









多線程編程是現代軟件開發中的一項關鍵技術,在多線程編程中,開發者可以將複雜的任務分解為多個獨立的線程,使其並行執行,從而充分利用多核處理器的優勢。然而,多線程編程也帶來了挑戰,例如線程同步、死鎖和競態條件等問題。本篇文章將深入探討多線程編程的基本概念(原子操作、CAS、Lock-free、內存屏障、偽共享、亂序執行等)、常見模式和最佳實踐。通過具體的代碼示例,希望能夠幫助大家掌握多線程編程的核心技術,並在實際開發中應用這些知識,提升軟件的性能和穩定性。
1 多線程
1.1 線程的概念
十多年前,主流觀點主張在可能的情況下優先選擇多進程而非多線程。如今,多線程編程已經成為編程領域的事實標準。多線程技術在很大程度上改善了程序的性能和響應能力,使其能夠更加高效地利用系統資源,這不僅歸功於多核處理器的普及和軟硬件技術的進步,還歸功於開發者對多線程編程的深入理解和技術創新。
那麼什麼是線程呢?線程是一個執行上下文,它包含諸多狀態數據:每個線程有自己的執行流、調用棧、錯誤碼、信號掩碼、私有數據。Linux內核用任務(Task)表示一個執行流。
1.1.1 執行流
一個任務裏被依次執行的指令會形成一個指令序列(IP寄存器值的歷史記錄),這個指令序列就是一個指令流,每個線程會有自己的執行流。考慮下面的代碼(本文代碼塊為C++):
int calc(int a, int b, char op) {
int c = 0;
if (op == '+')
c = a + b;
else if (op == '-')
c = a - b;
else if (op == '*')
c = a * b;
else if (op == '/')
c = a / b;
else
printf("invalid operation\n");
return c;
}calc函數被編譯成彙編指令,一行C代碼對應一個或多個彙編指令,在一個線程裏執行calc,那麼這些機器指令會被依次執行。但是,被執行的指令序列跟代碼順序可能不完全一致,代碼中的分支、跳轉等語句,以及編譯器對指令重排、處理器亂序執行會影響指令的真正執行順序。
1.1.2 邏輯線程 vs 硬件線程
線程可以進一步區分為邏輯線程和硬件線程。
邏輯線程
程序上的線程是一個邏輯上的概念,也叫任務、軟線程、邏輯線程。線程的執行邏輯由代碼描述,比如編寫一個函數實現對一個整型數組的元素求和:
int sum(int a[], int n) {
int x = 0;
for (int i = 0; i < n; ++i)
x += a[i];
return x;
}這個函數的邏輯很簡單,它沒有再調用其他函數(更復雜的功能邏輯可以在函數裏調用其他函數)。我們可以在一個線程裏調用這個函數對某數組求和;也可以把sum設置為某線程的入口函數,每個線程都會有一個入口函數,線程從入口函數開始執行。sum函數描述了邏輯,即要做什麼以及怎麼做,偏設計;但它沒有描述物質,即沒有描述這個事情由誰做,事情最終需要派發到實體去完成。
硬件線程
與邏輯線程對應的是硬件線程,這是邏輯線程被執行的物質基礎。
芯片設計領域,一個硬件線程通常指為執行指令序列而配套的硬件單元,一個CPU可能有多個核心,然後核心還可能支持超線程,1個核心的2個超線程複用一些硬件。從軟件的視角來看,無須區分是真正的Core和超出來的VCore,基本上可以認為是2個獨立的執行單元,每個執行單元是一個邏輯CPU,從軟件的視角看CPU只需關注邏輯CPU。一個軟件線程由哪個CPU/核心去執行,以及何時執行,不歸應用程序員管,它由操作系統決定,操作系統中的調度系統負責此項工作。
1.2 線程、核心、函數的關係
線程入口函數是線程執行的起點,線程從入口函數開始、一個指令接着一個指令執行,中間它可能會調用其他函數,那麼它的控制流就轉到了被調用的函數繼續執行,被調用函數裏還可以繼續調用其他函數,這樣便形成一個函數調用鏈。
前面的數組求和例子,如果數組特別大,則哪怕是一個簡單的循環累加也可能耗費很長的時間,可以把這個整型數組分成多個小數組,或者表示成二維數組(數組的數組),每個線程負責一個小數組的求和,多個線程併發執行,最後再累加結果。
所以,為了提升處理速度,可以讓多個線程在不同數據區段上執行相同(或相似)的計算邏輯,同樣的處理邏輯可以有多個執行實例(線程),這對應對數據拆分線程。當然,也可以為兩個線程指定不同的入口函數,讓各線程執行不同的計算邏輯,這對應對邏輯拆分線程。
我們用一個例子來闡述線程、核心和函數之間的關係,假設有遛狗、掃地兩類工作要做:
- 遛狗就是為狗繫上繩子然後牽着它在小區裏溜達一圈,這句話就描述了遛狗的邏輯,即對應到函數定義,它是一個對應到設計的靜態的概念。
- 每項工作,最終需要人去做,人就對應到硬件:CPU/Core/VCore,是任務被完成的物質基礎。
那什麼對應軟件線程? 任務拆分。
一個例子
假設現在有2條狗需要遛、3個房間需要打掃。可以把遛狗拆成2個任務,一個任務是遛小狗,另一個任務是遛大狗;打掃房間拆分為3個任務,3個房間對應3個任務,執行這樣的拆分策略後,將會產生2+3=5個任務。但如果只有2個人,2個人無法同時做5件事,讓某人在某時幹某事由調度系統負責。
如果張三在遛小狗,那就對應一個線程被執行,李四在掃房間A,則表示另一個線程在執行中,可見線程是一個動態的概念。
軟件線程不會一直處於執行中,原因是多方面的。上述例子是因為人手不夠,所以遛大狗的任務還處於等待被執行的狀態,其他的原因包括中斷、搶佔、條件依賴等。比如李四掃地過程中接到一個電話,他需要去處理更緊急的事情(接電話),則掃地這個事情被掛起,李四打完電話後繼續掃地,則這個線程會被繼續執行。
如果只有1個人,則上述5個任務依然可以被依次或交錯完成,所以多線程是一個編程模型,多線程並不一定需要多CPU多Core,單CPU單Core系統依然可以運行多線程程序(雖然最大化利用多CPU多Core的處理能力是多線程程序設計的一個重要目標)。1個人無法同時做多件事,單CPU/單Core也不可以,操作系統通過時間分片技術應對遠多於CPU/Core數的多任務執行的挑戰。也可以把有些任務只分配給某些人去完成,這對應到CPU親和性和綁核。
1.3 程序、進程、線程、協程
進程和線程是操作系統領域的兩個重要概念,兩者既有區別又有聯繫。
1.3.1 可執行程序
C/C++源文件經過編譯器(編譯+鏈接)處理後,會產生可執行程序文件,不同系統有不同格式,比如Linux系統的ELF格式、Windows系統的EXE格式,可執行程序文件是一個靜態的概念。
1.3.2 進程是什麼
可執行程序在操作系統上的一次執行對應一個進程,進程是一個動態的概念:進程是執行中的程序。同一份可執行文件執行多次,會產生多個進程,這跟一個類可以創建多個實例一樣。進程是資源分配的基本單位。
1.3.3 線程是什麼
一個進程內的多個線程代表着多個執行流,這些線程以併發模式獨立執行。操作系統中,被調度執行的最小單位是線程而非進程。進程是通過共享存儲空間對用户呈現的邏輯概念,同一進程內的多個線程共享地址空間和文件描述符,共享地址空間意味着進程的代碼(函數)區域、全局變量、堆、棧都被進程內的多線程共享。
1.3.4 進程和線程的關係
先看看linus的論述,在1996年的一封郵件裏,Linus詳細闡述了他對進程和線程關係的深刻洞見,他在郵件裏寫道:
- 把進程和線程區分為不同的實體是揹着歷史包袱的傳統做法,沒有必要做這樣的區分,甚至這樣的思考方式是一個主要錯誤。
-
進程和線程都是一回事:一個執行上下文(context of execution),簡稱為COE,其狀態包括:
- CPU狀態(寄存器等)
- MMU狀態(頁映射)
- 權限狀態(uid、gid等)
- 各種通信狀態(打開的文件、信號處理器等)
- 傳統觀念認為:進程和線程的主要區別是線程有CPU狀態(可能還包括其他最小必要狀態),而其他上下文來自進程;然而,這種區分法並不正確,這是一種愚蠢的自我設限。
- Linux內核認為根本沒有所謂的進程和線程的概念,只有COE(Linux稱之為任務),不同的COE可以相互共享一些狀態,通過此類共享向上構建起進程和線程的概念。
- 從實現來看,Linux下的線程目前是LWP實現,線程就是輕量級進程,所有的線程都當作進程來實現,因此線程和進程都是用task_struct來描述的。這一點通過/proc文件系統也能看出端倪,線程和進程擁有比較平等的地位。對於多線程來説,原本的進程稱為主線程,它們在一起組成一個線程組。
- 簡言之,內核不要基於進程/線程的概念做設計,而應該圍繞COE的思考方式去做設計,然後,通過暴露有限的接口給用户去滿足pthreads庫的要求。
1.3.5 協程
用户態的多執行流,上下文切換成本比線程更低,微信用協程改造後台系統後,獲得了更大吞吐能力和更高穩定性。如今,協程庫也進了C++ 20新標準。
1.4 為什麼需要多線程
1.4.1 什麼是多線程
一個進程內多個線程併發執行的情況就叫多線程,每個線程是一個獨立的執行流,多線程是一種編程模型,它與處理器無關、跟設計有關。
需要多線程的原因包括:
- 並行計算:充分利用多核,提升整體吞吐,加快執行速度。
- 後台任務處理:將後台線程和主線程分離,在特定場景它是不可或缺的,如:響應式用户界面、實時系統等。
我們用2個例子作説明。
1.4.2 通過多線程併發提升處理能力
假設你要編寫一個程序,用於統計一批文本文件的單詞出現次數,程序的輸入是文件名列表,輸出一個單詞到次數的映射。
// 類型別名:單詞到次數的映射
using word2count = std::map<std::string, unsigned int>;
// 合併“單詞到次數映射列表”
word2count merge(const std::vector<word2count>& w2c_list) {/*todo*/}
// 統計一個文件裏單詞出現次數(單詞到次數的映射)
word2count word_count_a_file(const std::string& file) {/*todo*/}
// 統計一批文本文件的單詞出現次數
word2count word_count_files(const std::vector<std::string>& files) {
std::vector<word2count> w2c_list;
for (auto &file : files) {
w2c_list.push_back(word_count_a_file(file));
}
return merge(w2c_list);
}
int main(int argc, char* argv[]) {
std::vector<std::string> files;
for (int i = 1; i < argc; ++i) {
files.push_back(argv[i]);
}
auto w2c = word_count_files(files);
return 0;
}這是一個單線程程序,word_count_files函數在主線程裏被main函數調用。如果文件不多、又或者文件不大,那麼運行這個程序,很快就會得到統計結果,否則,可能要等一段長的時間才能返回結果。
重新審視這個程序會發現:函數word_count_a_file接受一個文件名,吐出從該文件計算出的局部結果,它不依賴於其他外部數據和邏輯,可以併發執行,所以,可以為每個文件啓動一個單獨的線程去運行word_count_a_file,等到所有線程都執行完,再合併得到最終結果。
實際上,為每個文件啓動一個線程未必合適,因為如果有數萬個小文件,那麼啓動數萬個線程,每個線程運行很短暫的時間,大量時間將耗費在線程創建和銷燬上,一個改進的設計:
- 開啓一個線程池,線程數等於Core數或二倍Core數(策略)。
-
每個工作線程嘗試去文件列表(文件列表需要用鎖保護起來)裏取一個文件。
- 成功,統計這個文件的單詞出現次數。
- 失敗,該工作線程就退出。
- 待所有工作線程退出後,在主線程裏合併結果。
這樣的多線程程序能加快處理速度,前面數組求和可以採用相似的處理,如果程序運行在多CPU多Core的機器上,就能充分利用多CPU多Core硬件優勢,多線程加速執行是多線程的一個顯而易見的主要目的,此其一。
1.4.3 通過多線程改變程序編寫方式
其二,有些場景會有阻塞的調用,如果不用多線程,那麼代碼不好編寫。
比如某程序在執行密集計算的同時,需要監控標準輸入(鍵盤),如果鍵盤有輸入,那麼讀取輸入並解析執行,但如果獲取鍵盤輸入的調用是阻塞的,而此時鍵盤沒有輸入到來,那麼其他邏輯將得不到機會執行。
代碼看起來會像下面這樣子:
// 從鍵盤接收輸入,經解釋後,會構建一個Command對象返回
Command command = getCommandFromStdInput();
// 執行命令
command.run();針對這種情況,我們通常會開啓一個單獨的線程去接收輸入,而用另外的線程去處理其他計算邏輯,避免處理輸入阻塞其他邏輯處理,這也是多線程的典型應用,它改變了程序的編寫方式,此其二。
1.5 線程相關概念
1.5.1 時間分片
CPU先執行線程A一段時間,然後再執行線程B一段時間,然後再執行線程A一段時間,CPU時間被切分成短的時間片、分給不同線程執行的策略就是CPU時間分片。時間分片是對調度策略的一個極度簡化,實際上操作系統的調度策略非常精細,要比簡單的時間分片複雜的多。如果一秒鐘被分成大量的非常短的時間片,比如100個10毫秒的時間片,10毫秒對人的感官而言太短了,以致於用户覺察不到延遲,彷彿計算機被該用户的任務所獨佔(實際上並不是),操作系統通過進程的抽象獲得了這種任務獨佔CPU的效果(另一個抽象是進程通過虛擬內存獨佔存儲)。
1.5.2 上下文切換
把當前正在CPU上運行的任務遷走,並挑選一個新任務到CPU上執行的過程叫調度,任務調度的過程會發生上下文切換(context swap),即保存當前CPU上正在運行的線程狀態,並恢復將要被執行的線程的狀態,這項工作由操作系統完成,需要佔用CPU時間(sys time)。
1.5.3 線程安全函數與可重入
一個進程可以有多個線程在同時運行,這些線程可能同時執行一個函數,如果多線程併發執行的結果和單線程依次執行的結果是一樣的,那麼就是線程安全的,反之就不是線程安全的。
不訪問共享數據,共享數據包括全局變量、static local變量、類成員變量,只操作參數、無副作用的函數是線程安全函數,線程安全函數可多線程重入。每個線程有獨立的棧,而函數參數保存在寄存器或棧上,局部變量在棧上,所以只操作參數和局部變量的函數被多線程併發調用不存在數據競爭。
C標準庫有很多編程接口都是非線程安全的,比如時間操作/轉換相關的接口:ctime()/gmtime()/localtime(),c標準通過提供帶_r後綴的線程安全版本,比如:
char* ctime_r(const time* clock, char* buf);這些接口的線程安全版本,一般都需要傳遞一個額外的char * buf參數,這樣的話,函數會操作這塊buf,而不是基於static共享數據,從而做到符合線程安全的要求。
1.5.4 線程私有數據
因為全局變量(包括模塊內的static變量)是進程內的所有線程共享的,但有時應用程序設計中需要提供線程私有的全局變量,這個變量僅在函數被執行的線程中有效,但卻可以跨多個函數被訪問。
比如在程序裏可能需要每個線程維護一個鏈表,而會使用相同的函數來操作這個鏈表,最簡單的方法就是使用同名而不同變量地址的線程相關數據結構。這樣的數據結構可以由Posix線程庫維護,成為線程私有數據 (Thread-specific Data,或稱為 TSD)。
Posix有線程私有數據相關接口,而C/C++等語言提供thread_local關鍵字,在語言層面直接提供支持。
1.5.5 阻塞和非阻塞
一個線程對應一個執行流,正常情況下,指令序列會被依次執行,計算邏輯會往前推進。但如果因為某種原因,一個線程的執行邏輯不能繼續往前走,那麼我們就説線程被阻塞住了。就像下班回家,但走到家門口發現沒帶鑰匙,只能在門口徘徊,任由時間流逝,而不能進入房間。
線程阻塞的原因有很多種,比如:
- 線程因為acquire某個鎖而被操作系統掛起,如果acquire睡眠鎖失敗,線程會讓出CPU,操作系統會調度另一個可運行線程到該CPU上執行,被調度走的線程會被加入等待隊列,進入睡眠狀態。
- 線程調用了某個阻塞系統調用而等待,比如從沒有數據到來的套接字上讀數據,從空的消息隊列裏讀消息。
- 線程在循環裏緊湊的執行測試&設置指令並一直沒有成功,雖然線程還在CPU上執行,但它只是忙等(相當於白白浪費CPU),後面的指令沒法執行,邏輯同樣無法推進。
如果某個系統調用或者編程接口有可能導致線程阻塞,那麼便被稱之為阻塞系統調用;與之對應的是非阻塞調用,調用非阻塞的函數不會陷入阻塞,如果請求的資源不能得到滿足,它會立即返回並通過返回值或錯誤碼報告原因,調用的地方可以選擇重試或者返回。
2 多線程同步
前面講了多線程相關的基礎知識,現在進入第二個話題,多線程同步。
2.1 什麼是多線程同步
同一進程內的多個線程會共享數據,對共享數據的併發訪問會出現Race Condition,這個詞的官方翻譯是競爭條件,但condition翻譯成條件令人困惑,特別是對初學者而言,它不夠清晰明瞭,翻譯軟件顯示condition有狀況、狀態的含義,可能翻譯成競爭狀況更直白。
多線程同步是指:
- 協調多個線程對共享數據的訪問,避免出現數據不一致的情況。
- 協調各個事件的發生順序,使多線程在某個點交匯並按預期步驟往前推進,比如某線程需要等另一個線程完成某項工作才能開展該線程的下一步工作。
要掌握多線程同步,需先理解為什麼需要多線程同步、哪些情況需要同步。
2.2 為什麼需要同步
理解為什麼要同步(Why)是多線程編程的關鍵,它甚至比掌握多線程同步機制(How)本身更加重要。識別什麼地方需要同步是編寫多線程程序的難點,只有準確識別需要保護的數據、需要同步的點,再配合系統或語言提供的合適的同步機制,才能編寫安全高效的多線程程序。
下面通過幾個例子解釋為什麼需要同步。
示例1
有1個長度為256的字符數組msg用於保存消息,函數read_msg()和write_msg()分別用於msg的讀和寫:
// example 1
char msg[256] = "this is old msg";
char* read_msg() {
return msg;
}
void write_msg(char new_msg[], size_t len) {
memcpy(msg, new_msg, std::min(len, sizeof(msg)));
}
void thread1() {
char new_msg[256] = "this is new msg, it's too looooooong";
write_msg(new_msg, sizeof(new_msg));
}
void thread2() {
printf("msg=%s\n", read_msg());
}如果線程1調用write_msg(),線程2調用read_msg(),併發操作,不加保護。因為msg的長度是256字節,完成長達256字節的寫入需要多個內存週期,在線程1寫入新消息期間,線程2可能讀到不一致的數據。即可能讀到 "this is new msg",而後半段內容 "it's very..." 線程1還沒來得及寫入,它不是完整的新消息。
在這個例子中,不一致表現為數據不完整。
示例2
比如對於二叉搜索樹(BST)的節點,一個結構體有3個成分:
- 一個指向父節點的指針
- 一個指向左子樹的指針
- 一個指向右子樹的指針
// example 2
struct Node {
struct Node *parent;
struct Node *left_child, *right_child;
};這3個成分是有關聯的,將節點加入BST,要設置這3個指針域,從BST刪除該節點,要修改該節點的父、左孩子節點、右孩子節點的指針域。對多個指針域的修改,不能在一個指令週期完成,如果完成了一個成分的寫入,還沒來得修改其他成分,就有可能被其他線程讀到了,但此時節點的有些指針域還沒有設置好,通過指針域去取數可能會出錯。
示例3
考慮兩個線程對同一個整型變量做自增,變量的初始值是0,我們預期2個線程完成自增後變量的值為2。
// example 3
int x = 0; // 初始值為0
void thread1() { ++x; }
void thread2() { ++x; }簡單的自增操作,包括三步:
- 加載:從內存中讀取變量x的值存放到寄存器
- 更新:在寄存器裏完成自增
- 保存:把位於寄存器中的x的新值寫入內存
兩個線程併發執行++x,讓我們看看真實情況是什麼樣的:
- 如果2個線程,先後執行自增,在時間上完成錯開。無論是1先2後,或是2先1後,那麼x的最終值是2,符合預期。但多線程併發並不能確保對一個變量的訪問在時間上完全錯開。
- 如果時間上沒有完全錯開,假設線程1在core1上執行,線程2在core2上執行,那麼,一個可能的執行過程如下:
- 首先,線程1把x讀到core1的寄存器,線程2也把x的值加載到core2的寄存器,此時,存放在兩個core的寄存器中x的副本都是0。
- 然後,線程1完成自增,更新寄存器裏x的值的副本(0變1),線程2也完成自增,更新寄存器裏x的值的副本(0變1)。
- 再然後,線程1將更新後的新值1寫入變量x的內存位置。
- 最後,線程2將更新後的新值1寫入同一內存位置,變量x的最終值是1,不符合預期。
線程1和線程2在同一個core上交錯執行,也有可能出現同樣的問題,這個問題跟硬件結構無關。之所以會出現不符合預期的情況,主要是因為“加載+更新+保存”這3個步驟不能在一個內存週期內完成。多個線程對同一變量併發讀寫,不加同步的話會出現數據不一致。
在這個例子中,不一致表現為x的終值既可能為1也可能為2。
示例4
用C++類模板實現一個隊列:
// example 4
template <typename T>
class Queue {
static const unsigned int CAPACITY = 100;
T elements[CAPACITY];
int num = 0, head = 0, tail = -1;
public:
// 入隊
bool push(const T& element) {
if (num == CAPACITY) return false;
tail = (++tail) % CAPACITY;
elements[tail] = element;
++num;
return true;
}
// 出隊
void pop() {
assert(!empty());
head = (++head) % CAPACITY;
--num;
}
// 判空
bool empty() const {
return num == 0;
}
// 訪隊首
const T& front() const {
assert(!empty());
return elements[head];
}
};代碼解釋:
- T elements[]保存數據;2個遊標,分別用於記錄隊首head和隊尾tail的位置(下標)。
- push()接口,先移動tail遊標,再把元素添加到隊尾。
- pop()接口,移動head遊標,彈出隊首元素(邏輯上彈出)。
- front()接口,返回隊首元素的引用。
- front()、pop()先做斷言,調用pop()/front()的客户代碼需確保隊列非空。
假設現在有一個Queue\<int>實例q,因為直接調用pop可能assert失敗,我們封裝一個try_pop(),代碼如下:
Queue<int> q;
void try_pop() {
if (!q.empty()) {
q.pop();
}
}如果多個線程調用try_pop(),會有問題,為什麼?
原因:判空+出隊這2個操作,不能在一個指令週期內完成。如果線程1在判斷隊列非空後,線程2穿插進來,判空也為偽,這樣就有可能2個線程競爭彈出唯一的元素。
多線程環境下,讀變量然後基於值做進一步操作,這樣的邏輯如果不加保護就會出錯,這是由數據使用方式引入的問題。
示例5
再看一個簡單的,簡單的對int32_t多線程讀寫。
// example 5
int32_t data[8] = {1,2,3,4,5,6,7,8};
struct Foo {
int32_t get() const { return x; }
void set(int32_t x) { this->x = x; }
int32_t x;
} foo;
void thread_write1() {
for (;;) { for (auto v : data) { foo.set(v); } }
}
void thread_write2() {
for (;;) { for (auto v : data) { foo.set(v); } }
}
void thread_read() {
for (;;) { printf("%d", foo.get()); }
}2個寫線程1個讀線程,寫線程在無限循環裏用data裏的元素值設置foo對象的x成分,讀線程簡單的打印foo對象的x值。程序一直跑下去,最後打印出來的數據,會出現除data初始化值外的數據嗎?
Foo::get的實現有問題嗎?如果有問題?是什麼問題?
示例6
看一個用數組實現FIFO隊列的程序,一個線程寫put(),一個線程讀get()。
// example 6
#include <iostream>
#include <algorithm>
// 用數組實現的環型隊列
class FIFO {
static const unsigned int CAPACITY = 1024; // 容量:需要滿足是2^N
unsigned char buffer[CAPACITY]; // 保存數據的緩衝區
unsigned int in = 0; // 寫入位置
unsigned int out = 0; // 讀取位置
unsigned int free_space() const { return CAPACITY - in + out; }
public:
// 返回實際寫入的數據長度(<= len),返回小於len時對應空閒空間不足
unsigned int put(unsigned char* src, unsigned int len) {
// 計算實際可寫入數據長度(<=len)
len = std::min(len, free_space());
// 計算從in位置到buffer結尾有多少空閒空間
unsigned int l = std::min(len, CAPACITY - (in & (CAPACITY - 1)));
// 1. 把數據放入buffer的in開始的緩衝區,最多到buffer結尾
memcpy(buffer + (in & (CAPACITY - 1)), src, l);
// 2. 把數據放入buffer開頭(如果上一步還沒有放完),len - l為0代表上一步完成數據寫入
memcpy(buffer, src + l, len - l);
in += len; // 修改in位置,累加,到達uint32_max後溢出迴繞
return len;
}
// 返回實際讀取的數據長度(<= len),返回小於len時對應buffer數據不夠
unsigned int get(unsigned char *dst, unsigned int len) {
// 計算實際可讀取的數據長度
len = std::min(len, in - out);
unsigned int l = std::min(len, CAPACITY - (out & (CAPACITY - 1)));
// 1. 從out位置開始拷貝數據到dst,最多拷貝到buffer結尾
memcpy(dst, buffer + (out & (CAPACITY - 1)), l);
// 2. 從buffer開頭繼續拷貝數據(如果上一步還沒拷貝完),len - l為0代表上一步完成數據獲取
memcpy(dst + l, buffer, len - l);
out += len; // 修改out,累加,到達uint32_max後溢出迴繞
return len;
}
};
環型隊列只是邏輯上的概念,因為採用了數組作為數據結構,所以實際物理存儲上並非環型。
- put()用於往隊列裏放數據,參數src+len描述了待放入的數據信息。
- get()用於從隊列取數據,參數dst+len描述了要把數據讀到哪裏、以及讀多少字節。
-
capacity精心選擇為2的n次方,可以得到3個好處:
- 非常技巧性的利用了無符號整型溢出迴繞,便於處理對in和out移動
- 便於計算長度,通過按位與操作&而不必除餘
- 搜索kfifo獲得更詳細的解釋
-
in和out是2個遊標:
- in用來指向新寫入數據的存放位置,寫入的時候,只需要簡單增加in。
- out用來指示從buffer的什麼位置讀取數據的,讀取的時候,也只需簡單增加out。
- in和out在操作上之所以能單調增加,得益於上述capacity的巧妙選擇。
- 為了簡化,隊列容量被限制為1024字節,不支持擴容,這不影響多線程的討論。
寫的時候,先寫入數據再移動in遊標;讀的時候,先拷貝數據,再移動out遊標;in遊標移動後,消費者才獲得get到新放入數據的機會。
直覺告訴我們2個線程不加同步的併發讀寫,會有問題,但真有問題嗎?如果有,到底有什麼問題?怎麼解決?
2.3 保護什麼
多線程程序裏,我們要保護的是數據而非代碼,雖然Java等語言裏有臨界代碼、sync方法,但最終要保護的還是代碼訪問的數據。
2.4 串行化
如果有一個線程正在訪問某共享(臨界)資源,那麼在它結束訪問之前,其他線程不能執行訪問同一資源的代碼(訪問臨界資源的代碼叫臨界代碼),其他線程想要訪問同一資源,則它必須等待,直到那個線程訪問完成,它才能獲得訪問的機會,現實中有很多這樣的例子。比如高速公路上的汽車過檢查站,假設檢查站只有一個車道,則無論高速路上有多少車道,過檢查站的時候只能一輛車接着一輛車,從單一車道魚貫而入。
對多線程訪問共享資源施加此種約束就叫串行化。
2.5 原子操作和原子變量
針對前面的兩個線程對同一整型變量自增的問題,如果“load、update、store”這3個步驟是不可分割的整體,即自增操作++x滿足原子性,上面的程序便不會有問題。
因為這樣的話,2個線程併發執行++x,只會有2個結果:
- 線程a ++x,然後線程b ++x,結果是2。
- 線程b ++x,然後線程a ++x,結果是2。
除此之外,不會出現第三種情況,線程a、b孰先孰後,取決於線程調度,但不影響最終結果。
Linux操作系統和C/C++編程語言都提供了整型原子變量,原子變量的自增、自減等操作都是原子的,操作是原子性的,意味着它是一個不可細分的操作整體,原子變量的用户觀察它,只能看到未完成和已完成2種狀態,看不到半完成狀態。
如何保證原子性是實現層面的問題,應用程序員只需要從邏輯上理解原子性,並能恰當的使用它就行了。原子變量非常適用於計數、產生序列號這樣的應用場景。
2.6 鎖
前面舉了很多例子,闡述多線程不加同步併發訪問數據會引起什麼問題,下面講解用鎖如何做同步。
2.6.1 互斥鎖
針對線程1 write_msg() + 線程2 read_msg()的問題,如果能讓線程1 write_msg()的過程中,線程2不能read_msg(),那就不會有問題。這個要求,其實就是要讓多個線程互斥訪問共享資源。
互斥鎖就是能滿足上述要求的同步機制,互斥是排他的意思,它可以確保在同一時間,只能有一個線程對那個共享資源進行訪問。
互斥鎖有且只有2種狀態:
- 已加鎖(locked)狀態
- 未加鎖(unlocked)狀態
互斥鎖提供加鎖和解鎖兩個接口:
- 加鎖(acquire):當互斥鎖處於未加鎖狀態時,則加鎖成功(把鎖設置為已加鎖狀態),並返回;當互斥鎖處於已加鎖狀態時,那麼試圖對它加鎖的線程會被阻塞,直到該互斥量被解鎖。
- 解鎖(release):通過把鎖設置為未加鎖狀態釋放鎖,其他因為申請加鎖而陷入等待的線程,將獲得執行機會。如果有多個等待線程,只有一個會獲得鎖而繼續執行。
我們為某個共享資源配置一個互斥鎖,使用互斥鎖做線程同步,那麼所有線程對該資源的訪問,都需要遵從“加鎖、訪問、解鎖”的三步:
DataType shared_resource;
Mutex shared_resource_mutex;
void shared_resource_visitor1() {
// step1: 加鎖
shared_resource_mutex.lock();
// step2: operate shared_resouce
// operation1
// step3: 解鎖
shared_resource_mutex.unlock();
}
void shared_resource_visitor2() {
// step1: 加鎖
shared_resource_mutex.lock();
// step2: operate shared_resouce
// operation2
// step3: 解鎖
shared_resource_mutex.unlock();
}shared_resource_visitor1()和shared_resource_visitor2()代表對共享資源的不同操作,多個線程可能調用同一個操作函數,也可能調用不同的操作函數。
假設線程1執行shared_resource_visitor1(),該函數在訪問數據之前,申請加鎖,如果互斥鎖已經被其他線程加鎖,則調用該函數的線程會阻塞在加鎖操作上,直到其他線程訪問完數據,釋放(解)鎖,阻塞在加鎖操作的線程1才會被喚醒,並嘗試加鎖:
- 如果沒有其他線程申請該鎖,那麼線程1加鎖成功,獲得了對資源的訪問權,完成操作後,釋放鎖。
-
如果其他線程也在申請該鎖,那麼:
- 如果其他線程搶到了鎖,那麼線程1繼續阻塞。
- 如果線程1搶到了該鎖,那麼線程1將訪問資源,再釋放鎖,其他競爭該鎖的線程得以有機會繼續執行。
如果不能承受加鎖失敗而陷入阻塞的代價,可以調用互斥量的try_lock()接口,它在加鎖失敗後會立即返回。
注意:在訪問資源前申請鎖訪問後釋放鎖,是一個編程契約,通過遵守契約而獲得數據一致性的保障,它並非一種硬性的限制,即如果別的線程遵從三步曲,而另一個線程不遵從這種約定,代碼能通過編譯且程序能運行,但結果可能是錯的。
2.6.2 讀寫鎖
讀寫鎖跟互斥鎖類似,也是申請鎖的時候,如果不能得到滿足則阻塞,但讀寫鎖跟互斥鎖也有不同,讀寫鎖有3個狀態:
- 已加讀鎖狀態
- 已加寫鎖狀態
- 未加鎖狀態
對應3個狀態,讀寫鎖有3個接口:加讀鎖,加寫鎖,解鎖:
- 加讀鎖:如果讀寫鎖處於已加寫鎖狀態,則申請鎖的線程阻塞;否則把鎖設置為已加讀鎖狀態併成功返回。
- 加寫鎖:如果讀寫鎖處於未加鎖狀態,則把鎖設置為已加寫鎖狀態併成功返回;否則阻塞。
- 解鎖:把鎖設置為未加鎖狀態後返回。
讀寫鎖提升了線程的並行度,可以提升吞吐。它可以讓多個讀線程同時讀共享資源,而寫線程訪問共享資源的時候,其他線程不能執行,所以,讀寫鎖適合對共享資源訪問“讀大於寫”的場合。讀寫鎖也叫“共享互斥鎖”,多個讀線程可以併發訪問同一資源,這對應共享的概念,而寫線程是互斥的,寫線程訪問資源的時候,其他線程無論讀寫,都不可以進入臨界代碼區。
考慮一個場景:如果有線程1、2、3共享資源x,讀寫鎖rwlock保護資源,線程1讀訪問某資源,然後線程2以寫的形式訪問同一資源x,因為rwlock已經被加了讀鎖,所以線程2被阻塞,然後過了一段時間,線程3也讀訪問資源x,這時候線程3可以繼續執行,因為讀是共享的,然後線程1讀訪問完成,線程3繼續訪問,過了一段時間,在線程3訪問完成前,線程1又申請讀資源,那麼它還是會獲得訪問權,但是寫資源的線程2會一直被阻塞。
為了避免共享的讀線程餓死寫線程,通常讀寫鎖的實現,會給寫線程優先權,當然這處決於讀寫鎖的實現,作為讀寫鎖的使用方,理解它的語義和使用場景就夠了。
2.6.3 自旋鎖
自旋鎖(Spinlock)的接口跟互斥量差不多,但實現原理不同。線程在acquire自旋鎖失敗的時候,它不會主動讓出CPU從而進入睡眠狀態,而是會忙等,它會緊湊的執行測試和設置(Test-And-Set)指令,直到TAS成功,否則就一直佔着CPU做TAS。
自旋鎖對使用場景有一些期待,它期待acquire自旋鎖成功後很快會release鎖,線程運行臨界區代碼的時間很短,訪問共享資源的邏輯簡單,這樣的話,別的acquire自旋鎖的線程只需要忙等很短的時間就能獲得自旋鎖,從而避免被調度走陷入睡眠,它假設自旋的成本比調度的低,它不願耗費時間在線程調度上(線程調度需要保存和恢復上下文需要耗費CPU)。
內核態線程很容易滿足這些條件,因為運行在內核態的中斷處理函數裏可以通過關閉調度,從而避免CPU被搶佔,而且有些內核態線程調用的處理函數不能睡眠,只能使用自旋鎖。
而運行在用户態的應用程序,則推薦使用互斥鎖等睡眠鎖。因為運行在用户態應用程序,雖然很容易滿足臨界區代碼簡短,但持有鎖時間依然可能很長。在分時共享的多任務系統上、當用户態線程的時間配額耗盡,或者在支持搶佔式的系統上、有更高優先級的任務就緒,那麼持有自旋鎖的線程就會被系統調度走,這樣持有鎖的過程就有可能很長,而忙等自旋鎖的其他線程就會白白消耗CPU資源,這樣的話,就跟自旋鎖的理念相背。
Linux系統優化過後的mutex實現,在加鎖的時候會先做有限次數的自旋,只有有限次自旋失敗後,才會進入睡眠讓出CPU,所以,實際使用中,它的性能也足夠好。此外,自旋鎖必須在多CPU或者多Core架構下,試想如果只有一個核,那麼它執行自旋邏輯的時候,別的線程沒有辦法運行,也就沒有機會釋放鎖。
2.6.4 鎖的粒度
合理設置鎖的粒度,粒度太大會降低性能,太小會增加代碼編寫複雜度。
2.6.5 鎖的範圍
鎖的範圍要儘量小,最小化持有鎖的時間。
2.6.6 死鎖
程序出現死鎖有兩種典型原因:
ABBA鎖
假設程序中有2個資源X和Y,分別被鎖A和B保護,線程1持有鎖A後,想要訪問資源Y,而訪問資源Y之前需要申請鎖B,而如果線程2正持有鎖B,並想要訪問資源X,為了訪問資源X,所以線程2需要申請鎖A。線程1和線程2分別持有鎖A和B,並都希望申請對方持有的鎖,因為線程申請對方持有的鎖,得不到滿足,所以便會陷入等待,也就沒有機會釋放自己持有的鎖,對方執行流也就沒有辦法繼續前進,導致相持不下,無限互等,進而死鎖。
上述的情況似乎很明顯,但如果代碼量很大,有時候,這種死鎖的邏輯不會這麼淺顯,它被複雜的調用邏輯所掩蓋,但抽繭剝絲,最根本的邏輯就是上面描述的那樣。這種情況叫ABBA鎖,既某個線程持有A鎖申請B鎖,而另一個線程持有B鎖申請A鎖。這種情況可以通過try lock實現,嘗試獲取鎖,如果不成功,則釋放自己持有的鎖,而不一根筋下去。另一種解法就是鎖排序,對A/B兩把鎖的加鎖操作,都遵從同樣的順序(比如先A後B),也能避免死鎖。
自死鎖
對於不支持重複加鎖的鎖,如果線程持有某個鎖,而後又再次申請鎖,因為該鎖已經被自己持有,再次申請鎖必然得不到滿足,從而導致死鎖。
2.7 條件變量
條件變量常用於生產者消費者模式,需配合互斥量使用。
假設你要編寫一個網絡處理程序,I/O線程從套接字接收字節流,反序列化後產生一個個消息(自定義協議),然後投遞到一個消息隊列,一組工作線程負責從消息隊列取出並處理消息。這是典型的生產者-消費者模式,I/O線程生產消息(往隊列put),Work線程消費消息(從隊列get),I/O線程和Work線程併發訪問消息隊列,顯然,消息隊列是競爭資源,需要同步。

可以給隊列配置互斥鎖,put和get操作前都先加鎖,操作完成再解鎖。代碼差不多是這樣的:
void io_thread() {
while (1) {
Msg* msg = read_msg_from_socket();
msg_queue_mutex.lock();
msg_queue.put(msg);
msg_queue_mutex.unlock();
}
}
void work_thread() {
while (1) {
msg_queue_mutex.lock();
Msg* msg = msg_queue.get();
msg_queue_mutex.unlock();
if (msg != nullptr) {
process(msg);
}
}
}work線程組的每個線程都忙於檢查消息隊列是否有消息,如果有消息就取一個出來,然後處理消息,如果沒有消息就在循環裏不停檢查,這樣的話,即使負載很輕,但work_thread還是會消耗大量的CPU時間。
我們當然可以在兩次查詢之間加入短暫的sleep,從而讓出cpu,但是這個睡眠的時間設置為多少合適呢?設置長了的話,會出現消息到來得不到及時處理(延遲上升);設置太短了,還是無辜消耗了CPU資源,這種不斷問詢的方式在編程上叫輪詢。
輪詢行為邏輯上,相當於你在等一個投遞到樓下小郵局的包裹,你下樓查驗沒有之後就上樓回房間,然後又下樓查驗,你不停的上下樓查驗,其實大可不必如此,何不等包裹到達以後,讓門衞打電話通知你去取呢?
條件變量提供了一種類似通知notify的機制,它讓兩類線程能夠在一個點交匯。條件變量能夠讓線程等待某個條件發生,條件本身受互斥鎖保護,因此條件變量必須搭配互斥鎖使用,鎖保護條件,線程在改變條件前先獲得鎖,然後改變條件狀態,再解鎖,最後發出通知,等待條件的睡眠中的線程在被喚醒前,必須先獲得鎖,再判斷條件狀態,如果條件不成立,則繼續轉入睡眠並釋放鎖。
對應到上面的例子,工作線程等待的條件是消息隊列有消息(非空),用條件變量改寫上面的代碼:
void io_thread() {
while (1) {
Msg* msg = read_msg_from_socket();
{
std::lock_guard<std::mutex> lock(msg_queue_mutex);
msg_queue.push_back(msg);
}
msg_queue_not_empty.notify_all();
}
}
void work_thread() {
while (1) {
Msg* msg = nullptr;
{
std::unique_lock<std::mutex> lock(msg_queue_mutex);
msg_queue_not_empty.wait(lock, []{ return !msg_queue.empty(); });
msg = msg_queue.get();
}
process(msg);
}
}std::lock_guard是互斥量的一個RAII包裝類,std::unique_lock除了會在析構函數自動解鎖外,還支持主動unlock()。
生產者在往msg_queue投遞消息的時候,需要對msg_queue加鎖,通知work線程的代碼可以放在解鎖之後,等待msg_queue_not_empty條件必須受msg_queue_mutex保護,wait的第二個參數是一個lambda表達式,因為會有多個work線程被喚醒,線程被喚醒後,會重新獲得鎖,檢查條件,如果不成立,則再次睡眠。條件變量的使用需要非常謹慎,否則容易出現不能喚醒的情況。
C語言的條件變量、Posix條件變量的編程接口跟C++的類似,概念上是一致的,故在此不展開介紹。
2.8 lock-free和無鎖數據結構
2.8.1 鎖同步的問題
線程同步分為阻塞型同步和非阻塞型同步。
- 互斥量、信號、條件變量這些系統提供的機制都屬於阻塞型同步,在爭用資源的時候,會導致調用線程阻塞。
- 非阻塞型同步是指在無鎖的情況下,通過某種算法和技術手段實現不用阻塞而同步。
鎖是阻塞同步機制,阻塞同步機制的缺陷是可能掛起你的程序,如果持有鎖的線程崩潰或者hang住,則鎖永遠得不到釋放,而其他線程則將陷入無限等待;另外,它也可能導致優先級倒轉等問題。所以,我們需要lock-free這類非阻塞的同步機制。
2.8.2 什麼是lock-free
lock-free沒有鎖同步的問題,所有線程無阻礙的執行原子指令,而不是等待。比如一個線程讀atomic類型變量,一個線程寫atomic變量,它們沒有任何等待,硬件原子指令確保不會出現數據不一致,寫入數據不會出現半完成,讀取數據也不會讀一半。
那到底什麼是lock-free?有人説lock-free就是不使用mutex / semaphores之類的無鎖(lock-Less)編程,這句話嚴格來説並不對。
我們先看一下wiki對Lock-free的描述:
Lock-freedom allows individual threads to starve but guarantees system-wide throughput. An algorithm is lock-free if, when the program threads are run for a sufficiently long time, at least one of the threads makes progress (for some sensible definition of progress). All wait-free algorithms are lock-free.
In particular, if one thread is suspended, then a lock-free algorithm guarantees that the remaining threads can still make progress. Hence, if two threads can contend for the same mutex lock or spinlock, then the algorithm is not lock-free. (If we suspend one thread that holds the lock, then the second thread will block.)
翻譯一下:
- 第1段:lock-free允許單個線程飢餓但保證系統級吞吐。如果一個程序線程執行足夠長的時間,那麼至少一個線程會往前推進,那麼這個算法就是lock-free的。
- 第2段:尤其是,如果一個線程被暫停,lock-free算法保證其他線程依然能夠往前推進。
第1段給lock-free下定義,第2段則是對lock-free作解釋:如果2個線程競爭同一個互斥鎖或者自旋鎖,那它就不是lock-free的;因為如果暫停(Hang)持有鎖的線程,那麼另一個線程會被阻塞。
wiki的這段描述很抽象,它不夠直觀,稍微再解釋一下:lock-free描述的是代碼邏輯的屬性,不使用鎖的代碼,大部分具有這種屬性。大家經常會混淆這lock-free和無鎖這2個概念。其實,lock-free是對代碼(算法)性質的描述,是屬性;而無鎖是説代碼如何實現,是手段。
lock-free的關鍵描述是:如果一個線程被暫停,那麼其他線程應能繼續前進,它需要有系統級(system-wide)的吞吐。
如圖,兩個線程在時間線上,至少有一個線程處於running狀態。

我們從反面舉例來看,假設我們要藉助鎖實現一個無鎖隊列,我們可以直接使用線程不安全的std::queue + std::mutex來做:
template <typename T>
class Queue {
public:
void push(const T& t) {
q_mutex.lock();
q.push(t);
q_mutex.unlock();
}
private:
std::queue<T> q;
std::mutex q_mutex;
};如果有線程A/B/C同時執行push方法,最先進入的線程A獲得互斥鎖。線程B和C因為獲取不到互斥鎖而陷入等待。這個時候,線程A如果因為某個原因(如出現異常,或者等待某個資源)而被永久掛起,那麼同樣執行push的線程B/C將被永久掛起,系統整體(system-wide)沒法推進,而這顯然不符合lock-free的要求。因此:所有基於鎖(包括spinlock)的併發實現,都不是lock-free的。
因為它們都會遇到同樣的問題:即如果永久暫停當前佔有鎖的線程/進程的執行,將會阻塞其他線程/進程的執行。而對照lock-free的描述,它允許部分process(理解為執行流)餓死但必須保證整體邏輯的持續前進,基於鎖的併發顯然是違背lock-free要求的。
2.8.3 CAS loop實現Lock-free
Lock-Free同步主要依靠CPU提供的read-modify-write原語,著名的“比較和交換”CAS(Compare And Swap)在X86機器上是通過cmpxchg系列指令實現的原子操作,CAS邏輯上用代碼表達是這樣的:
bool CAS(T* ptr, T expect_value, T new_value) {
if (*ptr != expect_value) {
return false;
}
*ptr = new_value;
return true;
}CAS接受3個參數:
- 內存地址
- 期望值,通常傳第一個參數所指內存地址中的舊值
- 新值
邏輯描述:CAS比較內存地址中的值和期望值,如果不相同就返回失敗,如果相同就將新值寫入內存並返回成功。
當然這個C函數描述的只是CAS的邏輯,這個函數操作不是原子的,因為它可以劃分成幾個步驟:讀取內存值、判斷、寫入新值,各步驟之間是可以插入其他操作的。不過前面講了,原子指令相當於把這些步驟打包,它可能是通過lock; cmpxchg指令實現的,但那是實現細節,程序員更應該注重在邏輯上理解它的行為。
通過CAS實現Lock-free的代碼通常藉助循環,代碼如下:
do {
T expect_value = *ptr;
} while (!CAS(ptr, expect_value, new_value));- 創建共享數據的本地副本:expect_value。
- 根據需要修改本地副本,從ptr指向的共享數據裏load後賦值給expect_value。
- 檢查共享的數據跟本地副本是否相等,如果相等,則把新值複製到共享數據。
第三步是關鍵,雖然CAS是原子的,但加載expect\_value跟CAS這2個步驟,並不是原子的。所以,我們需要藉助循環,如果ptr內存位置的值沒有變(*ptr \== expect_value),那就存入新值返回成功;否則説明加載expect\_value後,ptr指向的內存位置被其他線程修改了,這時候就返回失敗,重新加載expect\_value,重試,直到成功為止。
CAS loop支持多線程併發寫,這個特點太有用了,因為多線程同步,很多時候都面臨多寫的問題,我們可以基於CAS實現Fetch-and-add(FAA)算法,它看起來像這樣:
T faa(T& t) {
T temp = t;
while (!compare_and_swap(x, temp, temp + 1));
}第一步加載共享數據的值到temp,第二步比較+存入新值,直到成功。
2.8.4 無鎖數據結構:lock-free stack
無鎖數據結構是通過非阻塞算法而非鎖保護共享數據,非阻塞算法保證競爭共享資源的線程,不會因為互斥而讓它們的執行無限期暫停;無阻塞算法是lock-free的,因為無論如何調度都能確保有系統級的進度。wiki定義如下:
A non-blocking algorithm ensures that threads competing for a shared resource do not have their execution indefinitely postponed by mutual exclusion. A non-blocking algorithm is lock-free if there is guaranteed system-wide progress regardless of scheduling.
下面是C++ atomic compare_exchange_weak()實現的一個lock-free堆棧(from CppReference):
template <typename T>
struct node {
T data;
node* next;
node(const T& data) : data(data), next(nullptr) {}
};
template <typename T>
class stack {
std::atomic<node<T>*> head;
public:
void push(const T& data) {
node<T>* new_node = new node<T>(data);
new_node->next = head.load(std::memory_order_relaxed);
while (!head.compare_exchange_weak(new_node->next, new_node,
std::memory_order_release,
std::memory_order_relaxed));
}
};代碼解析:
- 節點(node)保存T類型的數據data,並且持有指向下一個節點的指針。
- std::atomic\<node<T>*>類型表明atomic裏放置的是Node的指針,而非Node本身,因為指針在64位系統上是8字節,等於機器字長,再長沒法保證原子性。
- stack類包含head成員,head是一個指向頭結點的指針,頭結點指針相當於堆頂指針,剛開始沒有節點,head為NULL。
- push函數裏,先根據data值創建新節點,然後要把它放到堆頂。
- 因為是用鏈表實現的棧,所以,如果新節點要成為新的堆頂(相當於新節點作為新的頭結點插入),那麼新節點的next域要指向原來的頭結點,並讓head指向新節點。
- new_node->next = head.load把新節點的next域指向原頭結點,然後head.compare_exchange_weak(new_node->next, new_node),讓head指向新節點。
- C++ atomic的compare_exchange_weak()跟上述的CAS稍有不同,head.load()不等於new_node->next的時候,它會把head.load()的值重新加載到new_node->next。
- 所以,在加載head值和CAS之間,如果其他線程調用push操作,改變了head的值,那沒有關係,該線程的本次cas失敗,下次重試便可以了。
- 多個線程同時push時,任一線程在任意步驟阻塞/掛起,其他線程都會繼續執行並最終返回,無非就是多執行幾次while循環。
這樣的行為邏輯顯然符合lock-free的定義,注意用CAS+Loop實現自旋鎖不符合lock-free的定義,注意區分。
2.9 程序序:Program Order
對單線程程序而言,代碼會一行行順序執行,就像我們編寫的程序的順序那樣。比如:
a = 1;
b = 2;會先執行a=1再執行b=2,從程序角度看到的代碼行依次執行叫程序序,我們在此基礎上構建軟件,並以此作為討論的基礎。
2.10 內存序:Memory Order
與程序序相對應的內存序,是指從某個角度觀察到的對於內存的讀和寫所真正發生的順序。內存操作順序並不唯一,在一個包含core0和core1的CPU中,core0和core1有着各自的內存操作順序,這兩個內存操作順序不一定相同。從包含多個Core的CPU的視角看到的全局內存操作順序跟單core視角看到的內存操作順序亦不同,而這種不同,對於有些程序邏輯而言,是不可接受的,例如:
程序序要求a = 1在b = 2之前執行,但內存操作順序可能並非如此,對a賦值1並不確保發生在對b賦值2之前,這是因為:
- 如果編譯器認為對b賦值沒有依賴對a賦值,那它完全可能在編譯期調整編譯後的彙編指令順序。
- 即使編譯器不做調整,到了執行期,也有可能對b的賦值先於對a賦值執行。
雖然對一個Core而言,如上所述,這個Core觀察到的內存操作順序不一定符合程序序,但內存操作序和程序序必定產生相同的結果,無論在單Core上對a、b的賦值哪個先發生,結果上都是a被賦值為1、b被賦值為2,如果單核上亂序執行會影響結果,那編譯器的指令重排和CPU亂序執行便不會發生,硬件會提供這項保證。
但多核系統,硬件不提供這樣的保證,多線程程序中,每個線程所工作的Core觀察到的不同內存操作序,以及這些順序與全局內存序的差異,常常導致多線程同步失敗,所以,需要有同步機制確保內存序與程序序的一致,內存屏障(Memory Barrier)的引入,就是為了解決這個問題,它讓不同的Core之間,以及Core與全局內存序達成一致。
2.11 亂序執行:Out-of-order Execution
亂序執行會引起內存順序跟程序順序不同,亂序執行的原因是多方面的,比如編譯器指令重排、超標量指令流水線、預測執行、Cache-Miss等。內存操作順序無法精確匹配程序順序,這有可能帶來混亂,既然有副作用,那為什麼還需要亂序執行呢?答案是為了性能。
我們先看看沒有亂序執行之前,早期的有序處理器(In-order Processors)是怎麼處理指令的?
- 指令獲取,從代碼節內存區域加載指令到I-Cache
- 譯碼
- 如果指令操作數可用(例如操作數位於寄存器中),則分發指令到對應功能模塊中;如果操作數不可用,通常是需要從內存加載,則處理器會stall,一直等到它們就緒,直到數據被加載到Cache或拷貝進寄存器
- 指令被功能單元執行
- 功能單元將結果寫回寄存器或內存位置
亂序處理器(Out-of-order Processors)又是怎麼處理指令的呢?
- 指令獲取,從代碼節內存區域加載指令到I-Cache
- 譯碼
- 分發指令到指令隊列
- 指令在指令隊列中等待,一旦操作數就緒,指令就離開指令隊列,那怕它之前的指令未被執行(亂序)
- 指令被派往功能單元並被執行
- 執行結果放入隊列(Store Buffer),而不是直接寫入Cache
- 只有更早請求執行的指令結果寫入cache後,指令執行結果才寫入Cache,通過對指令結果排序寫入cache,使得執行看起來是有序的
指令亂序執行是結果,但原因並非只有CPU的亂序執行,而是由兩種因素導致:
- 編譯期:指令重排(編譯器),編譯器會為了性能而對指令重排,源碼上先後的兩行,被編譯器編譯後,可能調換指令順序,但編譯器會基於一套規則做指令重排,有明顯依賴的指令不會被隨意重排,指令重排不能破壞程序邏輯。
- 運行期:亂序執行(CPU),CPU的超標量流水線、以及預測執行、Cache-Miss等都有可能導致指令亂序執行,也就是説,後面的指令有可能先於前面的指令執行。
2.12 Store Buffer
為什麼需要Store Buffer?
考慮下面的代碼:
void set_a() {
a = 1;
}- 假設運行在core0上的set_a()對整型變量a賦值1,計算機通常不會直接寫穿通到內存,而是會在Cache中修改對應Cache Line
- 如果Core0的Cache裏沒有a,賦值操作(store)會造成Cache Miss
- Core0會stall在等待Cache就緒(從內存加載變量a到對應的Cache Line),但Stall會損害CPU性能,相當於CPU在這裏停頓,白白浪費着寶貴的CPU時間
- 有了Store Buffer,當變量在Cache中沒有就位的時候,就先Buffer住這個Store操作,而Store操作一旦進入Store Buffer,core便認為自己Store完成,當隨後Cache就位,store會自動寫入對應Cache。
所以,我們需要Store Buffer,每個Core都有獨立的Store Buffer,每個Core都訪問私有的Store Buffer,Store Buffer幫助CPU遮掩了Store操作帶來的延遲。
Store Buffer會帶來什麼問題?
a = 1;
b = 2;
assert(a == 1);上面的代碼,斷言a==1的時候,需要讀(load)變量a的值,而如果a在被賦值前就在Cache中,就會從Cache中讀到a的舊值(可能是1之外的其他值),所以斷言就可能失敗。但這樣的結果顯然是不能接受的,它違背了最直觀的程序順序性。
問題出在變量a除保存在內存外,還有2份拷貝:一份在Store Buffer裏,一份在Cache裏;如果不考慮這2份拷貝的關係,就會出現數據不一致。那怎麼修復這個問題呢?
可以通過在Core Load數據的時候,先檢查Store Buffer中是否有懸而未決的a的新值,如果有,則取新值;否則從cache取a的副本。這種技術在多級流水線CPU設計的時候就經常使用,叫Store Forwarding。有了Store Buffer Forwarding,就能確保單核程序的執行遵從程序順序性,但多核還是有問題,讓我們考查下面的程序:
多核內存序問題
int a = 0; // 被CPU1 Cache
int b = 0; // 被CPU0 Cache
// CPU0執行
void x() {
a = 1;
b = 2;
}
// CPU1執行
void y() {
while (b == 0);
assert(a == 1);
}假設a和b都被初始化為0;CPU0執行x()函數,CPU1執行y()函數;變量a在CPU1的local Cache裏,變量b在CPU0的local Cache裏。
- CPU0執行a = 1的時候,因為a不在CPU0的local cache,CPU0會把a的新值1寫入Store Buffer裏,併發送Read Invalidate消息給其他CPU。
- CPU1執行while (b == 0),因為b不在CPU1的local cache裏,CPU1會發送Read消息去其他CPU獲取b的值。
- CPU0執行b = 2,因為b在CPU0的local Cache,所以直接更新local cache中b的副本。
- CPU0收到CPU1發來的read消息,把b的新值2發送給CPU1;同時存放b的Cache Line的狀態被設置為Shared,以反應b同時被CPU0和CPU1 cache住的事實。
- CPU1收到b的新值2後結束循環,繼續執行assert(a == 1),因為此時local Cache中的a值為0,所以斷言失敗。
- CPU1收到CPU0發來的Read Invalidate後,更新a的值為1,但為時已晚,程序在上一步已經崩了(assert失敗)。
怎麼辦?答案留到內存屏障一節揭曉。
2.13 Invalidate Queue
為什麼需要Invalidate Queue?
當一個變量加載到多個core的Cache,則這個Cache Line處於Shared狀態,如果Core1要修改這個變量,則需要通過發送核間消息Invalidate來通知其他Core把對應的Cache Line置為Invalid,當其他Core都Invalid這個CacheLine後,則本Core獲得該變量的獨佔權,這個時候就可以修改它了。
收到Invalidate消息的core需要回Invalidate ACK,一個個core都這樣ACK,等所有core都回復完,Core1才能修改它,這樣CPU就白白浪費。
事實上,其他核在收到Invalidate消息後,會把Invalidate消息緩存到Invalidate Queue,並立即回覆ACK,真正Invalidate動作可以延後再做,這樣一方面因為Core可以快速返回別的Core發出的Invalidate請求,不會導致發生Invalidate請求的Core不必要的Stall,另一方面也提供了進一步優化可能,比如在一個CacheLine裏的多個變量的Invalidate可以攢一次做了。
但寫Store Buffer的方式其實是Write Invalidate,它並非立即寫入內存,如果其他核此時從內存讀數,則有可能不一致。
2.14 內存屏障
那有沒有方法確保對a的賦值一定先於對b的賦值呢?有,內存屏障被用來提供這個保障。
內存屏障(Memory Barrier),也稱內存柵欄、屏障指令等,是一類同步屏障指令,是CPU或編譯器在對內存隨機訪問的操作中的一個同步點,同步點之前的所有讀寫操作都執行後,才可以開始執行此點之後的操作。語義上,內存屏障之前的所有寫操作都要寫入內存;內存屏障之後的讀操作都可以獲得同步屏障之前的寫操作的結果。
內存屏障,其實就是提供一種機制,確保代碼裏順序寫下的多行,會按照書寫的順序,被存入內存,主要是解決Store Buffer引入導致的寫入內存間隙的問題。
void x() {
a = 1;
wmb();
b = 2;
}像上面那樣在a=1和b=2之間插入一條內存屏障語句,就能確保a=1先於b=2生效,從而解決了內存亂序訪問問題,那插入的這句smp_mb(),到底會幹什麼呢?
回憶前面的流程,CPU0在執行完a = 1之後,執行smp_mb()操作,這時候,它會給Store Buffer裏的所有數據項做一個標記(marked),然後繼續執行b = 2,但這時候雖然b在自己的cache裏,但由於store buffer裏有marked條目,所以,CPU0不會修改cache中的b,而是把它寫入Store Buffer;所以CPU0收到Read消息後,會把b的0值發給CPU1,所以繼續在while (b)自旋。
簡而言之,Core執行到write memory barrier(wmb)的時候,如果Store Buffer還有懸而未決的store操作,則都會被mark上,直到被標註的Store操作進入內存後,後續的Store操作才能被執行,因此wmb保障了barrier前後操作的順序,它不關心barrier前的多個操作的內存序,以及barrier後的多個操作的內存序,是否與Global Memory Order一致。
a = 1;
b = 2;
wmb();
c = 3;
d = 4;wmb()保證“a=1;b=2”發生在“c=3;d = 4”之前,不保證a = 1和b = 2的內存序,也不保證c = 3和d = 4的內部序。
Invalidate Queue的引入的問題
就像引入Store Buffer會影響Store的內存一致性,Invalidate Queue的引入會影響Load的內存一致性。因為Invalidate queue會緩存其他核發過來的消息,比如Invalidate某個數據的消息被delay處置,導致core在Cache Line中命中這個數據,而這個Cache Line本應該被Invalidate消息標記無效。如何解決這個問題呢?
一種思路是硬件確保每次load數據的時候,需要確保Invalidate Queue被清空,這樣可以保證load操作的強順序
軟件的思路,就是仿照wmb()的定義,加入rmb()約束。rmb()給我們的invalidate queue加上標記。當一個load操作發生的時候,之前的rmb()所有標記的invalidate命令必須全部執行完成,然後才可以讓隨後的load發生。這樣,我們就在rmb()前後保證了load觀察到的順序等同於global memory order
所以,我們可以像下面這樣修改代碼:
a = 1;
wmb();
b = 2;while(b != 2) {};
rmb();
assert(a == 1);系統對內存屏障的支持
gcc編譯器在遇到內嵌彙編語句asm volatile("" ::: "memory"),將以此作為一條內存屏障,重排序內存操作,即此語句之前的各種編譯優化將不會持續到此語句之後。
Linux 內核提供函數 barrier()用於讓編譯器保證其之前的內存訪問先於其之後的完成。
#define barrier() __asm__ __volatile__("" ::: "memory")CPU內存屏障:
- 通用barrier,保證讀寫操作有序, mb()和smp_mb()
- 寫操作barrier,僅保證寫操作有序,wmb()和smp_wmb()
- 讀操作barrier,僅保證讀操作有序,rmb()和smp_rmb()
小結
- 為了提高處理器的性能,SMP中引入了store buffer(以及對應實現store buffer forwarding)和invalidate queue。
- store buffer的引入導致core上的store順序可能不匹配於global memory的順序,對此,我們需要使用wmb()來解決。
- invalidate queue的存在導致core上觀察到的load順序可能與global memory order不一致,對此,我們需要使用rmb()來解決。
- 由於wmb()和rmb()分別只單獨作用於store buffer和invalidate queue,因此這兩個memory barrier共同保證了store/load的順序。
3 偽共享
多個線程同時讀寫同一個Cache Line中的變量、導致CPU Cache頻繁失效,從而使得程序性能下降的現象稱為偽共享(False Sharing)。
const size_t shm_size = 16*1024*1024; //16M
static char shm[shm_size];
std::atomic<size_t> shm_offset{0};
void f() {
for (;;) {
auto off = shm_offset.fetch_add(sizeof(long));
if (off >= shm_size) break;
*(long*)(shm + off) = off; // 賦值
}
}考察上面的程序:shm是一塊16M字節的內存,我測試的機器的L3 Cache是32M,16M字節能確保shm在Cache裏放得下。f()函數的循環裏,視shm為long類型的數組,依次給每個元素賦值,shm_offset用於記錄偏移位置,shm_offset.fetch_add(sizeof(long))原子性的增加shm_offset的值(因為x86_64系統上long的長度為8,所以shm_offset每次增加8),並返回增加前的值,對shm上long數組的每個元素賦值後,結束循環從函數返回。
因為shm_offset是atomic類型變量,所以多線程調用f()依然能正常工作,雖然多個線程會競爭shm_offset,但每個線程會排他性的對各long元素賦值,多線程並行會加快對shm的賦值操作。我們加上多線程調用代碼:
std::atomic<size_t> step{0};
const int THREAD_NUM = 2;
void work_thread() {
const int LOOP_N = 10;
for (int n = 1; n <= LOOP_N; ++n) {
f();
++step;
while (step.load() < n * THREAD_NUM) {}
shm_offset = 0;
}
}
int main() {
std::thread threads[THREAD_NUM];
for (int i = 0; i < THREAD_NUM; ++i) {
threads[i] = std::move(std::thread(work_thread));
}
for (int i = 0; i < THREAD_NUM; ++i) {
threads[i].join();
}
return 0;
}- main函數裏啓動2個工作線程work_thread。
- 工作線程對shm共計賦值10輪,後面的每一輪會訪問Cache裏的shm數據,step用於work_thread之間每一輪的同步。
- 工作線程調用完f()後會增加step,等2個工作線程都調用完之後,step的值增加到n * THREAD_NUM後,while()會結束循環,重置shm_offset,重新開始新一輪對shm的賦值。
如圖所示:

編譯後執行上面的程序,產生如下的結果:
time ./a.out
real 0m3.406s
user 0m6.740s
sys 0m0.040stime命令用於時間測量,a.out程序運行完成後會打印耗時,real列顯式耗時3.4秒。
3.1 改進版f_fast
我們稍微修改一下f函數,改進版f函數取名f_fast:
void f_fast() {
for (;;) {
const long inner_loop = 16;
auto off = shm_offset.fetch_add(sizeof(long) * inner_loop);
for (long j = 0; j < inner_loop; ++j) {
if (off >= shm_size) return;
*(long*)(shm + off) = j;
off += sizeof(long);
}
}
}for循環裏,shm_offset不再是每次增加8字節(sizeof(long)),而是8*16=128字節,然後在內層的循環裏,依次對16個long連續元素賦值,然後下一輪循環又再次增加128字節,直到完成對shm的賦值。如圖所示:

編譯後重新執行程序,結果顯示耗時降低到0.06秒,對比前一種耗時3.4秒,f_fast性能提升明顯。
time ./a.out
real 0m0.062s
user 0m0.110s
sys 0m0.012sf和f_fast的行為差異
shm數組總共有2M個long元素,因為16M / sizeof(long) 得 2M:
1、f()函數行為邏輯
- 線程1和線程2的work_thread裏會交錯地對shm元素賦值,shm的2M個long元素,會順序的一個接一個的派給2個線程去賦值。
- 可能的行為:元素1由線程1賦值,元素2由線程2賦值,然後元素3和元素4由線程1賦值,然後元素5又由線程2賦值...
- 每次分派元素的時候,shm_offset都會atomic的增加8字節,所以不會出現2個線程給同1個元素賦值的情況。
2、f_fast()函數行為邏輯
- 每次派元素的時候,shm_offset原子性的增加128字節(16個元素)。
- 這16個字節作為一個整體,派給線程1或者線程2;雖然線程1和線程2還是會交錯的操作shm元素,但是以16個元素(128字節)為單元,這16個連續的元素不會被分開派發給不同線程。
- 一次派發的16個元素,會在一個線程裏被一個接着一個的賦值(內部循環裏)。
3.2 為什麼f_fast更快
第一眼感覺是f_fast()裏shm_offset.fetch_add()調用頻次降低到了原來的1/16,有理由懷疑是原子變量的競爭減少導致程序執行速度加快。為了驗證,讓我們在內層的循環里加一個原子變量test的fetch_add,test原子變量的競爭會像f()函數裏shm_offset.fetch_add()一樣激烈,修改後的f_fast代碼變成下面這樣:
void f_fast() {
for (;;) {
const long inner_loop = 16;
auto off = shm_offset.fetch_add(sizeof(long) * inner_loop);
for (long j = 0; j < inner_loop; ++j) {
test.fetch_add(1);
if (off >= shm_size) return;
*(long*)(shm + off) = j;
off += sizeof(long);
}
}
}為了避免test.fetch_add(1)的調用被編譯器優化掉,我們在main函數的最後把test的值打印出來。編譯後測試一下,結果顯示:執行時間只是稍微增加到real 0m0.326s,很顯然,並不是atomic的調用頻次減少導致性能飆升。
重新審視f()循環裏的邏輯:f()循環裏的操作很簡單:原子增加、判斷、賦值。我們把f()的裏賦值註釋掉,再測試一下,發現它的速度得到了很大提升,看來是(long)(shm + off) = off這一行代碼執行慢,但這明明只是一行賦值。我們把它反彙編來看,它只是一個mov指令,源操作數是寄存器,目標操作數是內存地址,從寄存器拷貝數據到一個內存地址,為什麼會這麼慢呢?
3.3 原因
現在揭曉答案:導致f()性能底下的元兇是偽共享(false sharing)。那什麼是偽共享?要説清這個問題,還得聯繫CPU的架構以及CPU怎麼訪問數據,回顧一下關於多核Cache結構。
背景知識
現代CPU可以有多個核,每個核有自己的L1-L2緩存,L1又區分數據緩存(L1-DCache)和指令緩存(L1-ICache),L2不區分數據和指令Cache,而L3是跨核共享的,L3通過內存總線連接到內存,內存被所有CPU所有Core共享。
CPU訪問L1 Cache的速度大約是訪問內存的100倍,Cache作為CPU與內存之間的緩存,減少對內存的訪問頻率。
從內存加載數據到Cache的時候,是以Cache Line為長度單位的,Cache Line的長度通常是64字節,所以,那怕只讀一個字節,但是包含該字節的整個Cache Line都會被加載到緩存,同樣,如果修改一個字節,那麼最終也會導致整個Cache Line被沖刷到內存。
如果一塊內存數據被多個線程訪問,假設多個線程在多個Core上並行執行,那麼它便會被加載到多個Core的的Local Cache中;這些線程在哪個Core上運行,就會被加載到哪個Core的Local Cache中,所以,內存中的一個數據,在不同Core的Cache裏會同時存在多份拷貝。
那麼,便會存在緩存一致性問題。當一個Core修改其緩存中的值時,其他Core不能再使用舊值。該內存位置將在所有緩存中失效。此外,由於緩存以緩存行而不是單個字節的粒度運行,因此整個緩存行將在所有緩存中失效。如果我們修改了Core1緩存裏的某個數據,則該數據所在的Cache Line的狀態需要同步給其他Core的緩存,Core之間可以通過核間消息同步狀態,比如通過發送Invalidate消息給其他核,接收到該消息的核會把對應Cache Line置為無效,然後重新從內存里加載最新數據。
當然,被加載到多個Core緩存中的同一Cache Line,會被標記為共享(Shared)狀態,對共享狀態的緩存行進行修改,需要先獲取緩存行的修改權(獨佔),MESI協議用來保證多核緩存的一致性,更多的細節可以參考MESI的文章。
示例分析
假設線程1運行在Core1,線程2運行在Core2。
- 因為shm被線程1和線程2這兩個線程併發訪問,所以shm的內存數據會以Cache Line粒度,被同時加載到2個Core的Cache,因為被多核共享,所以該Cache Line被標註為Shared狀態。
- 假設線程1在offset為64的位置寫入了一個8字節的數據(sizeof(long)),要修改一個狀態為Shared的Cache Line,Core1會發送核間通信消息到Core2,去拿到該Cache Line的獨佔權,在這之後,Core1才能修改Local Cache
- 線程1執行完shm_offset.fetch_add(sizeof(long))後,shm_offset會增加到72。
- 這時候Core2上運行的線程2也會執行shm_offset.fetch_add(sizeof(long)),它返回72並將shm_offset增加到80。
- 線程2接下來要修改shm[72]的內存位置,因為shm[64]和shm[72]在一個Cache Line,而這個Cache Line又被置為Invalidate,所以,它需要從內存裏重新加載這一個Cache Line,而在這之前,Core1上的線程1需要把Cache Line沖刷到內存,這樣線程2才能加載最新的數據。
這種交替執行模式,相當於Core1和Core2之間需要頻繁的發送核間消息,收到消息的Core的Cache Line被置為無效,並重新從內存里加載數據到Cache,每次修改後都需要把Cache中的數據刷入內存,這相當於廢棄掉了Cache,因為每次讀寫都直接跟內存打交道,Cache的作用不復存在,這就是性能低下的原因。
這種多核多線程程序,因為併發讀寫同一個Cache Line的數據(臨近位置的內存數據),導致Cache Line的頻繁失效,內存的頻繁Load/Store,從而導致性能急劇下降的現象叫偽共享,偽共享是性能殺手。
3.4 另一個偽共享的例子
假設線程x和y,分別修改Data的a和b變量,如果被頻繁調用,也會出現性能低下的情況,怎麼規避呢?
struct Data {
int a;
int b;
} data; // global
void thread1() {
data.a = 1;
}
void thread2() {
data.b = 2;
}空間換時間
避免Cache偽共享導致性能下降的思路是用空間換時間,通過增加填充,讓a和b兩個變量分佈到不同的Cache Line,這樣對a和b的修改就會作用於不同Cache Line,就能避免Cache失效的問題。
struct Data {
int a;
int padding[60];
int b;
};在Linux kernel中存在__cacheline_aligned_in_smp宏定義用於解決false sharing問題。
#ifdef CONFIG_SMP
#define __cacheline_aligned_in_smp __cacheline_aligned
#else
#define __cacheline_aligned_in_smp
#endif
struct Data {
int a;
int b __cacheline_aligned_in_smp;
};從上面的宏定義,可以看到:
- 在多核系統裏,該宏定義是 __cacheline_aligned,也就是Cache Line的大小
- 在單核系統裏,該宏定義是空的
4 小結
pthread接口提供的幾種同步原語如下:
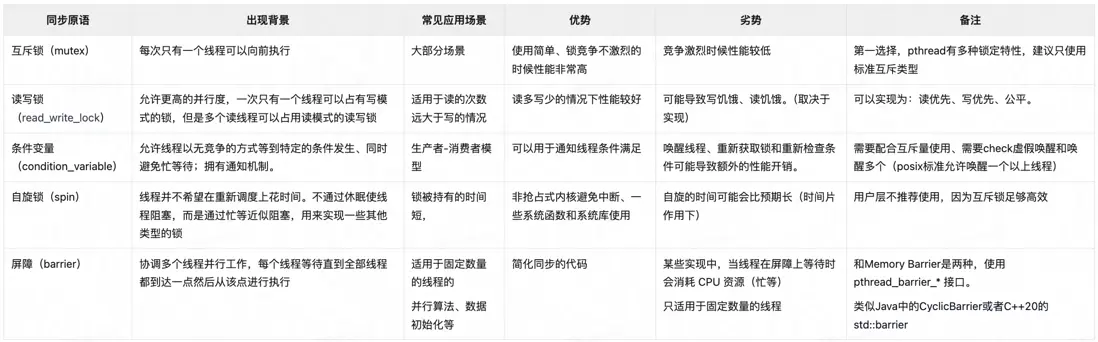
由於linux下線程和進程本質都是LWP,那麼進程間通信使用的IPC(管道、FIFO、消息隊列、信號量)線程間也可以使用,也可以達到相同的作用。 但是由於IPC資源在進程退出時不會清理(因為它是系統資源),因此不建議使用。
以下是一些非鎖但是也能實現線程安全或者部分線程安全的常見做法:
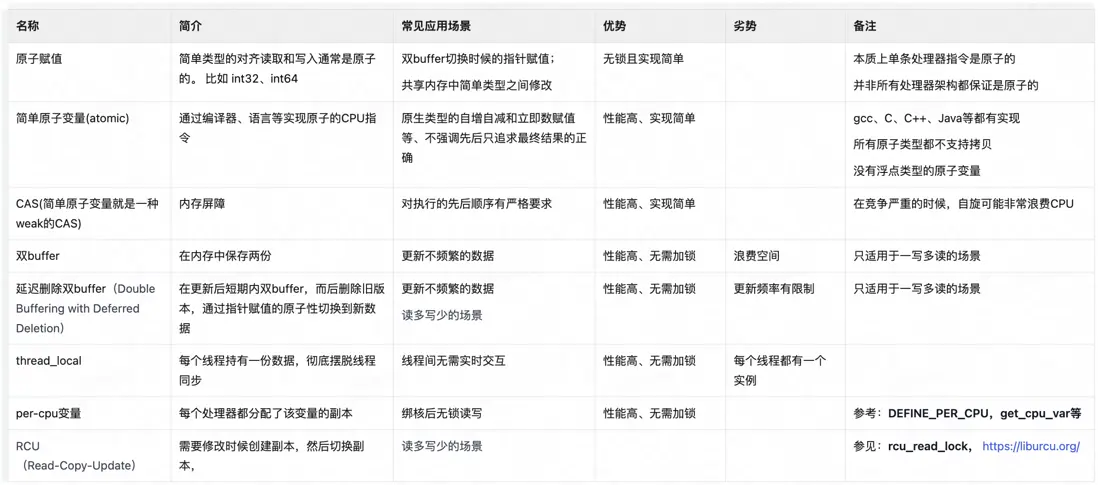
可以看到,上面很多做法都是採用了副本,儘量避免在 thread 中間共享數據。最快的同步就是沒同步(The fastest synchronization of all is the kind that never takes place),Share nothing is best。
| 在美團公眾號菜單欄對話框回覆【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明“內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至tech@meituan.com申請授權。






