









特徵越多模型效果就越好?這個想法在實踐中往往站不住腳,因為過多的特徵反而會帶來過擬合、訓練時間過長、模型難以解釋等一堆麻煩。遞歸特徵消除(RFE)就是用來解決這類問題的,算是特徵選擇裏面比較靠譜的方法之一。
本文會詳細介紹RFE 的工作原理,然後用 scikit-learn 跑一個完整的例子。
RFE 是什麼
遞歸特徵消除本質上是個反向篩選過程。它會先用全部特徵訓練模型,然後根據模型給出的重要性評分把最不重要的特徵踢掉,接着用剩下的特徵重新訓練,如此反覆直到達到設定的特徵數量。
這可以理解成雕刻的過程,一點點削掉不重要的部分,最後留下對預測真正有用的核心特徵。
RFE 比單變量特徵選擇高明的地方在於,它考慮了特徵之間的交互關係。每次刪掉特徵後都會重新訓練,這樣能捕捉到特徵組合的效果。
RFE 適用範圍比較廣,只要模型能給出特徵重要性就能用。它會自己考慮特徵之間怎麼配合,這點很關鍵。刪掉無關特徵後模型泛化能力會更好,不容易過擬合。特徵少了模型自然更好理解,訓練和預測的速度也快。
實際操作
我們這次用 sklearn 自帶的葡萄酒數據集。這個數據集有 13 個化學特徵,任務是預測葡萄酒的類別。先把需要的庫導入:
# importing necessary libraries
import numpy as np
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import RFE, RFECV
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
# loading the wine dataset
wine = load_wine()
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = wine.target
print(f"Dataset shape: {X.shape}")
print(f"Number of classes: {len(np.unique(y))}")
print(f"\nFeature names:")
print('*'*15)
for col in X.columns:
print(col)看下輸出:

數據集有 178 個樣本,13 個特徵,3 個類別。接下來我們做數據準備和基線測試:
# train-test splitting
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# scaling the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# baseline model including all features
baseline_model = LogisticRegression(max_iter=1000, random_state=42)
baseline_model.fit(X_train_scaled, y_train)
baseline_score = baseline_model.score(X_test_scaled, y_test)
print(f"Baseline accuracy with all {X.shape[1]} features: {baseline_score:.3f}")
用全部特徵訓練的邏輯迴歸準確率是 0.981,這個作為基準線。
固定特徵數量的 RFE
現在用 RFE 篩選 5 個最重要的特徵:
# initializing the estimator
estimator = LogisticRegression(max_iter=1000, random_state=42)
# creating and fitting the RFE object to select best 5 features
rfe = RFE(estimator, n_features_to_select=5, step=1)
rfe.fit(X_train_scaled, y_train)
# view the selected features
selected_features = X.columns[rfe.support_].tolist()
print(f"\nSelected features: {selected_features}")
# we can also get the feature rankings (where 1 is best)
feature_ranking = pd.DataFrame({
'feature': X.columns,
'ranking': rfe.ranking_
}).sort_values('ranking')
print("\nFeature Rankings:")
display(feature_ranking)
# model with selected features
X_train_rfe = rfe.transform(X_train_scaled)
X_test_rfe = rfe.transform(X_test_scaled)
rfe_model = LogisticRegression(max_iter=1000, random_state=69)
rfe_model.fit(X_train_rfe, y_train)
rfe_score = rfe_model.score(X_test_rfe, y_test)
print(f"\nRFE accuracy with {rfe.n_features_} features: {rfe_score:.4f}")
print(f"Accuracy difference: {rfe_score - baseline_score:.3f}")結果如下:
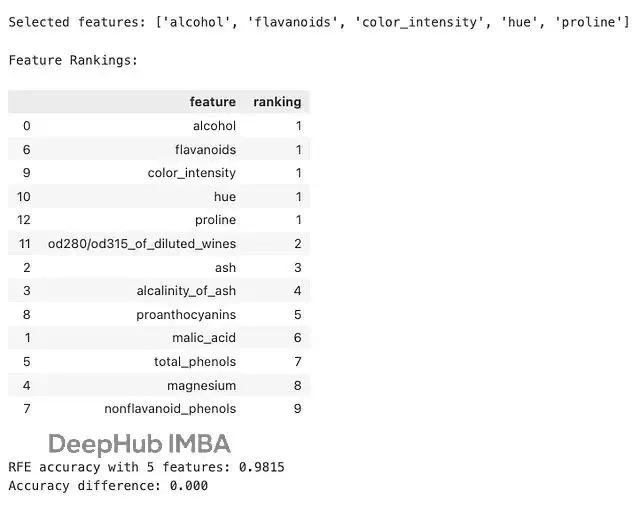
選出了 5 個特徵後準確率達到 0.9815,和用全部特徵幾乎沒差別。也就是説特徵數量直接砍掉了 60% 多,但模型性能基本沒損失。
不同模型的表現
RFE 可以配合各種模型使用。比如説隨機森林,看看選出來的特徵有什麼區別:
# RFE with Random Forest
rf_estimator = RandomForestClassifier(n_estimators=200, random_state=69)
rfe_rf = RFE(rf_estimator, n_features_to_select=5, step=1)
rfe_rf.fit(X_train_scaled, y_train)
# comparing Logistic Regression RFE and Random Forest RFE
lr_features = set(X.columns[rfe.support_])
rf_features = set(X.columns[rfe_rf.support_])
print("Features selected by Logistic Regression:")
print(lr_features)
print("\nFeatures selected by Random Forest:")
print(rf_features)
print("\nCommon features:")
print(lr_features.intersection(rf_features))
print("\nDifferent features:")
print(lr_features.symmetric_difference(rf_features))
兩個模型選出來的特徵有重疊也有差異。這很正常,因為不同模型看重的東西本來就不一樣。邏輯迴歸更關注線性關係,而隨機森林能捕捉更復雜的非線性模式。
特徵排名可視化
再看看兩個模型對特徵的評價:
# creating a dataframe for easy plotting
comparison_df = pd.DataFrame({
'Feature': X.columns,
'LR_Ranking': rfe.ranking_,
'RF_Ranking': rfe_rf.ranking_,
'Selected_by_LR': rfe.support_,
'Selected_by_RF': rfe_rf.support_
})
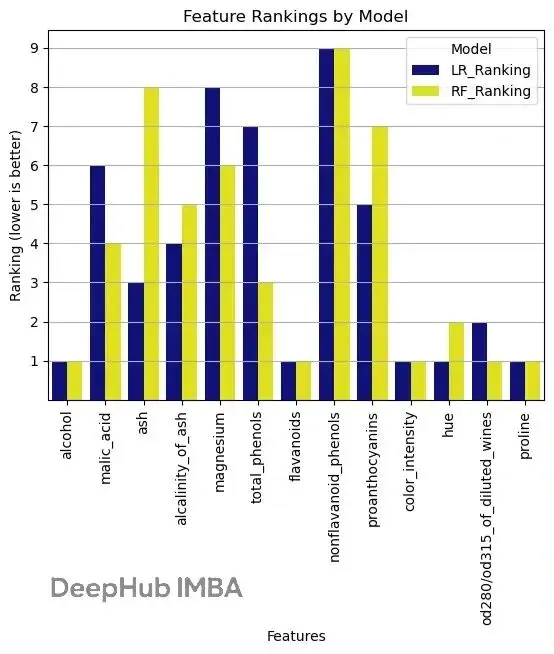
# plot 1: feature rankings comparison
comparison_melted=comparison_df.melt(id_vars='Feature', value_vars=['LR_Ranking', 'RF_Ranking'],
var_name='Model', value_name='Ranking')
sns.barplot(data=comparison_melted,x='Feature', y='Ranking', hue='Model', palette=['darkblue','yellow'])
plt.grid(True, axis='y')
plt.xticks(rotation=90)
plt.yticks(np.arange(1, comparison_melted['Ranking'].max()+1))
plt.xlabel('Features')
plt.ylabel('Ranking (lower is better)')
plt.title('Feature Rankings by Model')
plt.show()
# Plot 2: selected features visualization using heatmap
selected_data = comparison_df[['Feature', 'Selected_by_LR', 'Selected_by_RF']].set_index('Feature').T
sns.heatmap(selected_data, annot=False, cmap='RdYlGn', cbar=False)
plt.title('Selected Features Matrix', fontsize=12, fontweight='bold')
plt.xlabel('Features', fontsize=11)
plt.ylabel('Model', fontsize=11)
plt.show()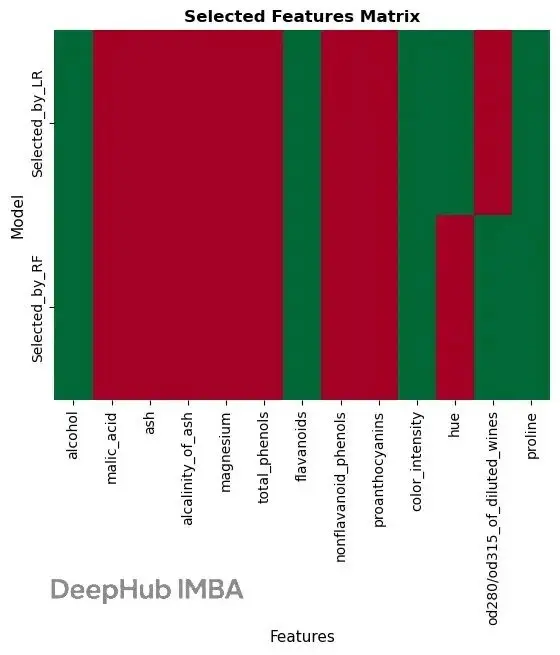
柱狀圖顯示了各個特徵在不同模型中的排名,熱力圖直觀地展示了哪些特徵被選中。可以看到 proline、flavanoids 等幾個特徵在兩個模型中都比較重要。
RFECV 自動找最優特徵數
前面都是手動指定要保留 5 個特徵。實際應用中很難事先知道該留多少個。所以RFECV 用交叉驗證自動確定最優數量:
# create and fit RFECV object
rfecv=RFECV(
estimator=LogisticRegression(max_iter=1000, random_state=42),
step=1,
cv=5, # 5-fold cross-validation
scoring='accuracy',
min_features_to_select=1
)
rfecv.fit(X_train_scaled, y_train)
print(f"Optimal number of features: {rfecv.n_features_} with a score of {rfecv.cv_results_['mean_test_score'].max():.4f}")
print('The selected features are:')
forcolinX.columns[rfecv.support_]:
print(f" -> {col}")
# plotting number of selected features vs. cross-validation scores
plt.figure(figsize=(8, 5))
y1=rfecv.cv_results_['mean_test_score']
x1=rfecv.cv_results_['n_features']
ax=sns.lineplot(x=x1, y=y1)
plt.xlabel("Number of Features Selected")
plt.ylabel("Mean CV Accuracy")
plt.title("RFECV: Number of Features vs. CV Accuracy")
ax.axhline(y=np.max(y1), color='r', linestyle=':', label='Max CV Accuracy')
plt.xticks(x1)
plt.yticks(np.arange(0.75,1.01,0.02))
plt.grid(True)
plt.legend()
plt.show()
# creating model with optimal features
X_train_rfecv=rfecv.transform(X_train_scaled)
X_test_rfecv=rfecv.transform(X_test_scaled)
rfecv_model=LogisticRegression(max_iter=1000, random_state=42)
rfecv_model.fit(X_train_rfecv, y_train)
rfecv_score=rfecv_model.score(X_test_rfecv, y_test)
print(f"\nModel accuracy with {rfecv.n_features_} features: {rfecv_score:.4f}")輸出:

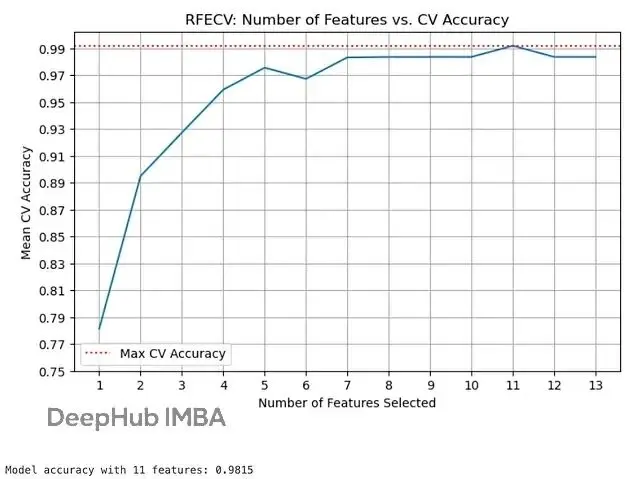
交叉驗證結果顯示 10 個特徵時準確率最高,達到 0.9839。曲線圖能清楚看到隨着特徵數量增加,準確率的變化趨勢。通過圖標可視化,比拍腦袋決定保留幾個特徵靠譜多了。
注意事項
特徵標準化很重要,尤其是用距離相關的算法時。選擇合適的基模型也關鍵,得確保它能給出有意義的特徵重要性分數。數據量大的時候 RFE 跑起來會比較慢,所以可以調大 step 參數一次刪多個特徵。
交叉驗證能避免特徵選擇過程中的過擬合,RFECV 的一個主要功能就是解決這個問題。最終模型的評估一定要在獨立的測試集上做。有時候領域知識比算法選擇更管用,別完全依賴自動化方法。
也可以試試不同的基模型也有價值,線性模型和樹模型關注的點不同,選出的特徵也會有差別。
總結
RFE 在特徵選擇這塊確實好用。需要降維但又不想損失太多性能的時候,或者想搞清楚哪些特徵最重要的時候,都可以考慮用它。
RFE 根據模型評分系統地刪除特徵;RFECV 能自動找到最優特徵數量;不同模型可能選出不同特徵;測試集驗證不能少。
下次碰到高維數據的時候可以試試 RFE,説不定會有驚喜。
https://avoid.overfit.cn/post/2ef37f6acc184f2dbf8ae46fba3377bf
作者:Prathik C




