









TVM 先已更新到 0.21.0 版本,TVM 中文文檔已經和新版本對齊。
Apache TVM 是一個深度的深度學習編譯框架,適用於 CPU、GPU 和各種機器學習加速芯片。更多 TVM 中文文檔可訪問 →Apache TVM
Apache TVM 的一個主要設計目標是便於自定義優化流程,無論是用於科研探索還是工程開發,都可以靈活迭代優化過程。本教程將涵蓋以下內容:
目錄
- 審查整體流程
- 可組合的 IRModule 優化
- 部署優化後的模型
- 總結
審查整體流程
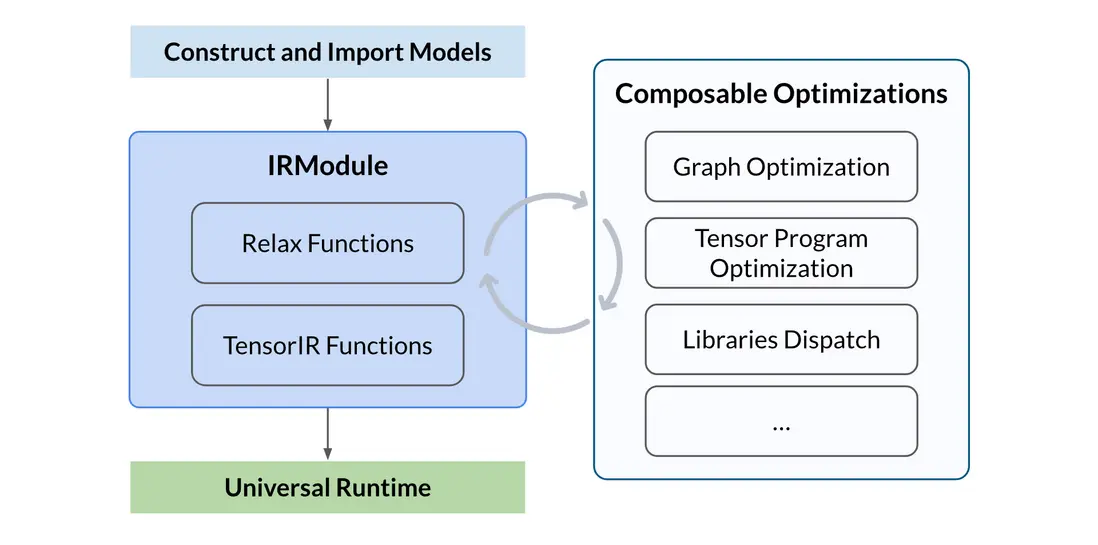
整體流程包括以下幾個步驟:
- 構建或導入模型:可以手動構建一個神經網絡模型,或從其他框架(如 PyTorch、ONNX)中導入一個預訓練模型,並生成 TVM 的 IRModule。該模塊包含編譯所需的所有信息,包括用於表示計算圖的高層 Relax 函數,以及用於描述張量程序的低層 TensorIR 函數
- 執行可組合優化:執行一系列優化轉換,包括計算圖優化、張量程序優化和算子調度/分發等
- 構建並進行通用部署:將優化後的模型構建為可部署模塊,使用 TVM 通用運行時在不同設備上運行,例如 CPU、GPU 或其他加速器
import os
import tempfile
import numpy as np
import tvm
from tvm import IRModule, relax
from tvm.relax.frontend import nn可組合的 IRModule 優化
Apache TVM Unity 提供了一種靈活的方式來優化 IRModule。圍繞 IRModule 的所有優化都可以與現有的編譯流水線進行組合。值得注意的是, 每個優化步驟可以只關注計算圖的一部分, 從而實現局部下沉或局部優化。
在本教程中,我們將演示如何使用 Apache TVM Unity 優化模型。
準備 Relax 模塊
我們首先準備一個 Relax 模塊。該模塊可以通過從其他框架導入、使用神經網絡前端構建,或直接使用 TVMScript 來創建。這裏我們以一個簡單的神經網絡模型為例。
class RelaxModel(nn.Module):
def __init__(self):
super(RelaxModel, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(256, 10, bias=False)
def forward(self, x):
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
return x
input_shape = (1, 784)
mod, params = RelaxModel().export_tvm({"forward": {"x": nn.spec.Tensor(input_shape, "float32")}})
mod.show()輸出:
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def forward(x: R.Tensor((1, 784), dtype="float32"), fc1_weight: R.Tensor((256, 784), dtype="float32"), fc1_bias: R.Tensor((256,), dtype="float32"), fc2_weight: R.Tensor((10, 256), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"num_input": 1})
with R.dataflow():
permute_dims: R.Tensor((784, 256), dtype="float32") = R.permute_dims(fc1_weight, axes=None)
matmul: R.Tensor((1, 256), dtype="float32") = R.matmul(x, permute_dims, out_dtype="void")
add: R.Tensor((1, 256), dtype="float32") = R.add(matmul, fc1_bias)
relu: R.Tensor((1, 256), dtype="float32") = R.nn.relu(add)
permute_dims1: R.Tensor((256, 10), dtype="float32") = R.permute_dims(fc2_weight, axes=None)
matmul1: R.Tensor((1, 10), dtype="float32") = R.matmul(relu, permute_dims1, out_dtype="void")
gv: R.Tensor((1, 10), dtype="float32") = matmul1
R.output(gv)
return gv庫調度
我們希望能夠快速在特定平台(例如 GPU)上嘗試某種庫優化的變體。我們可以為特定平台和算子編寫專屬的調度 pass。這裏我們將展示如何為某些模式調度 CUBLAS 庫。
備註
本教程僅演示了一個針對 CUBLAS 的單個算子調度,用於突出優化流程的靈活性。在實際案例中,我們可以導入多個模式,並將它們分別調度到不同的內核中。
# 導入 cublas 模式
import tvm.relax.backend.cuda.cublas as _cublas
# 定義一個用於 CUBLAS 調度的新 pass
@tvm.transform.module_pass(opt_level=0, name="CublasDispatch")
class CublasDispatch:
def transform_module(self, mod: IRModule, _ctx: tvm.transform.PassContext) -> IRModule:
# 檢查是否啓用了 CUBLAS
if not tvm.get_global_func("relax.ext.cublas", True):
raise Exception("CUBLAS is not enabled.")
# 獲取目標匹配模式
patterns = [relax.backend.get_pattern("cublas.matmul_transposed_bias_relu")]
# 注意,在實際情況中,通常會獲取所有以 "cublas" 開頭的模式
# patterns = relax.backend.get_patterns_with_prefix("cublas")
# 按照模式融合操作,並運行代碼生成
mod = relax.transform.FuseOpsByPattern(patterns, annotate_codegen=True)(mod)
mod = relax.transform.RunCodegen()(mod)
return mod
mod = CublasDispatch()(mod)
mod.show()輸出:
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
I.module_attrs({"external_mods": [metadata["runtime.Module"][0]]})
@R.function
def forward(x: R.Tensor((1, 784), dtype="float32"), fc1_weight: R.Tensor((256, 784), dtype="float32"), fc1_bias: R.Tensor((256,), dtype="float32"), fc2_weight: R.Tensor((10, 256), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"num_input": 1})
with R.dataflow():
lv = R.call_dps_packed("fused_relax_permute_dims_relax_matmul_relax_add_relax_nn_relu_cublas", (fc1_weight, x, fc1_bias), out_sinfo=R.Tensor((1, 256), dtype="float32"))
permute_dims1: R.Tensor((256, 10), dtype="float32") = R.permute_dims(fc2_weight, axes=None)
matmul1: R.Tensor((1, 10), dtype="float32") = R.matmul(lv, permute_dims1, out_dtype="void")
gv: R.Tensor((1, 10), dtype="float32") = matmul1
R.output(gv)
return gv
# 元數據被省略。要顯示元數據,請在 script() 方法中使用 show_meta=True。在執行調度 pass 後,我們可以看到原始的 nn.Linear 和 nn.ReLU 已被融合,並重寫為調用 CUBLAS 庫的 call_dps_packed 函數。值得注意的是,計算圖中的其他部分並未改變,這意味着我們可以選擇性地對某些計算部分進行優化調度。
自動調優
接着前面的例子,我們可以通過自動調優進一步優化模型剩餘的計算部分, 這裏我們演示如何使用 Meta Schedule 對模型進行自動調優。
我們可以使用 MetaScheduleTuneTIR Pass 來對模型進行簡單的調優,而使用 MetaScheduleApplyDatabase Pass 則可以將最優配置應用到模型中。調優過程會生成搜索空間,對模型進行調優,隨後將最優配置應用到模型中。在運行這些 Pass 之前,我們需要通過 LegalizeOps 將 relax 操作符下沉為 TensorIR 函數。
備註
為了節省 CI 時間並避免波動性,我們在 CI 環境中跳過了調優過程。
device = tvm.cuda(0)
target = tvm.target.Target.from_device(device)
if os.getenv("CI", "") != "true":
trials = 2000
with target, tempfile.TemporaryDirectory() as tmp_dir:
mod = tvm.ir.transform.Sequential(
[
relax.get_pipeline("zero"),
relax.transform.MetaScheduleTuneTIR(work_dir=tmp_dir, max_trials_global=trials),
relax.transform.MetaScheduleApplyDatabase(work_dir=tmp_dir),
]
)(mod)
mod.show()DLight 規則
DLight 規則是一組用於調度和優化內核的默認規則。DLight 規則設計的目標是快速編譯與公平性能的折中。 在某些場景(例如語言模型)下,DLight 能提供非常優秀的性能;而在通用模型場景中,則更注重性能與編譯時間之間的平衡。
from tvm import dlight as dl
# 應用 DLight 規則
with target:
mod = tvm.ir.transform.Sequential(
[
relax.get_pipeline("zero"),
dl.ApplyDefaultSchedule( # pylint: disable=not-callable
dl.gpu.Matmul(),
dl.gpu.GEMV(),
dl.gpu.Reduction(),
dl.gpu.GeneralReduction(),
dl.gpu.Fallback(),
),
]
)(mod)
mod.show()輸出:
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
I.module_attrs({"external_mods": [metadata["ffi.Module"][0]]})
@T.prim_func(private=True)
def matmul(lv: T.Buffer((T.int64(1), T.int64(256)), "float32"), permute_dims1: T.Buffer((T.int64(256), T.int64(10)), "float32"), matmul: T.Buffer((T.int64(1), T.int64(10)), "float32")):
T.func_attr({"op_pattern": 4, "tir.is_scheduled": True, "tir.noalias": True})
# with T.block("root"):
matmul_rf_local = T.alloc_buffer((T.int64(16), T.int64(1), T.int64(10)), scope="local")
for ax0_fused_0 in T.thread_binding(T.int64(1), thread="blockIdx.x"):
for ax0_fused_1 in T.thread_binding(T.int64(10), thread="threadIdx.x"):
for ax1_fused_1 in T.thread_binding(T.int64(16), thread="threadIdx.y"):
with T.block("matmul_rf_init"):
vax1_fused_1 = T.axis.spatial(T.int64(16), ax1_fused_1)
v0 = T.axis.spatial(T.int64(10), ax0_fused_0 * T.int64(10) + ax0_fused_1)
T.reads()
T.writes(matmul_rf_local[vax1_fused_1, T.int64(0), v0])
matmul_rf_local[vax1_fused_1, T.int64(0), v0] = T.float32(0.0)
for ax1_fused_0, u in T.grid(T.int64(16), 1):
with T.block("matmul_rf_update"):
vax1_fused_1 = T.axis.spatial(T.int64(16), ax1_fused_1)
v0 = T.axis.spatial(T.int64(10), ax0_fused_0 * T.int64(10) + ax0_fused_1)
vax1_fused_0 = T.axis.reduce(T.int64(16), ax1_fused_0)
T.reads(matmul_rf_local[vax1_fused_1, T.int64(0), v0], lv[T.int64(0), vax1_fused_0 * T.int64(16) + vax1_fused_1], permute_dims1[vax1_fused_0 * T.int64(16) + vax1_fused_1, v0])
T.writes(matmul_rf_local[vax1_fused_1, T.int64(0), v0])
matmul_rf_local[vax1_fused_1, T.int64(0), v0] = matmul_rf_local[vax1_fused_1, T.int64(0), v0] + lv[T.int64(0), vax1_fused_0 * T.int64(16) + vax1_fused_1] * permute_dims1[vax1_fused_0 * T.int64(16) + vax1_fused_1, v0]
for ax1_fused in T.thread_binding(T.int64(10), thread="threadIdx.x"):
for ax0 in T.thread_binding(T.int64(16), thread="threadIdx.y"):
with T.block("matmul"):
vax1_fused_1, v0 = T.axis.remap("RS", [ax0, ax1_fused])
T.reads(matmul_rf_local[vax1_fused_1, T.int64(0), v0])
T.writes(matmul[T.int64(0), v0])
with T.init():
matmul[T.int64(0), v0] = T.float32(0.0)
matmul[T.int64(0), v0] = matmul[T.int64(0), v0] + matmul_rf_local[vax1_fused_1, T.int64(0), v0]
@T.prim_func(private=True)
def transpose(fc2_weight: T.Buffer((T.int64(10), T.int64(256)), "float32"), T_transpose: T.Buffer((T.int64(256), T.int64(10)), "float32")):
T.func_attr({"op_pattern": 2, "tir.is_scheduled": True, "tir.noalias": True})
# with T.block("root"):
for ax0_ax1_fused_0 in T.thread_binding(T.int64(3), thread="blockIdx.x"):
for ax0_ax1_fused_1 in T.thread_binding(T.int64(1024), thread="threadIdx.x"):
with T.block("T_transpose"):
v0 = T.axis.spatial(T.int64(256), (ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1) // T.int64(10))
v1 = T.axis.spatial(T.int64(10), (ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1) % T.int64(10))
T.where(ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1 < T.int64(2560))
T.reads(fc2_weight[v1, v0])
T.writes(T_transpose[v0, v1])
T_transpose[v0, v1] = fc2_weight[v1, v0]
@R.function
def forward(x: R.Tensor((1, 784), dtype="float32"), fc1_weight: R.Tensor((256, 784), dtype="float32"), fc1_bias: R.Tensor((256,), dtype="float32"), fc2_weight: R.Tensor((10, 256), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"num_input": 1})
cls = Module
with R.dataflow():
lv = R.call_dps_packed("fused_relax_permute_dims_relax_matmul_relax_add_relax_nn_relu_cublas", (fc1_weight, x, fc1_bias), out_sinfo=R.Tensor((1, 256), dtype="float32"))
permute_dims1 = R.call_tir(cls.transpose, (fc2_weight,), out_sinfo=R.Tensor((256, 10), dtype="float32"))
gv = R.call_tir(cls.matmul, (lv, permute_dims1), out_sinfo=R.Tensor((1, 10), dtype="float32"))
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.備註
本教程的重點是展示優化流程,而不是將性能推至極限。因此當前的優化策略可能並非最佳配置。
部署優化後的模型
我們可以將優化後的模型構建並部署到 TVM 的運行時中。
ex = tvm.compile(mod, target="cuda")
dev = tvm.device("cuda", 0)
vm = relax.VirtualMachine(ex, dev)
# 需要在 GPU 設備上分配數據和參數
data = tvm.runtime.tensor(np.random.rand(*input_shape).astype("float32"), dev)
gpu_params = [tvm.runtime.tensor(np.random.rand(*p.shape).astype(p.dtype), dev) for _, p in params]
gpu_out = vm["forward"](data, *gpu_params).numpy()
print(gpu_out)輸出:
[[25165.08 22909.219 25461.871 24852.129 24942.432 24389.219 24460.203
26586.521 23572.797 26839.176]]本教程展示瞭如何在 Apache TVM 中自定義機器學習模型的優化流程。我們可以輕鬆組合優化 pass,並針對計算圖中的不同部分定製優化策略。優化流程的高度靈活性使我們能夠快速迭代優化步驟,從而提升模型性能。
- 下載 Jupyter Notebook:customize_opt.ipynb
- 下載 Python 源代碼:customize_opt.py
- 下載壓縮包:customize_opt.zip












