









常用的數據庫備份恢復的方法你知道多少?
當然,這是一個非常核心且重要的運維和開發問題。數據庫的備份與恢復是數據安全的生命線。下面我將系統地介紹常用的方法,並按照備份類型和恢復場景進行梳理。
一、 核心備份類型
備份主要分為以下幾類,它們各有優劣,通常需要結合使用。
1. 物理備份 vs 邏輯備份
|
特性
|
物理備份
|
邏輯備份
|
|
定義 |
直接拷貝數據庫的物理文件(如數據文件、控制文件、日誌文件等)。
|
備份數據庫的邏輯結構(如表、視圖、存儲過程等),生成SQL語句或特定格式文件。
|
|
粒度 |
數據庫或表空間級別。通常不能恢復到單表。
|
數據庫、表、甚至行級別。恢復靈活。
|
|
速度 |
快,因為是文件塊的拷貝。 |
慢,需要執行SQL和轉換。 |
|
恢復速度 |
快,直接替換文件。 |
慢,需要執行SQL語句重建對象和插入數據。 |
|
體積 |
通常較大,與數據庫實際佔用的空間有關。
|
通常較小(特別是如果使用壓縮),只包含數據和結構。
|
|
一致性 |
需要數據庫處於歸檔模式或完全關閉,否則可能備份出一致性有問題的文件。
|
備份時點數據一致。
|
|
工具舉例 |
|
|
2. 全量備份、增量備份與差異備份
|
類型 |
描述
|
優點
|
缺點
|
|
全量備份 |
備份某個時間點的所有數據。 |
恢復簡單,只需一個備份集。
|
備份時間長,佔用空間大。
|
|
增量備份 |
備份自上一次備份以來(可以是全量或增量) 發生變化的數據。 |
備份速度快,佔用空間小。
|
恢復複雜,需要依賴上一次全量和所有後續增量備份,形成鏈式依賴。
|
|
差異備份 |
備份自上一次全量備份以來所有發生變化的數據。 |
恢復比增量簡單,只需上一次全量和最後一次差異備份。
|
備份速度和時間介於全量和增量之間,佔用空間會隨時間增長。
|
最佳實踐:通常採用結合的方式,例如:每週一次全量備份,每天一次差異備份,或每小時一次增量備份。
3. 熱備份 vs 冷備份
- 熱備份(在線備份):在數據庫正常運行、提供服務時進行備份。對業務影響最小,但技術實現較複雜,需要數據庫管理系統的支持(如開啓歸檔模式)。
- 冷備份(離線備份):完全關閉數據庫服務後,再進行備份。實現簡單,能保證絕對一致性,但需要停機,對業務影響大。
二、 常用備份與恢復方法(按數據庫舉例)
MySQL
- 邏輯備份與恢復
- 工具:
mysqldump - 備份:
# 備份單個數據庫
mysqldump -u username -p database_name > backup.sql
# 備份所有數據庫
mysqldump -u username -p --all-databases > all_backup.sql
# 只備份結構
mysqldump -u username -p --no-data database_name > schema.sql- 恢復:
mysql -u username -p database_name < backup.sql- 物理備份與恢復
- 工具:
Percona XtraBackup - 備份:實現非阻塞的熱備份。
# 全量備份
xtrabackup --backup --target-dir=/path/to/backup
# 準備恢復(使備份文件數據一致)
xtrabackup --prepare --target-dir=/path/to/backup- 恢復:
- 停止MySQL服務。
- 清空或移走原數據目錄。
- 將備份文件拷貝回數據目錄。
- 修改文件權限。
- 啓動MySQL服務。
PostgreSQL
- 邏輯備份與恢復
- 工具:
pg_dump/pg_dumpall - 備份:
# 備份單個數據庫,生成自定義壓縮格式
pg_dump -Fc -U username database_name > backup.dump
# 備份所有數據庫(如角色信息等)
pg_dumpall -U username --globals-only > globals.sql- 恢復:
# 使用 pg_restore 恢復自定義格式備份
pg_restore -U username -d database_name backup.dump- 物理備份與恢復
- 工具:
pg_basebackup - 備份:
pg_basebackup -U username -D /path/to/backup -Ft -P -Xs- 恢復:通常與PITR(時間點恢復) 結合,需要開啓
WAL歸檔。恢復時,將基礎備份文件還原,並在recovery.conf(PG12+版本在postgresql.conf)中配置要恢復到的目標時間點,數據庫會自動應用WAL日誌進行恢復。
三、 高級與通用技術
- 快照技術
- 原理:利用底層文件系統(LVM, ZFS)或存儲設備(SAN)、雲平台(AWS EBS Snapshot, Azure Disk Snapshot)的快照功能,在極短時間內創建整個卷的只讀副本。
- 優點:幾乎瞬時完成,對性能影響極小。
- 流程:
- 鎖定數據庫或將表置於只讀狀態(確保一致性)。
- 創建快照。
- 解除數據庫鎖定。
- 在快照捲上進行備份操作。
- 適用:所有數據庫,但需要環境和權限支持。
- 複製(Replication)作為備份的補充
- 搭建從庫(如MySQL主從複製,PostgreSQL流複製)。主庫的數據實時(或近實時)同步到從庫。
- 作用:
- 讀寫分離:分擔主庫壓力。
- 高可用:主庫宕機,從庫可切換為主庫。
- 備份:可以在從庫上執行備份操作,而不影響主庫性能。這實際上是一種活的、延遲極低的物理備份。
四、 備份策略與最佳實踐
- 3-2-1 備份規則
- 至少保留3份數據副本。
- 使用至少2種不同介質存儲(如硬盤+雲存儲)。
- 至少1份備份存放在異地。
- 定期恢復測試
- 備份的有效性通過恢復來驗證! 必須定期(如每季度)執行恢復演練,確保備份文件可用,並且團隊熟悉恢復流程。
- 監控與告警
- 監控備份任務是否成功完成。
- 監控備份文件的大小和生成時間是否有異常。
- 文檔化
- 詳細記錄備份策略(頻率、類型、保留週期)和詳細的恢復操作手冊。在緊急情況下,清晰的文檔至關重要。
總結
沒有一種方法可以應對所有場景。一個健壯的備份恢復方案通常是混合策略:
- 使用“全量+增量/差異” 來平衡備份窗口和存儲成本。
- 結合“物理+邏輯”備份,物理備份用於快速恢復整個數據庫,邏輯備份用於細粒度恢復或數據遷移。
- 利用“快照” 進行高頻、低影響的底層備份。
- 搭建“複製從庫”,既實現高可用,又為備份提供一個獨立的環境。
- 嚴格遵守“3-2-1規則”,並將定期恢復測試作為制度執行。
選擇哪種方法取決於您的數據量、可接受的恢復時間目標(RTO)和恢復點目標(RPO)、數據庫類型以及IT基礎設施。
如果是以下的備份方式,你如何應對:
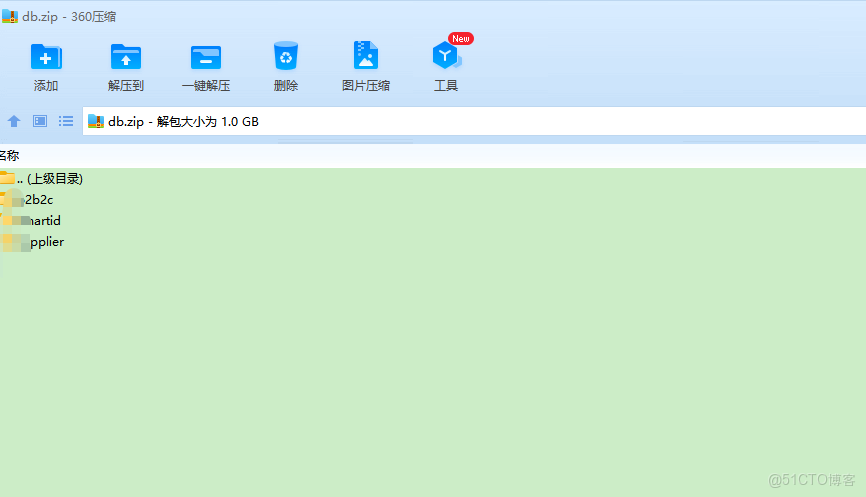

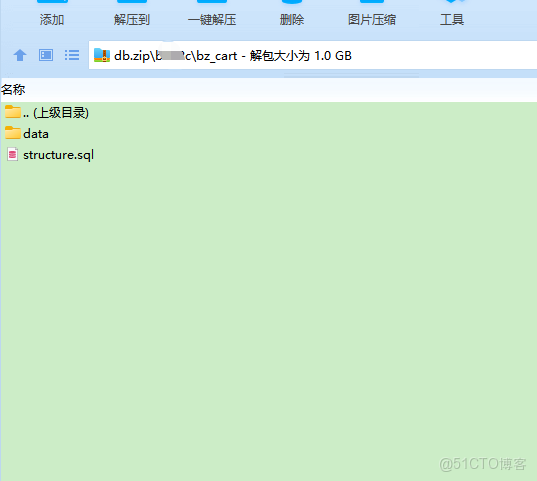
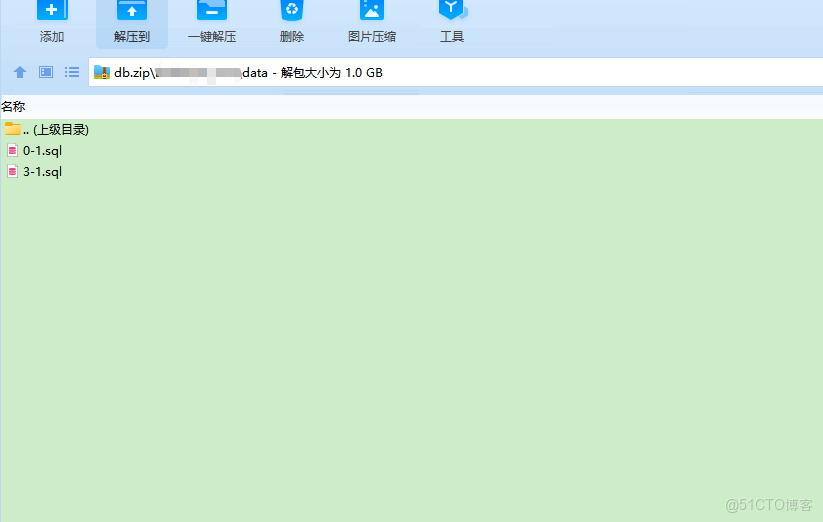
/data 目錄下面是插入sql, RDS每天的備份就是這樣的,把整個庫當做一個文件,每個表是一個文件夾,文件夾下面的是創建表語句,data目錄下是對應的插入數據,針對這樣的,備份文件,你如何破局,快速恢復;
1、採用Java + JDBC 編寫程序恢復數據,這種情況,要編寫代碼,恢復比較慢;
2、還有別的方式嗎?
除了使用 Java + JDBC 編寫程序恢復數據外,還有以下 更快捷、更高效 的方式,適合處理 100+ 張表的批量恢復場景:
✅ 更快捷的方式推薦
1. 使用 mysql 命令行工具 + Shell 腳本(最快)
適用於 Linux/macOS 環境,無需寫代碼,直接調用 MySQL 客户端。
#!/bin/bash
DB_NAME="your_db"
MYSQL_USER="root"
MYSQL_PASS="password"
# 遍歷每個表目錄
for TABLE_DIR in db/b2b2c/*; do
TABLE_NAME=$(basename "$TABLE_DIR")
echo "=== 恢復表: $TABLE_NAME ==="
# 創建表結構
mysql -u "$MYSQL_USER" -p"$MYSQL_PASS" "$DB_NAME" < "$TABLE_DIR/structure.sql"
# 合併 data 目錄下的所有 SQL 文件並導入數據
cat "$TABLE_DIR/data/*.sql" | mysql -u "$MYSQL_USER" -p"$MYSQL_PASS" "$DB_NAME"
done- ✅ 優點:
- 不需要寫 Java 程序,直接調用 MySQL 客户端。
- 執行速度快,適合大規模表恢復。
- 支持併發執行(可加
&並行)。
- ❌ 注意事項:
- 確保
mysql命令可用。 - 數據庫需允許遠程連接或本地訪問。
2. 使用 mysqldump 導出為標準 SQL 文件後導入
如果原始備份是通過
mysqldump生成的,可以反向操作。
# 將所有表的 structure 和 data 合併成一個完整 SQL 文件
find db/b2b2c -name "*.sql" -exec cat {} \; > full_restore.sql
# 使用 mysql 命令恢復
mysql -u root -p your_db < full_restore.sql- ✅ 優點:
- 一行命令完成全部恢復。
- 兼容性好,適合跨平台遷移。
- ⚠️ 注意:
- 需要確保
full_restore.sql中的語句順序正確(先建表再插入)。
3. 使用阿里雲 DTS 或 DataWorks(企業級方案)
如果您在阿里雲環境,推薦使用官方工具:
- DTS(Data Transmission Service)
- 支持從文件系統到 RDS 的自動同步。
- 可配置源端為本地文件夾,目標為 MySQL 實例。
- 自動解析 [.sql](file://D:\project\mall\bbc-java\sql\sql.sql) 文件並執行。
- DataWorks
- 提供可視化任務調度,支持腳本化導入。
- 可定時執行恢復流程。
- ✅ 優點:
- 圖形化界面,無需編碼。
- 支持斷點續傳、失敗重試等高級功能。
4. 使用 Python + mysql-connector-python(輕量級替代)
import os
import mysql.connector
def restore_table(table_dir):
conn = mysql.connector.connect(
host='localhost',
user='root',
password='password',
database='your_db'
)
cursor = conn.cursor()
# 執行 structure.sql
with open(os.path.join(table_dir, 'structure.sql')) as f:
sql = f.read()
cursor.execute(sql)
# 執行 data/*.sql
for file in os.listdir(os.path.join(table_dir, 'data')):
if file.endswith('.sql'):
with open(os.path.join(table_dir, 'data', file)) as f:
sql = f.read()
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()- ✅ 優點:
- 語法簡潔,開發快。
- 易於調試和擴展。
✅ 推薦優先級排序
|
方式
|
速度
|
複雜度
|
是否推薦
|
|
Shell + |
⭐⭐⭐⭐⭐
|
⭐
|
✅ 最推薦
|
|
Python 腳本
|
⭐⭐⭐⭐
|
⭐⭐
|
✅ 推薦
|
|
Java + JDBC
|
⭐⭐⭐
|
⭐⭐⭐
|
⚠️ 可用但較重
|
|
阿里雲 DTS/DataWorks
|
⭐⭐⭐⭐⭐
|
⭐⭐
|
✅ 企業級首選
|
🎯 結論
最快捷的方式是:使用 Shell 腳本 +
mysql命令行工具,無需編程,一鍵恢復全部表。












