

許多企業在享受數據紅利的同時,也飽受“數據沼澤”之苦——尤其是主數據(Master Data)的冗餘、不一致與重複問題,已成為制約業務效率與決策質量的關鍵瓶頸。
主數據,如客户、供應商、商品、組織架構等,是貫穿企業多個業務系統的核心實體。一旦這些基礎數據在不同系統中存在多個版本、命名不一或結構混亂,不僅會導致財務對賬困難、庫存管理失真,還可能引發客户體驗下降甚至合規風險。根據 Gartner 的一份報告,數據質量不佳導致企業每年平均損失1290 萬美元。
那麼,如何有效治理主數據,消除冗餘與重複?本文將從實踐角度出發,系統闡述解決主數據問題的三大核心方法,並探討如何藉助高效解決方案,構建可持續的主數據治理體系。
方法一:建立統一的主數據標準與模型
主數據混亂的根源,往往在於缺乏統一的定義與結構標準。例如,同一客户在CRM系統中名為“ABC科技有限公司”,在ERP中卻記為“ABC Tech Co., Ltd.”,在財務系統中又簡化為“ABC公司”——這種“同物異名”現象直接導致數據無法關聯、分析失真。
解決之道在於“先立規矩,再行治理”:
- 定義主數據實體範圍:明確哪些數據屬於主數據(如客户、物料、員工等),並劃定其生命週期邊界。
- 制定編碼規則與命名規範:例如客户編碼採用“地區+行業+序列號”格式,物料名稱遵循“品類-規格-品牌”結構。
- 構建邏輯數據模型(LDM):統一字段含義、數據類型、必填項及關聯關係,確保跨系統語義一致。
這一過程並非一次性工程,而需通過制度化流程持續維護。關鍵在於,標準一旦確立,就必須在所有新建或改造的系統中強制執行,否則將重蹈覆轍。
案例:某製造企業在實施SAP升級時,同步制定了《主數據管理規範》,要求所有外圍系統(包括MES、WMS、電商平台)必須按統一模型提交客户與物料信息,從源頭杜絕了數據變異。
方法二:實施主數據清洗與去重(Deduplication)
即便有了標準,歷史遺留數據中的重複與錯誤仍不可避免。此時,需要通過技術手段對存量數據進行清洗與合併。
典型的主數據重複場景包括:
- 同一客户因不同渠道錄入產生多條記錄;
- 商品因SKU變更或拼寫錯誤被重複創建;
- 組織架構調整後舊部門未及時歸檔。
有效的清洗流程通常包含以下步驟:
- 數據探查:識別字段缺失率、格式異常、值分佈等質量問題;
- 匹配規則配置:基於關鍵字段(如統一社會信用代碼、手機號、郵箱)設定相似度閾值;
- 自動/半自動合併:對高置信度重複項自動合併,低置信度交由人工審核;
- 黃金記錄(Golden Record)生成:從多個來源中提取最完整、最新的信息,形成唯一權威版本。
值得注意的是,清洗不是“一次性手術”,而應嵌入日常數據流轉中。例如,每當新客户註冊時,系統應實時比對現有庫,防止新增重複。
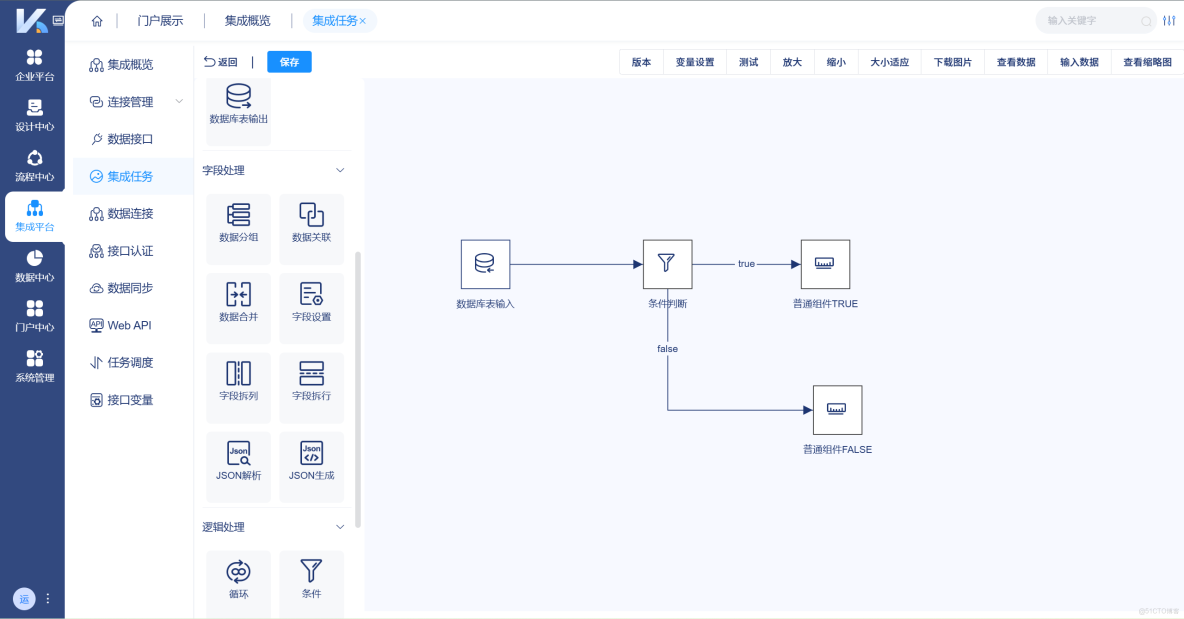
靈活的拖放操作界面,使得企業能夠輕鬆在編輯器中構建集成任務,配置各種節點間的交互,如數據分組、數據合併、數據關聯等。
方法三:構建跨系統的主數據分發與同步機制
主數據治理的終極目標,不是集中在一個“孤島”中,而是在正確的時間,將正確的主數據分發到所有需要它的系統中。這就要求建立一套可靠的數據同步機制。
傳統做法常依賴點對點接口(如A系統直連B系統),但隨着系統數量增加,接口呈指數級增長(N個系統需N×(N-1)/2個接口),維護成本極高,且難以保證一致性。
更優的策略是採用中心輻射式(Hub-and-Spoke)架構:
- 設立一個邏輯或物理的主數據管理中心(MDM Hub);
- 所有系統向Hub註冊主數據變更;
- Hub負責清洗、標準化後,按需分發至各訂閲系統。
該架構的優勢在於:
- 解耦系統間依賴;
- 變更只需對接Hub,無需修改多個接口;
- 支持事件驅動(如客户信息更新即觸發同步),保障數據實時性。
然而,自建MDM平台開發週期長、成本高,對中小企業並不友好。此時,輕量級、可配置的集成平台便成為理想選擇。
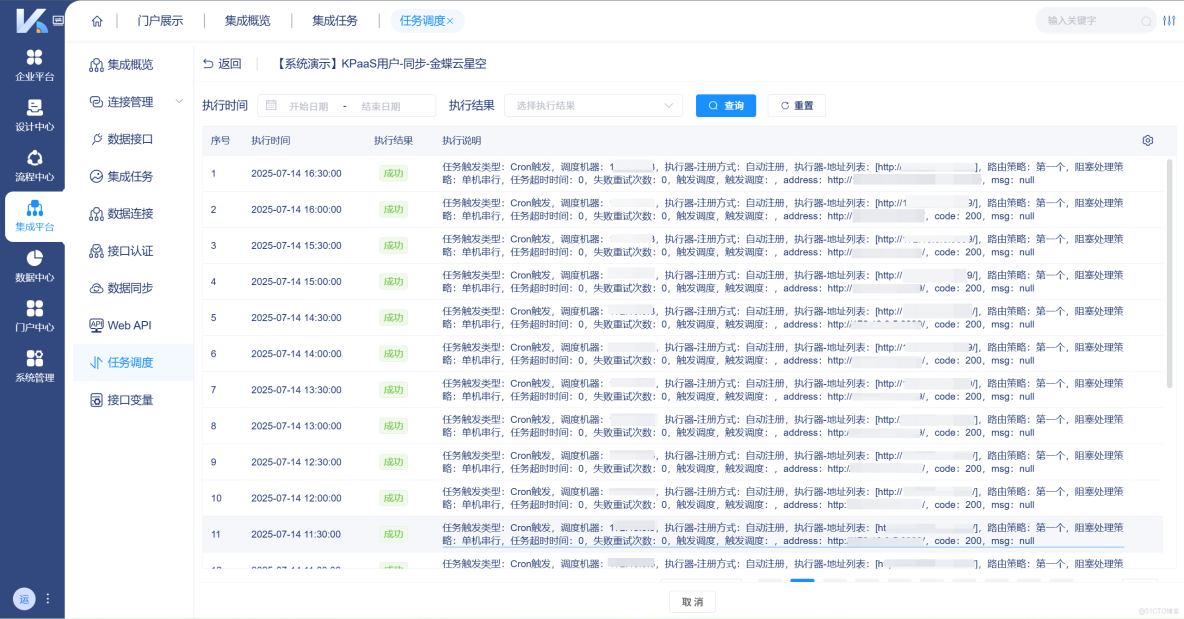
數據集成平台記錄數據操作的日誌信息,提供了完整的數據操作審計軌跡
實踐示例:讓主數據治理更輕盈高效
面對上述三大方法的落地挑戰,越來越多企業開始尋求低代碼、高靈活性的集成解決方案。以下展示具備擴展性能的數據集成方案,在主數據治理場景中展現出獨特價值:
1. 主數據模型管理
KPaaS支持定義主數據實體結構、字段約束與校驗規則。企業可快速搭建符合自身業務的客户、物料等主數據模型,並與現有標準對齊。
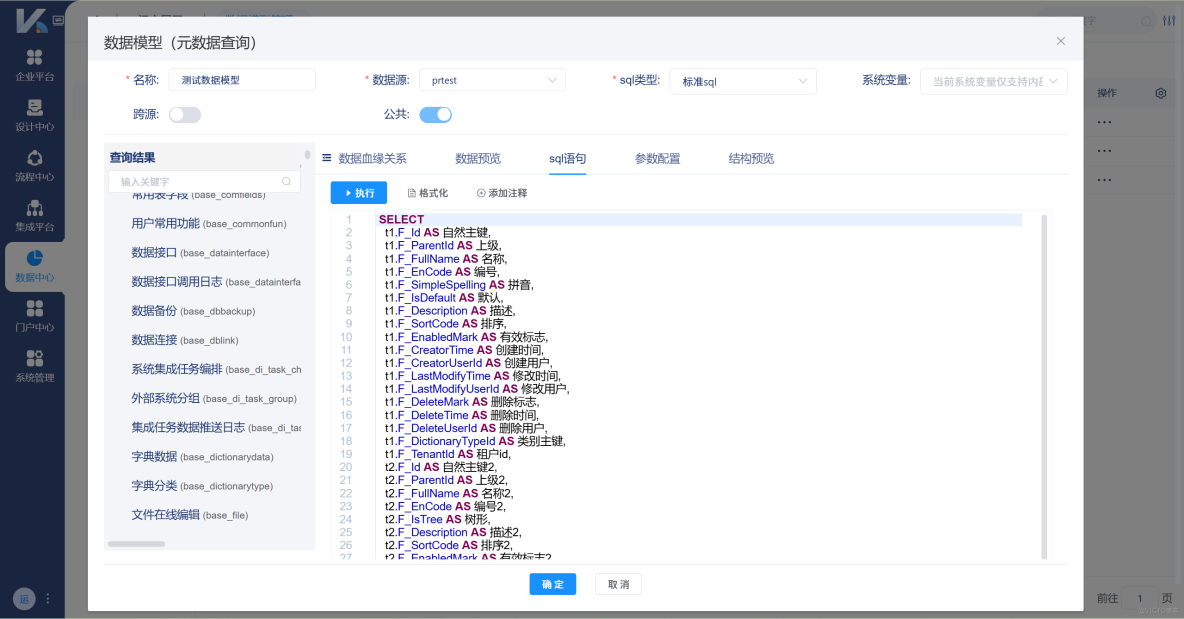
支持數據庫、API、文件等跨源數據集模型配置,並直觀展示數據血緣關係。
2. 內置清洗與去重能力
平台提供“數據合併”“字段標準化”“模糊匹配”等組件,用户可通過拖拽方式配置清洗邏輯。例如,將“北京市”“北京”“BJ”統一歸一為“北京市”;基於手機號+姓名組合識別潛在重複客户。
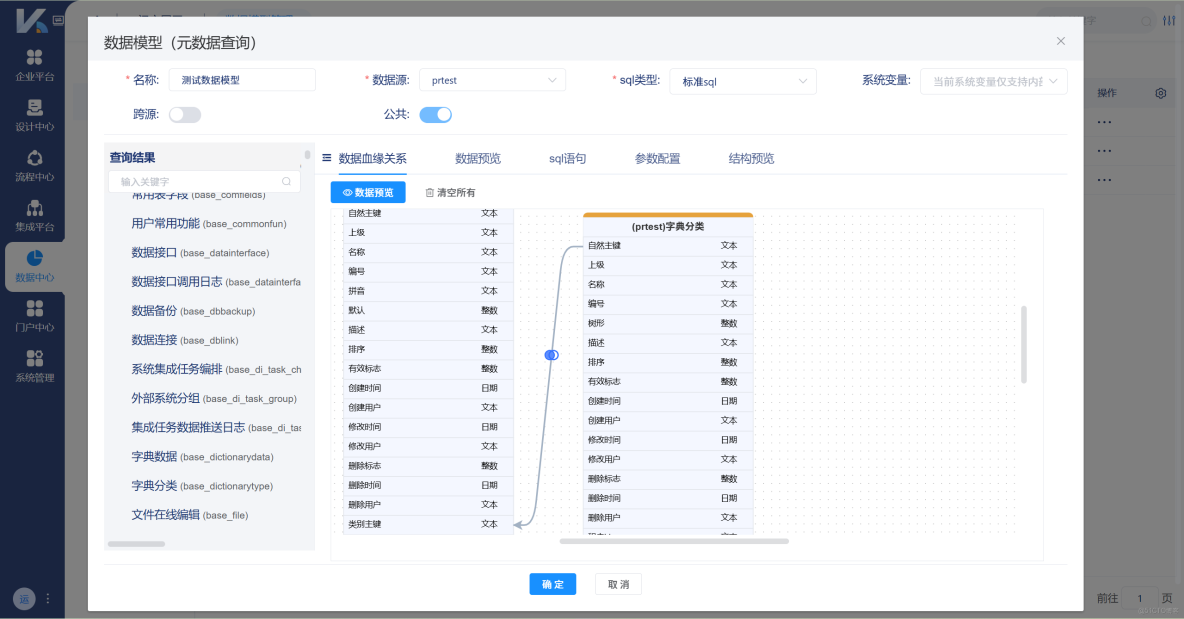
3. 靈活的同步調度機制
KPaaS 支持兩種主數據分發模式:
定時任務:每日凌晨批量同步最新主數據至各業務系統;
事件觸發:當CRM中客户信息更新時,立即通過API推送至ERP、BI等下游系統。
其預置的金蝶AI星空、用友U8、Salesforce等連接器,大幅降低對接複雜度。開發者更多的是關注業務邏輯,弱化處理認證、重試、日誌等底層細節。
無縫對接SAP、用友、金蝶、釘釘等眾多知名廠商及應用,為企業提供高效運營支持。
4. 端到端可追溯
所有主數據變更、清洗操作、同步結果均記錄審計日誌,支持按時間、實體、系統維度查詢,滿足內控與合規要求。
主數據治理是一場持久戰,而非閃電戰
解決主數據冗餘與重複,不能寄希望於一次性的數據清洗項目。它需要標準先行、技術支撐、流程保障三位一體的長效機制。而在這個過程中,選擇合適的工具平台,往往決定了治理的效率與可持續性。
具備擴展性能的數據集成解決方案,為那些尚未具備大規模MDM投入能力的企業,提供了一條“輕量起步、漸進演進”的可行路徑。通過其靈活的數據建模、智能清洗與自動化分發能力,企業可以在不中斷現有業務的前提下,逐步構建乾淨、一致、可信的主數據底座。
當主數據不再成為“負擔”,而成為驅動精準營銷、智能供應鏈與實時決策的燃料,企業的數字化轉型才算真正步入深水區



