









Kernel Memory (KM) 是一種多模態 AI 服務,專注於通過自定義的連續數據混合管道高效索引數據集。它支持檢索增強生成(RAG)、合成記憶、提示工程以及自定義語義記憶處理。KM 支持自然語言查詢,從已索引的數據中獲取答案,並提供完整的引用和原始來源鏈接。
通過 KM 我們可以讓 LLM 認識更多新的知識。比如認識新的文本內容,WORD文檔,PDF, PPT,甚至是直接爬取一個網頁然後進行 embedding,連爬蟲都幫你寫好了。


KM 看起來是專為 RAG 設計的一套框架。很多同學可能已經知道 SK 裏面有 Semantic Memory (SM),它可以用來做 RAG。咋一看很容易就把 KM 當作了 SM。但其實 KM 跟 SM 並不是一回事。雖然 KM 是從 SM 發展而來的。但現在 KM 已經可以脱離 SK 獨立運行。
KM 現在可以方便的集成進 .NET Backend/Console/Desktop 應用程序裏面,使這些程序立馬獲得本地識別文檔的能力。這種模式叫做Synchronous Memory API (aka “serverless”)。
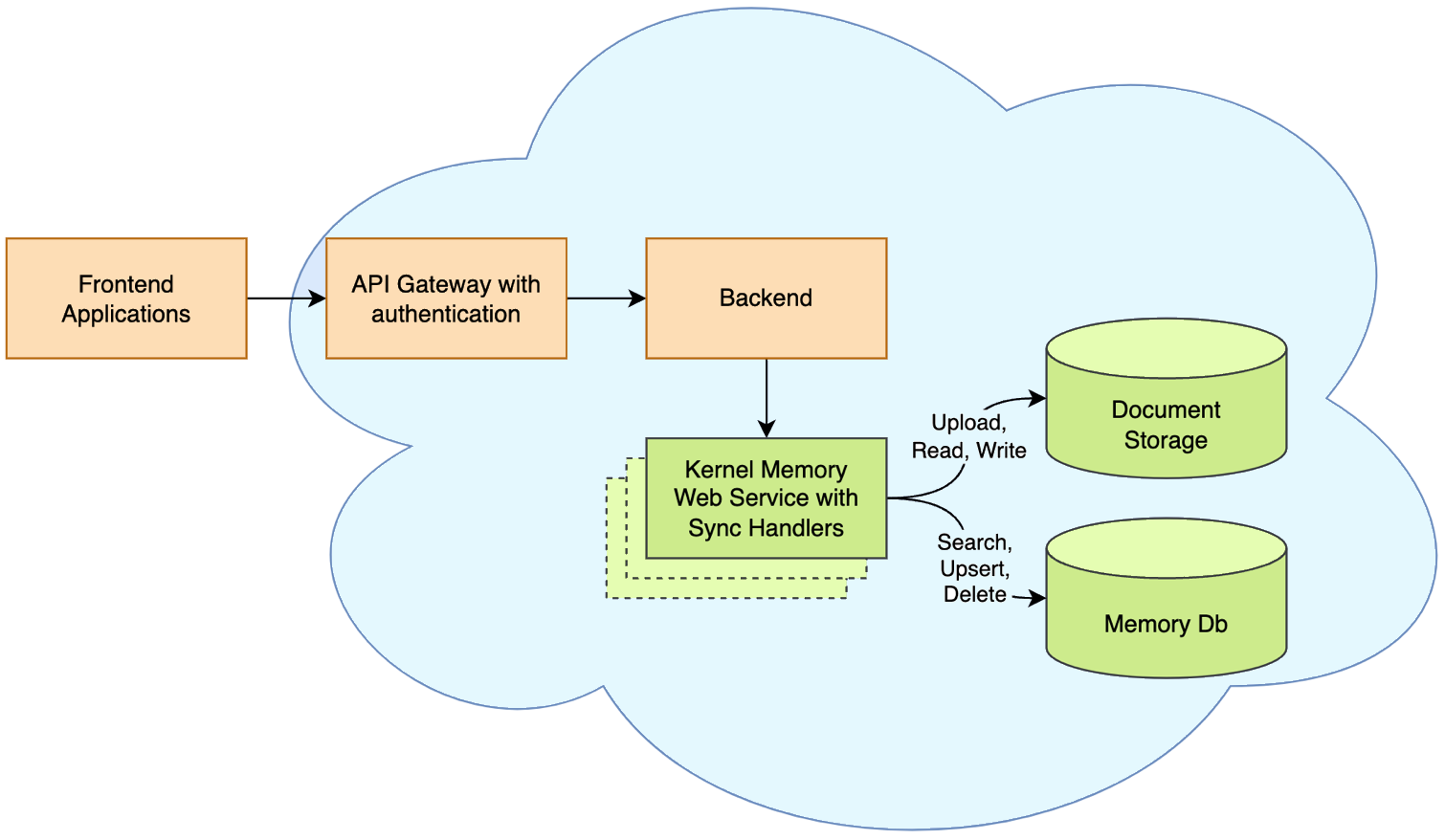
如果你的場景是想要搭建大規模的文檔識別跟問答平台那麼你可能需要把 KM 作為一個完整的服務,異步來處理這些文檔與問答請求。這種模式叫做Memory as a Service - Asynchronous API。
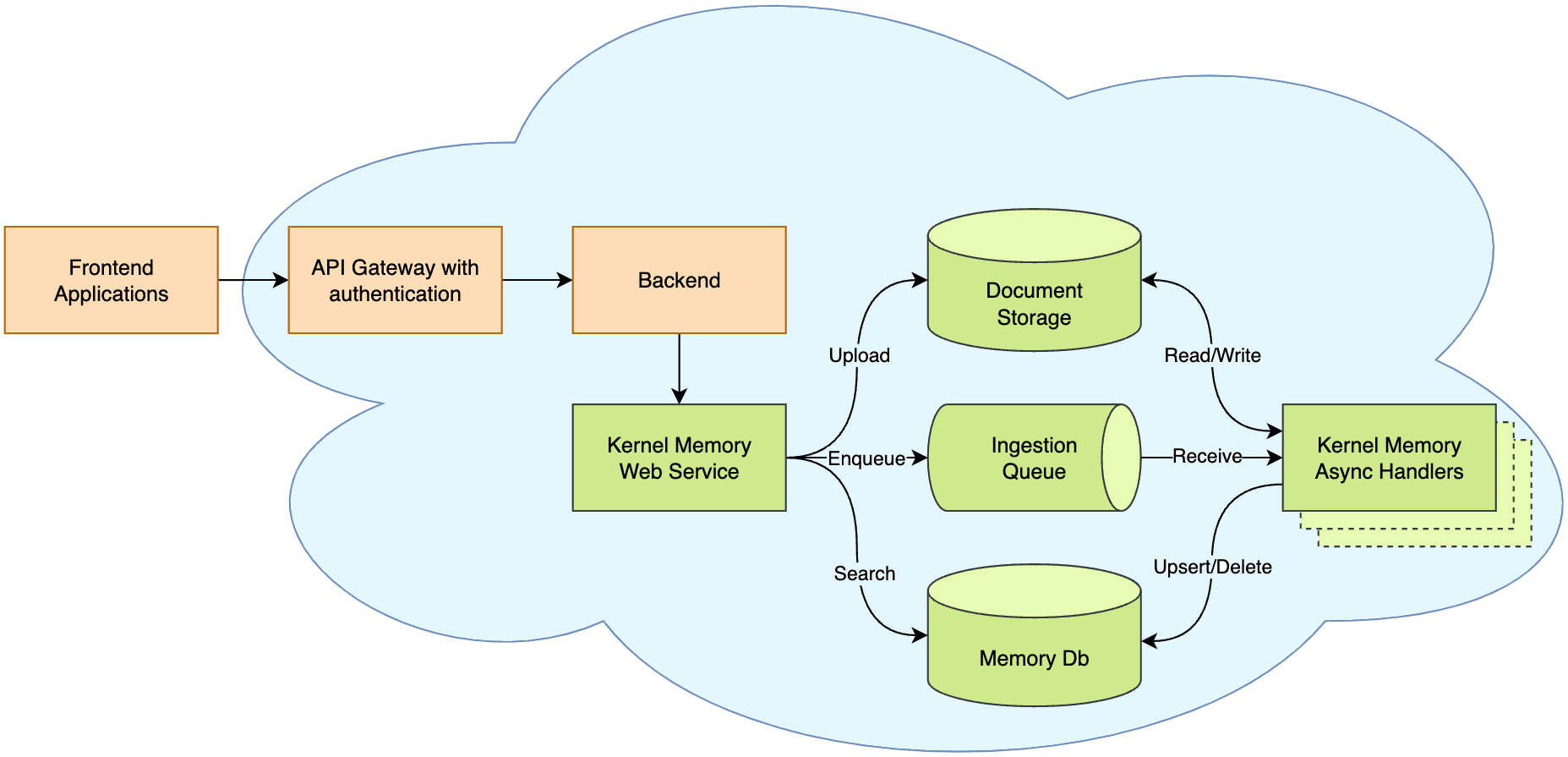
使用 KM 導入文本
使用 KM 還是需要搭配 LLM 的能力。這裏還是使用本地的 Ollama 來運行 llama3.1:8b 的模型。下面讓我們看看怎麼使 KM 認識以下這段我剛編的關於 QIQI 動物園的文字。
Qiqi Zoo features 10 monkeys, 8 tigers, 6 elephants, 4 horses, 100 ostriches, and 99 koalas.\n\n" +
"Ticket Prices:\n\n" +
"Adults: 100 RMB\n" +
"Children: 50 RMB\n" +
"Contact: 13813818188\n" +
"Address: 999 Xinghu Street, Suzhou Industrial Park, Jiangsu, China.
以下代碼我們指示了使用 ollama 來進行文本生成跟文本 embedding 生成。同時指定了使用一個簡易的內存數據庫來存儲跟檢索向量。然後把 Qiqi zoo 的文本內容導入進去,之後就可以問相關的問題了。
var modelName = "llama3.1:8b";
var ollamaEndpoint = "http://localhost:11434";
var ollamaApiClient = new OllamaApiClient(new Uri(ollamaEndpoint), modelName);
var ollamaModelConfig = new OllamaModelConfig() { ModelName = modelName };
var textEmbeddingGenerator = new OllamaTextEmbeddingGenerator(ollamaApiClient, ollamaModelConfig);
var memory = new KernelMemoryBuilder()
.WithOllamaTextGeneration(modelName, ollamaEndpoint)
.WithOllamaTextEmbeddingGeneration(modelName, ollamaEndpoint)
#pragma warning disable KMEXP03
.AddIngestionMemoryDb(new SimpleVectorDb(SimpleVectorDbConfig.Volatile, textEmbeddingGenerator))
#pragma warning restore KMEXP03
.Build<MemoryServerless>();
var text = "Qiqi Zoo features 10 monkeys, 8 tigers, 6 elephants, 4 horses, 100 ostriches, and 99 koalas.\n\n" +
"Ticket Prices:\n\n" +
"Adults: 100 RMB\n" +
"Children: 50 RMB\n" +
"Contact: 13813818188\n" +
"Address: 999 Xinghu Street, Suzhou Industrial Park, Jiangsu, China.";
await memory.ImportTextAsync(text, "doc01");
var query = Console.ReadLine();
while (!string.IsNullOrEmpty(query))
{
var answer = await memory.AskAsync(query);
Console.WriteLine(answer);
query = Console.ReadLine();
}
問幾個關於這段文字的問題,回答的非常精準。

導入文檔
我們還可以使用 KM 來直接識別 word,ppt,pdf 等文檔。你都不用自己預處理這些文檔,微軟簡直太貼心了。
await memory.ImportDocumentAsync(new Document("file001").AddFile("memory/QiqiZoo.docx"));
導入網頁
除了本地的文本,文檔這些內容,KM 還能直接從遠程網頁上獲取內容。簡直了,爬蟲都不用自己寫了。
await memory.ImportWebPageAsync("https://www.cnblogs.com/kklldog/p/18538651", "web001");
總結
KM 是微軟從 SK Semantic memory 的開發經歷與用户反饋總結孵化出來的一個框架。它提供了許多開箱即用的能力來讓開發者獲取 RAG 的能力。它支持導入多種多樣的文檔(docx,pdf,ppt,json,html...)。它可以直接集成進你的應用內,也可以作為後端服務提供更強大的處理與擴展能力。如果你想快速構建一個問答知識庫,不妨試試 Kernel Memory。
參考:https://microsoft.github.io/kernel-memory/




