









編者按: 我們今天為大家帶來的文章,作者的觀點是:GPT-5 通過引入“智能路由器”架構,實現了按需調用不同專家模型的動態協作機制,標誌着大模型正從“全能單體架構”邁向“專業化協同架構”的新範式。
文章深入剖析了 GPT-5 路由機制的四大決策支柱 —— 對話類型、任務複雜度、工具需求與用户顯性意圖,並對比了其相較於 GPT-4、Toolformer 及早期插件系統的突破性進步。作者還詳細拆解了該架構的技術實現路徑、核心優勢(如響應速度提升、資源成本優化、可解釋性)以及潛在挑戰(如延遲疊加、路由誤判、調試困難)。尤為難得的是,文中還提供了基於開源工具構建輕量級 GPT-5 式路由器的可行方案,為開發者指明瞭實踐方向。
作者 | Bhavishya Pandit
編譯 | 嶽揚
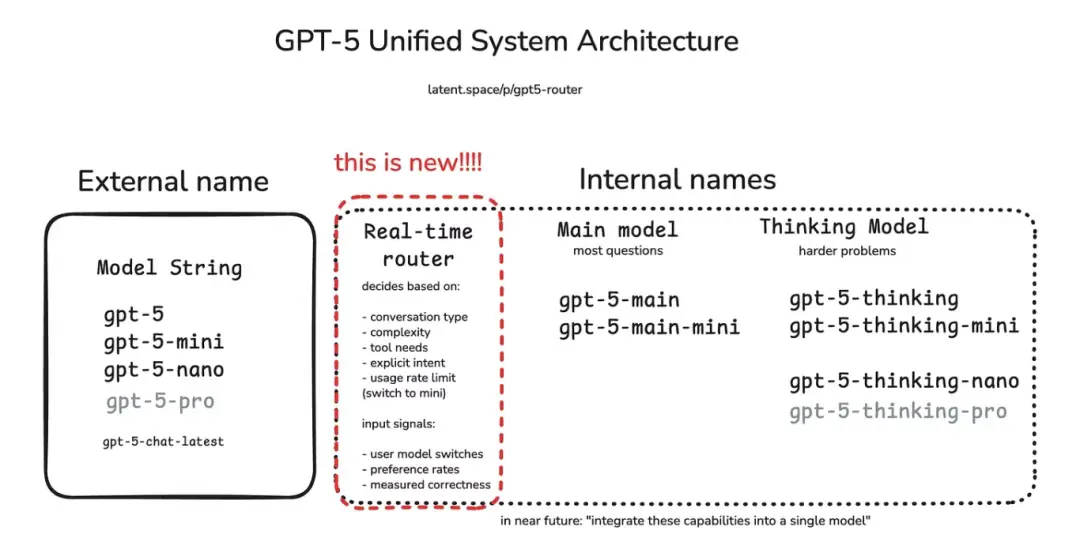
初次與 GPT-5 對話時,我就意識到它不僅是在回答問題,更在精心選擇迴應方式。其背後的智能“路由器”會將每個問題分配給最合適的處理模塊:輕量級核心模型瞬間處理各類簡單問題和總結摘要類任務,重量級的 GPT-5 思考模型則專攻複雜推理,而需要工具支持時,“路由器”會啓動計算器或外部檢索功能。

這種架構變革的意義十分重大。如今的 GPT-5 不再是一個單一系統,更像是由“路由器”協調的專家網絡。在本期《Where’s The Future in Tech》中,我將解析其運行機制,對比歷代模型的差異,並探討其中預示的人工智能設計新方向。
01 為什麼路由機制現在非常重要?
坦白説,早在 GPT-4 面世時,我們就已發現一個比較嚴重的問題 —— 無論是創作莎士比亞風格的詩歌還是檢查是否有拼寫錯誤,人們都在使用同一個龐然大物。這簡直就是用火箭發動機烤麪包 —— 雖然可行,但既浪費資源、成本高昂,又常常大材小用。
GPT-5 的路由機制徹底改變了這種局面。它不再每次都啓動火箭引擎,而是通過路由系統快速分析請求並分配到合適的處理路徑:
- 簡單閒聊? → 分流至快速的輕量級模型
- 複雜推理? → 導向 GPT-5 的核心思考模塊
- 數理邏輯? → 轉至 symbolic tool(譯者注:利用傳統編程和數學規則來保證結果精確性的工具)或計算器
- 結構化任務(SQL、API)? → 分配給專用任務執行器
02 路由機制的四大支柱
GPT-5 在決定啓動哪個“大腦”時究竟考量哪些因素?通過日常使用並研讀 OpenAI 的技術文檔後,我發現其核心邏輯可歸納為四大要素:對話類型(conversation type)、任務複雜度(task complexity)、工具需求(tool needs)及顯性的用户意圖(explicit user intent)。
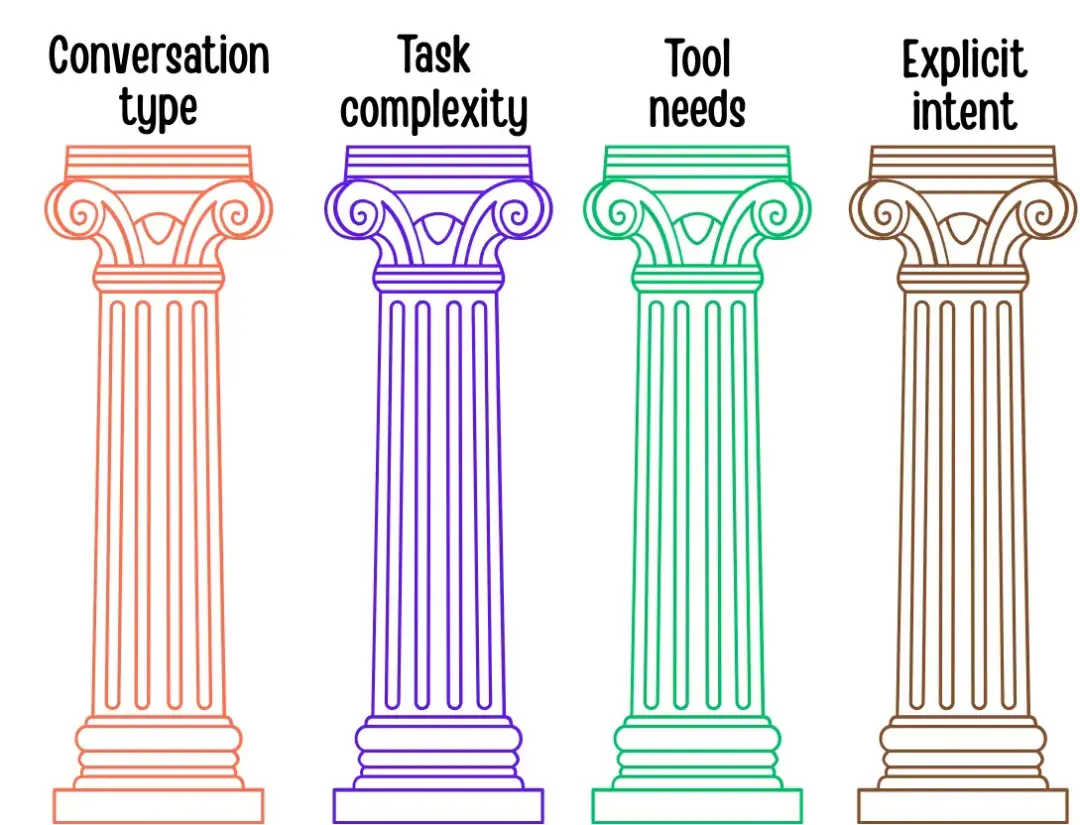
1. 對話類型
當前對話是隨意閒聊,還是代碼審查、數學證明或故事草稿等結構化任務?GPT-5 已學會為不同對話類型匹配最優的處理模型。例如關於週末計劃的閒聊會啓用高速響應模式,而分步驟推導定理則會立即激活深度思考模式。
2. 任務複雜度
當指令看起來比較複雜時,GPT-5 會立即調用重量級推理模型。用技術術語來説,路由器能識別出你話語中隱含的、關於任務難度的細微信號,並分配更強大的模型來處理。正如 AIMultiple 所指:GPT-5採用多模型混合架構,根據提示詞複雜度與響應速度需求進行路由 —— 既避免在簡單任務上耗費算力,也確保複雜需求得到充分解決。
3. 工具需求
一旦指令中出現“計算”、“查詢”或“起草郵件”等關鍵詞,路由器會自動調度配備專用工具的模型。與早期需手動啓用插件的系統不同,現在的 GPT-5 會隱形處理這一過程:若查詢明顯需要執行代碼或訪問數據庫,系統將自動移交專屬模型。早期測試顯示,憑藉更精準的路由與專業化分工,GPT-5 的工具調用錯誤率較 GPT-4 降低近 50%。
4. 顯性的用户意圖
一般情況下,路由器會直接響應用户指令。若輸入“請深入思考”,系統會立即啓動深度推理模式。筆者測試過“快速總結”與“深度剖析”等具有細微差異的不同措辭,能清晰觀察到 GPT-5 在實時切換處理模式 —— 這彷彿解鎖了新的“軟指令”層,用户措辭對路由決策的影響程度,已不亞於系統內置的啓發式規則。
03 超越 Toolformer 與內置插件的一次飛躍
有些人可能還記得 Toolformer[1]:那是 2023 年的一篇論文,這項研究讓語言模型在訓練中自學通過 API 調用外部工具。這個想法很聰明,但卻是靜態的 —— 模型僅能從數據集中的信號 tokens 學習固定的規則,比如“此處使用計算器”。部署完成後,它就無法超越自己的記憶範圍進行適配。
GPT-5 的路由器則截然不同,它能在運行時動態做出決策。它不會機械地複述預設指令,而是像一位實時在線的助手 —— 聽到你的問題後,能當場判斷:“我現在應該調用計算器了。”
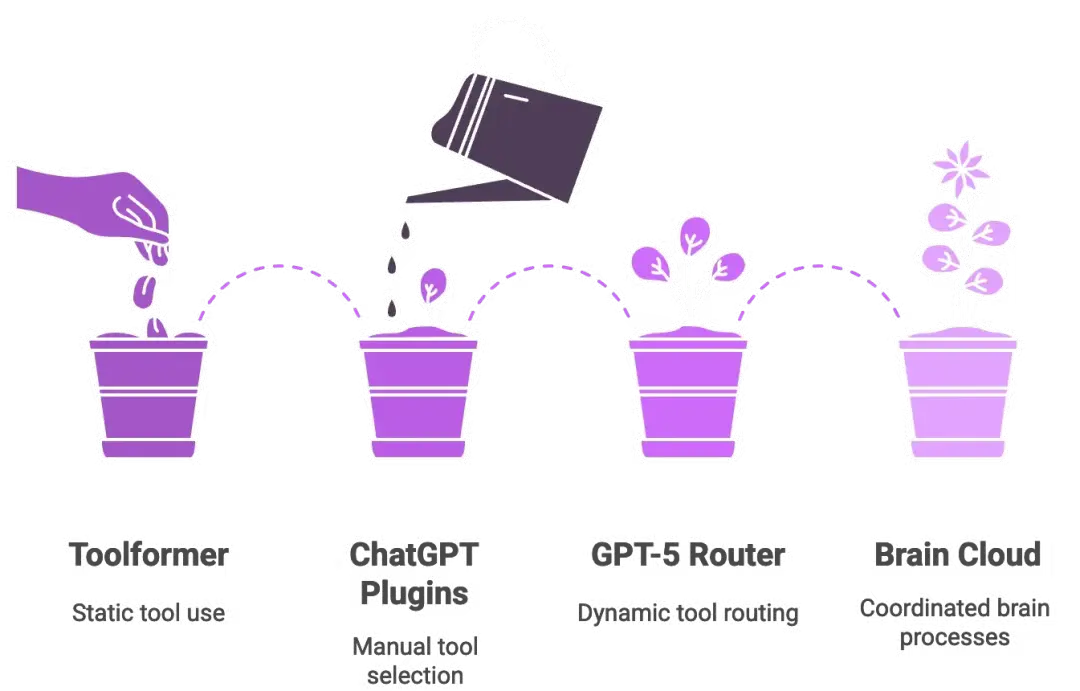
ChatGPT 曾經的插件同樣存在類似的侷限:用户必須手動啓用插件,並明確指示“用 Wolfram Alpha 進行數學計算”。GPT-5 則用一個內置的策略層取代了這種模式。只要用户查詢需要調用工具,路由器就會直接將請求路由到已連接相應工具的合適模型。即便是新 API 中推出的自定義工具,其後端也依賴這套路由系統。
簡言之,GPT-5 融合了 Toolformer 的自主工具調用能力與 ChatGPT 的插件生態,但在中間加入了一位實時的“交通指揮員”。如果説 GPT-4 像一台獨立的超級計算機,那麼 GPT-5 則更像是由路由器協調的一組雲端腦處理單元(cloud of brain processes)。如果你曾經調試過微服務,立刻就能明白這個比喻為何如此貼切。
04 構建屬於你自己的 GPT-5 式路由器
現在,我知道你可能會想:“這個概念很酷,但我到底該怎麼自己動手做出類似的東西呢?”幸運的是,你並不需要像 OpenAI 那樣擁有無限算力才能嘗試。藉助當前的開源生態,你完全可以在自己的機器上搭建一個輕量級的 GPT-5 式路由器。以下是一種可行的實現思路:
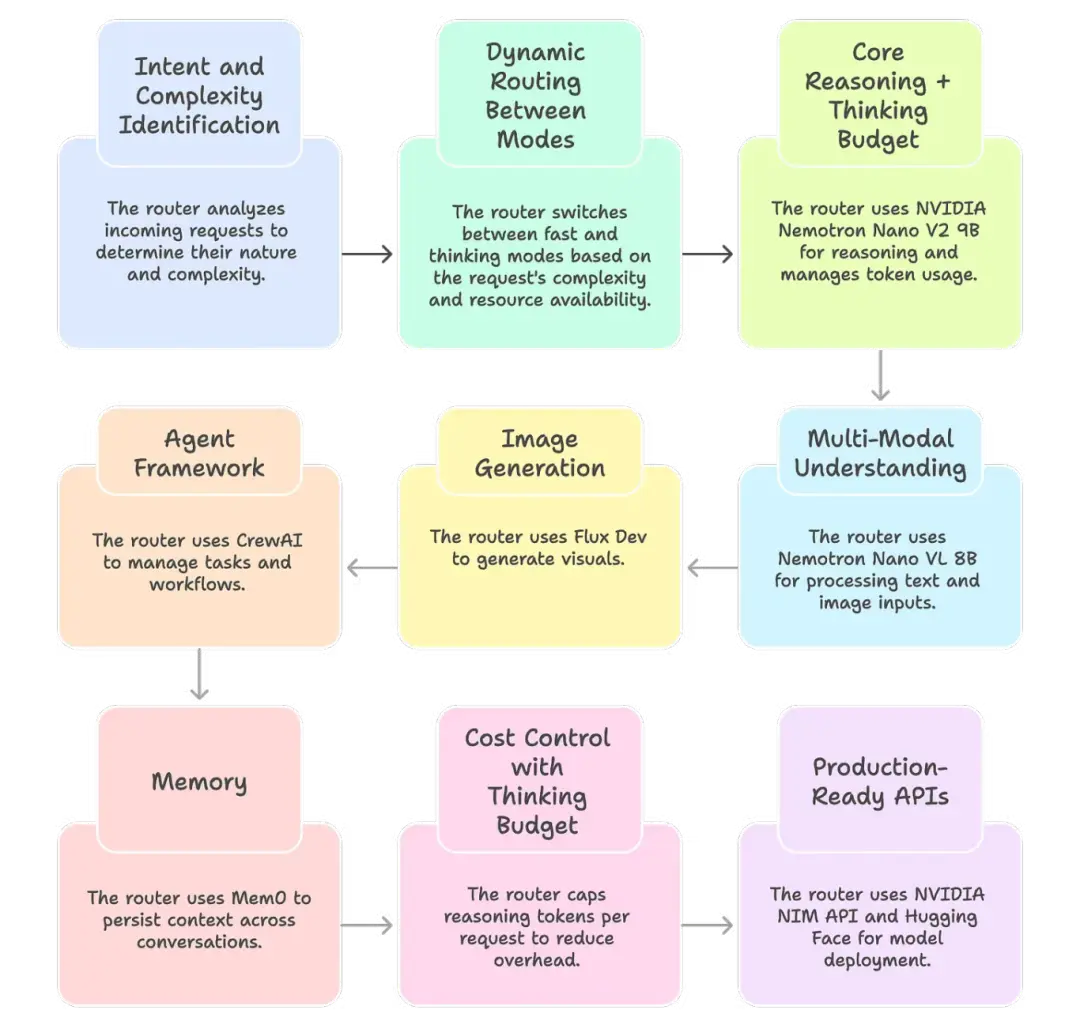
1. 用户意圖與請求複雜度識別
路由器必須首先理解請求的類型:是快速的事實信息查詢、需要大量推理過程的數學證明題、還是圖像生成需求,還是需要瀏覽網頁呢?一個輕量級的分類器(甚至小型 LLM)即可完成這項工作。
2. 不同模式間的動態路由
路由器會智能地在不同模式間進行切換,而非一致地處理所有查詢:
- 快速模式:將查詢發送給低延遲模型以獲取快速響應
- 思考模式:啓用推理 token 進行更長時間的思考,以便處理需要深度邏輯分析、權衡多種因素、或通過多個步驟才能解決的複雜問題
- 備用模式:當 GPU 顯存緊張時,就將請求路由到更小的備用模型,從而確保系統永不宕機
3. 底層技術架構
以下是一套可落地的開源方案:
- 核心推理引擎 + 資源限制機制(thinking budget) → NVIDIA[2] Nemotron Nano V2 9B(一款混合了 Mamba 與 Transformer 架構的模型,兼容 RTX 顯卡,支持 token 使用量調控)
- 多模態理解 → Nemotron Nano VL 8B(支持文本 + 圖像輸入)
- 圖像生成 → Flux Dev(視覺內容生成)
- 智能體框架 → CrewAI[3](任務管理與工作流管理)
- 記憶模塊 → Mem0[4](跨對話上下文持久化)
僅憑該技術棧,我們就能構建出與 GPT-5 底層運作極為相似的路由器系統。
4. 通過資源限制機制(thinking budget)控制成本
並非每個指令都需要“耗費萬枚 token 的深度思考”。通過限制單次請求的推理 token 上限,可大幅降低開銷。採用這種方法的團隊報告稱,該方法最高可節省 60% 成本,因為路由器只在真正需要的地方投入算力。
5. 面向生產的 API
NVIDIA 已通過 NIM API 和 Hugging Face 提供這些模型。這意味着你無需從頭訓練,現在即可接入模型開始實驗。
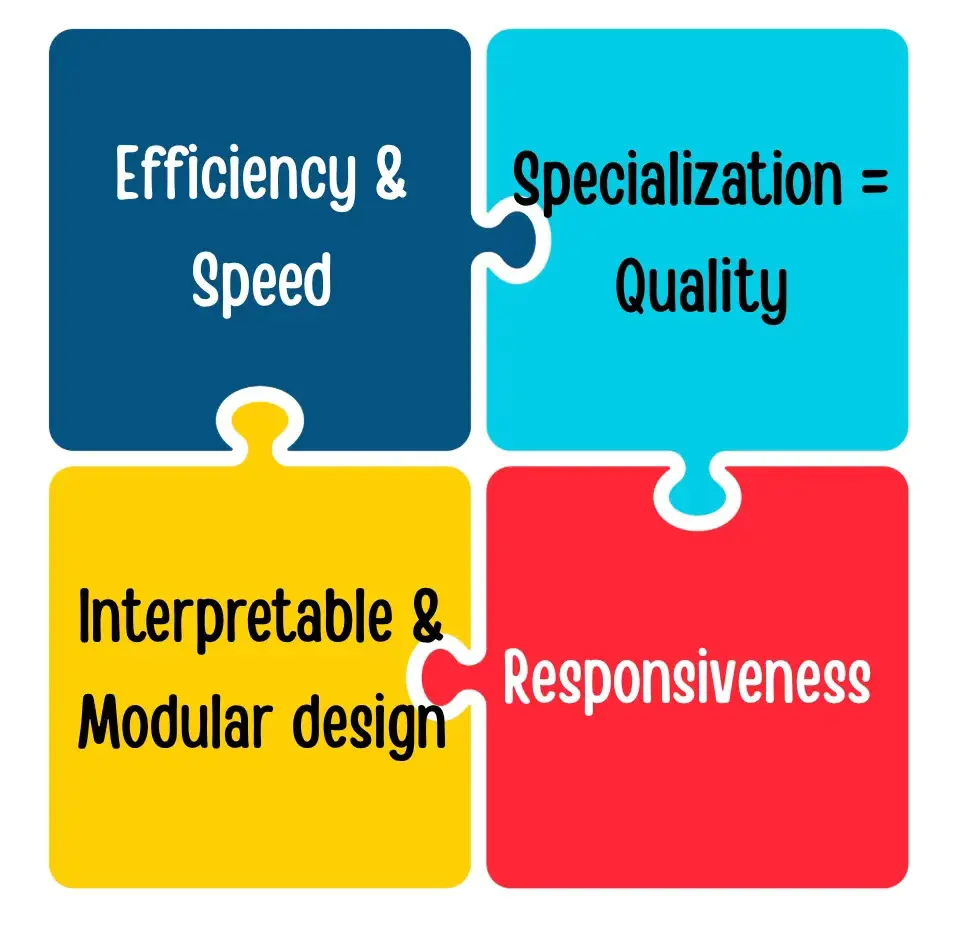
05 GPT-5 路由器的核心優勢
-
效率與速度
- 大多數查詢默認交給快速模型處理,大幅節省算力
- 輕量級任務不再佔用深度推理引擎資源
- OpenAI 曾暗示,當系統負載過高時,“mini”模型可以接手低優先級的用户查詢,實現彈性擴展
-
響應速度
- 對於基礎問題,GPT-5 能“即時”作答,在基準測試中通常比 GPT-4 Turbo 快 2–3 倍
- 自動路由機制意味着用户無需手動切換模型 —— 需要速度時自動給出快速回答,需要深度時則提供深入分析
- 保留“快速模式/思考模式”的手動切換開關,滿足用户精準控制的需求
-
可解釋性與模塊化設計
- 每個子模型都專注於特定領域,支持獨立迭代升級
- 錯誤定位更精準:可區分“路由選擇失誤”與“模型推理錯誤”
- 這就像 AI 流水線中的微服務架構 —— 模塊化、職責清晰、更易維護
-
專業化 = 更高質量
- 子模型針對特定場景進行了專項優化:例如,“thinking” 模型用於多步驟推理,“main” 模型用於簡潔準確的知識輸出
- 兼顧兩者優勢:兼具 GPT-4 級別的知識深度與 GPT-3 級別的響應速度
- 支持對話中無縫切換模式,比如從頭腦風暴無縫切換到代碼處理,無需用户顯式指令
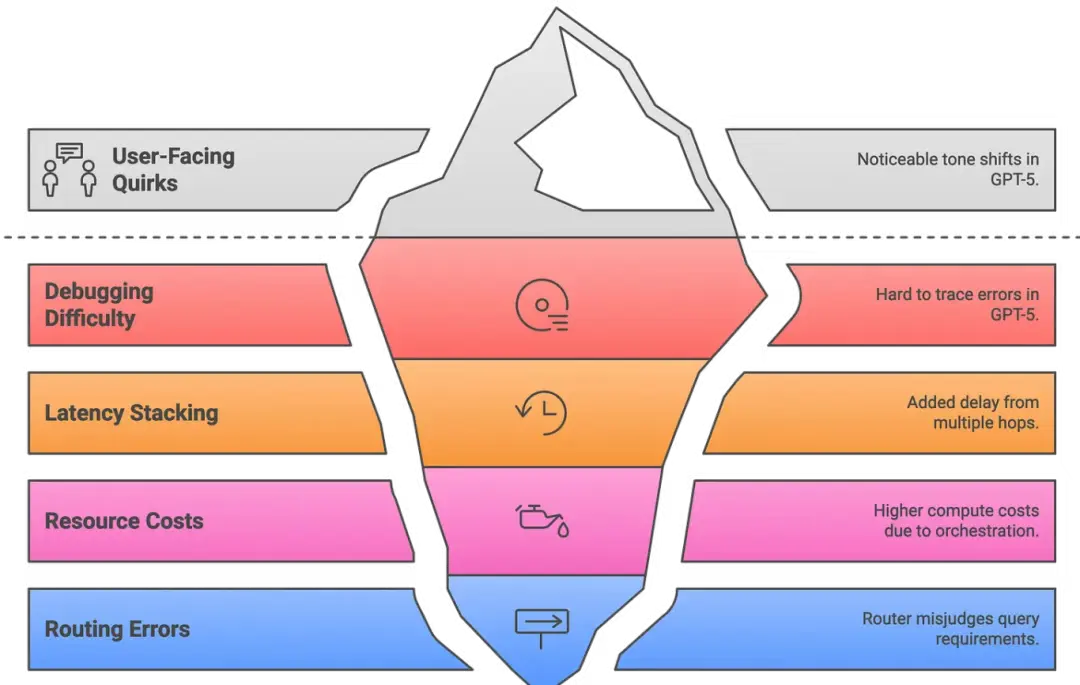
06 隱憂與挑戰:侷限性分析
-
調試困難
- 錯誤溯源困難:問題究竟源於路由器選錯模型,還是所選模型自身的失誤?
- 調試過程更接近分佈式系統,而非單一單體架構
- 需藉助專用追蹤工具(借鑑 Amazon Bedrock 框架)記錄每個環節:路由決策、工具調用、中間結果、最終的輸出整合
- 任何環節出錯都意味着“需要檢查的動態部件更多了”
-
延遲疊加
- 每一次額外的跳轉(例如主模型→思考模型→數學工具→返回計算結果→最終答案)都會增加延遲
- 簡單問題通常會繞過中間層,但複雜查詢可能會明顯變慢
- Amazon 的多智能體報告就曾警告過這一點:串行推理鏈越長,開銷越大
- 緩解方案:並行調用(parallelizing calls) + 結果緩存(caching results),但多工具工作流的響應速度仍可能低於單次 GPT-4 調用
-
資源成本
- 多個小型模型有時反而比單個大模型消耗更多算力,必須精細調整路由器的閾值,確保邊界任務被分配給更快的模型
- 第三方研究發現,ChatGPT-5 在某些查詢中使用的 token 數量是 GPT-4 的兩倍,原因在於編排過程帶來的額外開銷
- OpenAI 也承認 GPT-5 雖追求效率,但可能“更耗算力”
- 本質是更智能的資源分配與更高的系統複雜度之間的權衡
-
用户體驗偏差
- 一些用户已經注意到語氣差異:思考模式(正式、嚴謹) vs 主模式(自然、流暢)
- 通過“人格過濾器”對輸出進行風格對齊,確保用户感知到的始終是一個連貫、統一、有辨識度的對話夥伴
- 若未經調優,對話可能感覺像多個風格略有差異的 AI 在輪流發言
- 正如一句調侃所説:“GPT-5 的大腦很聰明,但可能存在身份認知危機”
-
路由失誤
- 路由器有時會誤判:該用“深度模式”的問題卻選擇了“快速模式”,反之亦然
- 通過“模型切換”事件進行檢測(例如用户點擊“重新生成”答案時)
- 最終補救措施仍是用户點擊“重新生成”,然後期待路由器作出不同選擇
- 每次切換都需重新加載靜態提示詞,既增加延遲,又增加 token 消耗
- 實際應用中,回答過程中的模式切換會破壞“流暢對話”的體驗
07 這一技術將如何影響 AI 的未來發展?
GPT-5 的“路由器 + 多模型”架構講述了一個更大的故事:AI 正在告別“一刀切”的單一模型時代。研究人員長期以來一直在探討模塊化與 Agentic AI,而 GPT-5 正是這一轉變正在發生的最清晰例證之一。正如某份分析所言,GPT-5 的“多智能體架構(路由器 + 模型)”暗示了我們未來可能會如何設計模塊化的 AI 系統,來突破單一模型的侷限。用通俗的話説,未來大語言模型系統將由專家網絡構成,而不是依賴一個“全能的”通用模型。
未來的 AI 很可能會變得更像多個智能體協同工作,而非由單一模型包攬一切。我們或許很快會看到更加細粒度的專家模型(一些實驗室已在測試“100-expert LLMs”),由一箇中央控制器協調調度。GPT-5 已經證明,只要硬件持續進化,這種因為協調過程而產生的開銷是值得的。因此,如果 GPT-6 或 Gemini Next 配備了一個超強路由器,管理數十個子模型,或者插件演變為由元模型(metamodel)按需調用的自主“智能體”,你也不必感到驚訝。
前方的挑戰
當然,模塊化並非沒有代價。GPT-5 也凸顯了我們必須解決的幾大挑戰:
- 未來需要統一的模型,最終將各種專業化角色融合進一個“大腦”中。
- 通過更智能的緩存技術,來避免路由過程中因重複加載靜態提示詞而產生的額外開銷。
- 需要更強大的溯源工具,來幫助開發者調試由多個智能體協同完成的複雜對話。
- 採用更高級的路由器訓練方法(例如強化學習),讓路由器真正學會最優的決策策略。
儘管如此,GPT-5 的設計清楚地表明瞭一點:模塊化已成定局。這種架構正反映了人類組織知識的方式——由專業化專家團隊協作完成複雜任務。如今,AI 終於開始迎頭趕上。
08 Final thoughts
在使用 GPT-5 數月之後,我既感到興奮,也心懷敬畏。實時路由器已將這個模型從一個孤獨的“天才”,轉變為一個由多個專家組成的協作集體。 路由器和專家模型的分工架構在帶來效率和能力提升的同時,也帶來了一個挑戰:如何讓這個分佈式系統中的所有部件保持協調一致、同步工作。就像樂隊成員必須聽從指揮、節奏統一,否則再厲害的樂手也奏不出和諧樂章。
最讓我興奮的是,GPT-5 證明了人工智能不必是一個單一、龐大的整體。我們可以實現“按需專業化” —— 系統不僅能學會如何學習,還能針對每個查詢動態調整自己的策略。作為一名開發者,我甚至學會了如何“與路由器對話”—— 通過類似 “Auto mode” 或 “Fast” 這樣的提示詞來引導它。展望未來,如果 GPT-6 的表現更像一個“心智社會”(譯者注:society of minds,是一個在人工智能和認知科學領域非常著名且富有詩意的概念,由 Marvin Minsky 提出。它認為智能並非源於一個單一的、統一的處理器,而是由大量簡單的、各司其職的“智能體”通過交互、協作與競爭涌現出來的。),我也不會感到意外。但就目前而言,GPT-5 的路由機制已經是一個令人着迷的里程碑,我很慶幸自己有機會深入探索它。
END
本期互動內容 🍻
❓你覺得 AI 的“人格一致性”重要嗎?如果一次對話中因為調用不同模塊導致語氣不同,你會覺得割裂嗎?
文中鏈接
[1]https://arxiv.org/abs/2302.04761
[2]https://www.nvidia.com/en-in/
[3]https://www.crewai.com/
[4]https://mem0.ai/
本文經原作者授權,由 Baihai IDP 編譯。如需轉載譯文,請聯繫獲取授權。
原文鏈接:
https://bhavishyapandit9.substack.com/p/gpt5-router-a-deep-dive












