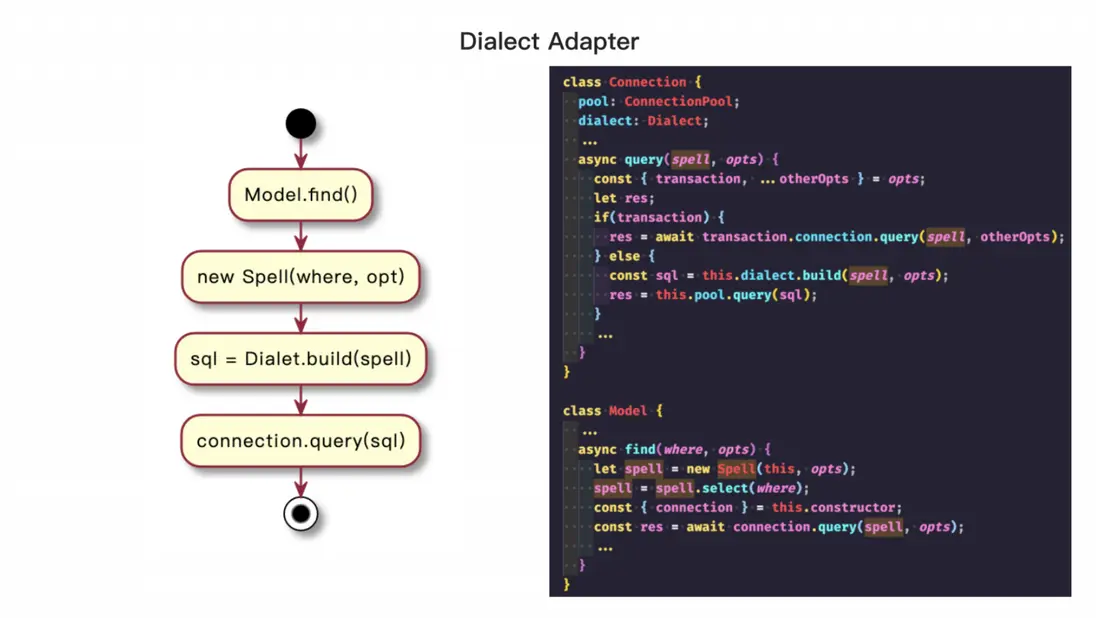
整個查詢的執行過程是這樣的:假設我們使用 user model 去查詢某個用户數據,我們在 user model 中使用 find 方法並根據傳參生成對應的 Spell 對象。然後我們在 Connection 類中管理數據庫連接池和方言(即 Dialect),實現一個 query 方法,在其中調用 Dialect 生成 SQL,使用 SQL Driver 執行 SQL,最後通過進行數據轉換並返回結果。
模塊之間的關係
讓我們再深入瞭解各個模塊之間的關係。首先,數據層面上最主要的實體是 Model。在執行查詢操作時, Spell 作為一箇中間態,它連接了數據抽象層和數據訪問層。同時,Dialect 負責適配數據庫方言和生成特定的 SQL。這個結構還可以擴展出更多的功能,不僅限於 SQL 查詢。
else
我們思考一下一個相對成熟的 ORM 還需要哪些改進?

ORM 問題 / 優化
緩存查詢
通過適當的操作來降低數據庫的 QPS,例如在多個 service 方法中重複調用某個 Model 的查詢時可以使用緩存技術,多次調用時只使用一次結果。
為了避免多次查詢,可以通過緩存來保存查詢結果,多次調用同一個查詢時就可以直接使用緩存結果,從而降低數據庫的 QPS。使用這種方法的時候,還需要考慮到緩存的刷新問題,例如,在更新數據時,可以在 update 中添加一個 Hooks,更新時自動刷新緩存。

合理使用 Hooks
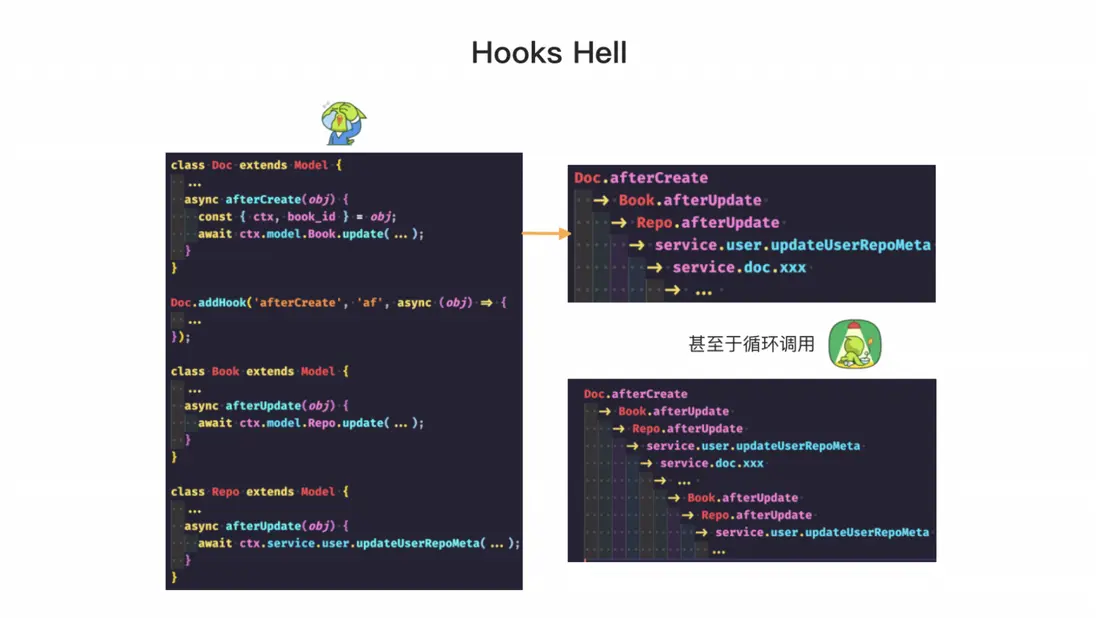
使用 Hooks 是在使用 ORM 時常見的問題。Hooks 可以大大簡化代碼,例如我們可以根據文檔內容是否更改來更新其更新時間等字段。在某些複雜情況下,我們可能需要在一個 Model 中的 Hooks 中調用另一個 Model 的增刪改操作,例如創建文檔後可能需要更新 Book 的操作並觸發相應字段的更新,這時我們需要考慮它們之間的關聯關係和更新順序。

當我們的業務越來越複雜時,例如在更新 Repo 的時候可能需要觸發一些 service 方法,而這些 service 方法可能會在 Hooks 方法中直接調用,導致調用鏈越來越長,越來越複雜。這種不規範的寫法會使得代碼的複雜度非常難以控制,甚至可能出現循環調用等問題,給新手帶來極大的困擾。因此,在使用 Hooks時需要非常謹慎,避免出現類似的問題。使用 Hooks 需要謹慎,雖然在平時使用時會感覺很方便,但是當需要重構或進行技術重構時,就可能會遇到困難,甚至引起災難級事故。
查詢優化
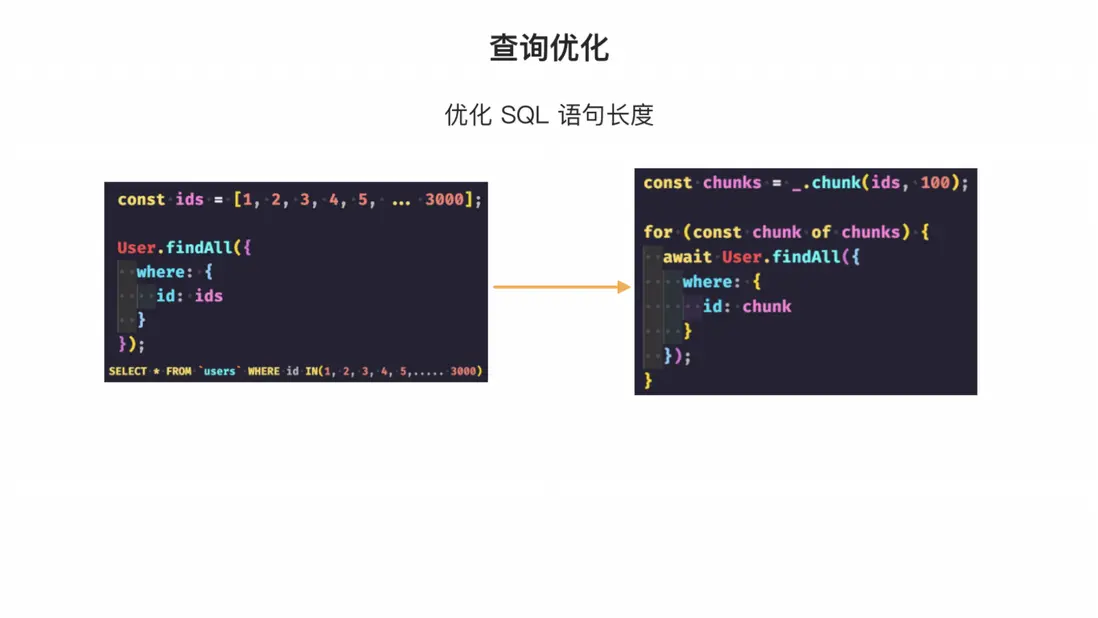
此外,在使用 ORM 工具時,需要進行查詢優化,因為 ORM 只能根據輸入參數做一些簡單的優化處理,而對於一些極限情況,需要開發人員自己去注意。例如,在進行 SQL 查詢用 in 時,由於條件長度較長,可能會因為數據庫引擎的原因導致 SQL 無法執行或執行效率較低,此時需要將查詢條件進行分組,利用 Node.js 進行分批查詢,並在內存中組裝結果。
在 ORM 的使用中,需要注意不正確使用 ORM 的 API 調用可能會導致生成子查詢,從而降低查詢性能。
最後
最後,推薦大家閲讀 ORM 的源碼(https://leoric.js.org/)和《企業應用架構模式》(https://marti...),尤其是其中介紹的兩種架構模式。











