

NLP基本介紹
NLP(Natural Language Processing)是一種人工智能和語言學領域的交叉學科,旨在讓計算機能夠理解和生成人類的語言,實現人機之間的自然交流。
其具體定義為:自然語言處理(Natural Language Processing, NLP)是利用計算機科學、人工智能和語言學的理論和方法,研究如何讓計算機能夠“聽懂”人類的語言,並實現與之無障礙交流的技術。
其目標為:使計算機能夠理解、處理、生成和模擬人類語言,從而執行語言翻譯、情感分析、文本摘要等任務。
NLP的常見應用場景
自然語言處理(NLP)技術是人工智能領域的一個重要分支,它致力於讓計算機能夠理解和生成人類語言。以下是一些常見的NLP應用場景及其具體描述和示例:
- 機器翻譯:機器翻譯是NLP技術中最為人所熟知的場景之一。通過將輸入的源語言文本自動翻譯成另一種語言的文本,NLP技術極大地促進了國際交流、商務合作和跨文化溝通。例如,百度翻譯、Google翻譯等在線翻譯工具就是基於NLP技術開發的,它們能夠實現多種語言之間的實時翻譯。
- 情感分析:情感分析是NLP的一個子領域,它涉及識別和分類文本中的主觀信息,如情感傾向(積極、消極或中性)。這一技術在市場研究、品牌監控和社交媒體分析中尤為重要。企業可以利用情感分析來了解消費者對其產品或服務的看法,從而及時調整市場策略和改進產品。
- 聊天機器人與虛擬助手:聊天機器人和虛擬助手是NLP技術的又一重要應用。這些系統能夠理解用户的自然語言輸入,並提供相應的回答或執行任務。在客户服務、在線購物和個人助理等領域,聊天機器人已經得到了廣泛應用。例如,Siri、Alexa、Google Assistant等智能語音助手就是基於NLP技術開發的,它們能夠與用户進行自然語言交流,提供各種便捷服務。
- 文本摘要與內容提取:NLP技術還可以自動生成文本的摘要,這對於快速獲取大量信息的概要非常有用。文本摘要在新聞聚合、研究論文閲讀和企業報告中具有極高的實用價值。通過自動提煉文檔核心信息,NLP技術幫助用户快速抓住文章的主旨和要點,提高工作效率。
- 智能客服:智能客服是一個廣泛應用NLP技術的領域。利用NLP技術,智能客服系統能夠理解客户提出的問題,並提供準確的解答,從而提高了客服質量。這些系統還可以實時處理大量客户查詢,降低了等待時間,增加了效率。
- 搜索引擎優化:在搜索引擎領域,NLP技術扮演着至關重要的角色。通過分析用户的查詢意圖和網頁內容,NLP技術能夠更準確地匹配搜索詞和網頁內容,從而提供更為相關和精準的搜索結果。這種技術的應用不僅提高了搜索效率,還極大地提升了用户體驗。
- 醫療健康與法律領域:在醫療健康領域,NLP技術被用於電子健康記錄的分析、臨牀決策支持和患者交流。通過自動提取病歷文檔中的關鍵信息,NLP技術為醫生提供了更為全面和準確的診斷依據。在法律領域,NLP技術則被用來分析法律文件、合同和案例,以輔助法律專業人士進行研究和決策。
總之,隨着技術的不斷進步和應用領域的不斷拓展,NLP將在未來的人工智能領域中發揮更加重要的作用,為人類社會帶來更多的便利和創新。
NLP領域數據類型
自然語言領域的核心數據是序列數據,這是一種在樣本與樣本之間存在特定順序、且這種特定順序不能被輕易修改的數據。
在之前提到的機器學習和普通深度神經網絡裏,可使用的數據是二維表,在普通的二維表中,樣本與樣本之間是相互獨立的,一個樣本及其特徵對應了唯一的標籤。如下表所示,無論先訓練1號樣本還是先訓練7號樣本,都不會從本質上改變數據的含義,很多時候也不會改變算法對數據的理解和學習結果。
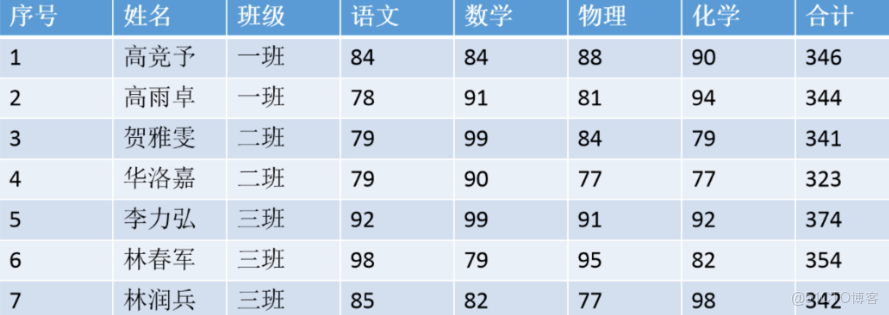
但序列數據則不然,對序列數據來説,一旦調換樣本順序或樣本發生缺失,數據的含義就會發生巨大變化。最典型的序列數據有以下幾種類型:
1、文本數據(Text Data):文本數據中的樣本的“特定順序”是語義的順序,也就是詞與詞、句子與句子、段落與段落之間的順序。在語義環境中,詞語順序的變化或詞語的缺失可能會徹底改變語義,例如——
改變順序:事半功倍和事倍功半
樣本缺失(對文本來説特指上下文缺失):小貓睡在毛毯上,因為它很____。當我們在橫線上填上不同的詞(暖/冷)時,句子的含義會發生變化。
2、音頻數據(Audio Data):音頻數據大部分時候是文本數據的聲音信號,此時音頻數據中的“特定順序”也是語義的順序;當然,音頻數據中的順序也可能是音符的順序,試想你將一首歌的旋律全部打亂再重新播放,那整首歌的旋律和聽感就會完全喪失。
3、視頻數據(Video Data):你知道動畫是由一張張原畫構成的嗎?視頻數據本質就是由一幀幀圖像構成的,因此視頻數據是圖像按照特定順序排列後構成的數據。和音頻數據類似,如果將動畫或電影中的畫面順序打亂再重新播放,那沒有任何人能夠理解視頻的內容。
因此在處理序列數據時,不僅要讓算法理解每一個樣本,還需要讓算法學習到樣本與樣本之間的聯繫。
序列數據的結構
序列數據的概念很容易理解,但奇妙的是,現實中的序列數據可以是二、三、四、五任意維度,只要給原始的數據加上“時間順序”或“位置順序”,任意數據都可以化身為序列數據。
序列數據舉例説明:
1、二維時間序列
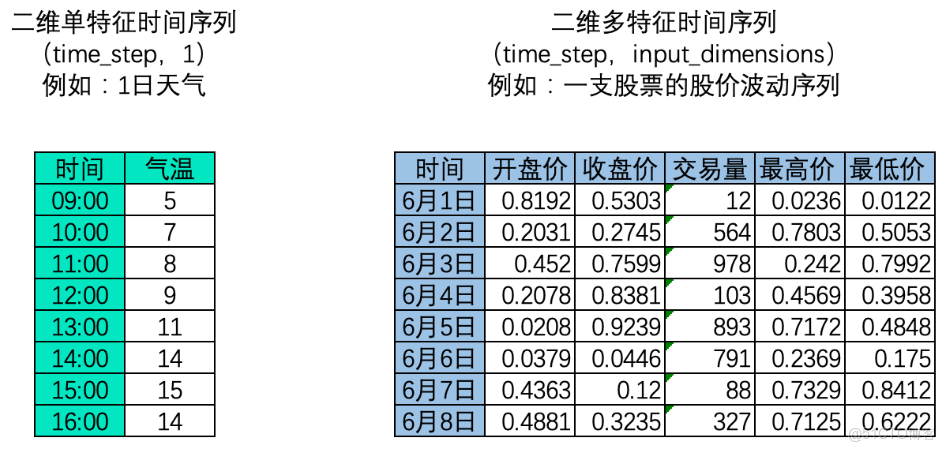
ps:只以舉例説明,知道股市的週六週日為非交易日
時間序列中,樣本與樣本之間的順序是時間順序,因此每個樣本是一個時間點,時間順序也就是time_step這一維度上的順序。這種順序在自然語言處理領域叫做“時間步”(time_step),也被叫做“序列長度”,這正是我們要求算法必須去學習的順序。在時間序列數據中,時間點可以是任意時間單位(分鐘、小時、天),但時間點與時間點之間的間隔必須是一致的。
2、三維時間序列
在NLP領域中,我們常常一次性處理多個時間序列,如下圖所示,我們可以一次性處理多支股票的股價波動序列。
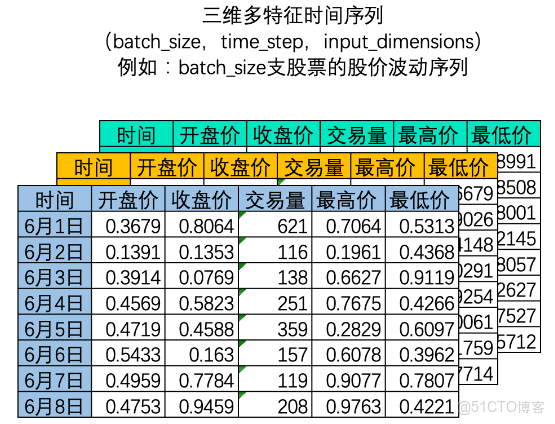
此三維矩陣中,batch_size是樣本量,也就是一共有多少個二維時間序列表單。因為深度學習算法會同時處理多個內在邏輯相同的時間序列。其中time_step和input_dimension決定了一個時間序列的序列長度和特徵量,而batch_size決定了整個數據集中一共有多少個二維時間序列表單。這些二維表單堆疊在一起,構成深度學習算法輸入所必備的三維時間序列。
3、二維文字序列:
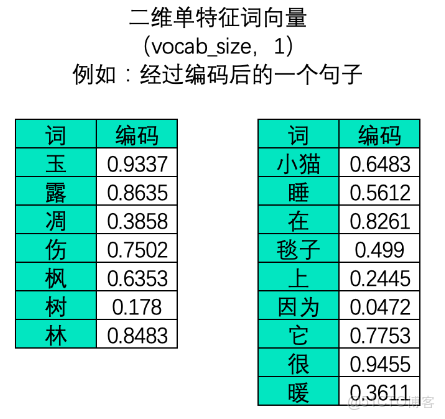
在文字數據中,樣本與樣本之間的聯繫大部分時候是詞與詞、字與字之間的聯繫,因此在文字序列中每個樣本是一個單詞或一個字(對英文來説大部分時候是一個單詞,偶爾也可以是一個字母),故而在中文文字數據中,一張二維表往往是一個句子或一段話。此時,不能夠打亂順序的維度是vocab_size,它代表了一個句子 /一段話中的字詞總數量。一個句子或一段話越長,vocab_size也就會越大,因此這一維度的作用與時間序列中的time_step一致,vocab_size在許多時候也被稱之為是序列長度(sequence_length)。同樣,vocab_size這一維度上的順序就是算法需要學習的順序。
embedding詞向量簡易理解
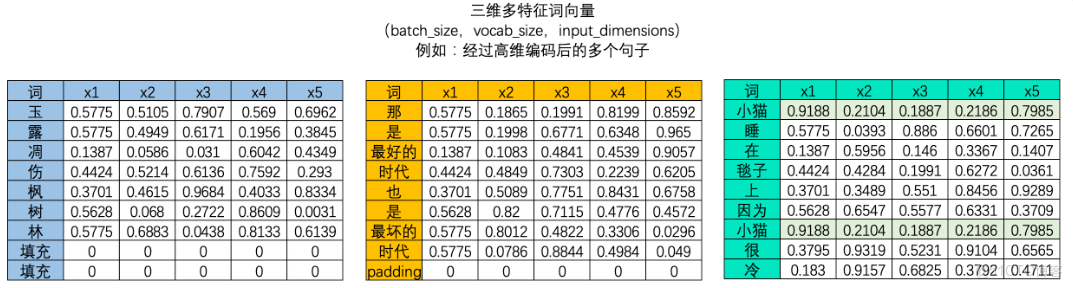
文字序列是不能直接放入算法進行運行的,大模型是不能直接處理文字,必須要編碼成數字數據才能供算法學習,因此在NLP領域中我們大概率會將文字數據進行編碼。編碼的方式有很多種,但無一例外的,文字編碼的本質是用單一數字或一串數字的組合去代表某個字/詞,在同一套規則下,同一個字會被編碼為同樣的序列或同樣的數字,而使用一個數字還是一串數字則可以由算法工程師自行決定。下例是對句子分別進行embedding編碼和獨熱編碼後產生的二維表單:
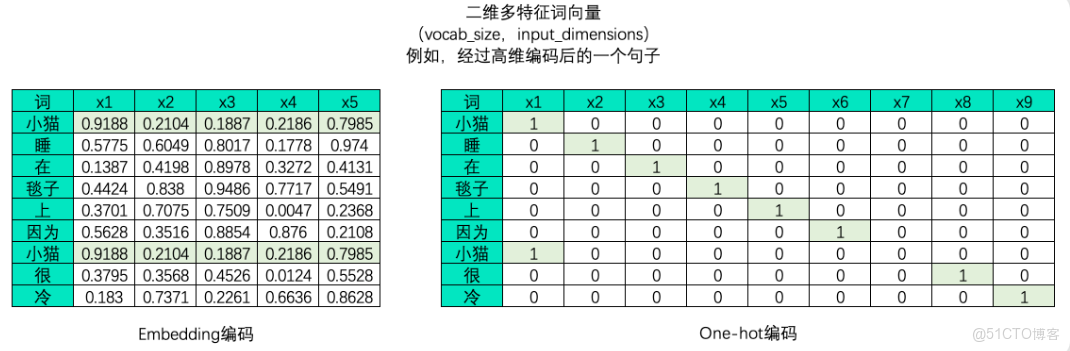
大部分時候,我們需要學習的肯定不止一個句子,當每個句子被編碼成矩陣後,就會構成高維的多特徵詞向量。由於在實際訓練時,所有句子或段落長度都一致的可能性太小(即所有句子的vocab_size都一致的可能性太小),因此我們往往為短句子進行填充、或將長句子進行裁剪,讓所有的特徵詞向量保持在同樣的維度。
繼續假設我們有一句話,叫“公主很漂亮”,如果我們使用one-hot編碼,可能得到的編碼如下:
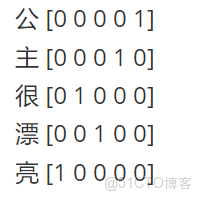
若如此做,我們都能將任何字在一個一維的數組裏用0和1表示出來,並且不同的字絕對不一樣,以致於一點重複都沒有,表達本徵的能力極強。但是,因為其完全獨立,其劣勢就出來了。表達關聯特徵的能力幾乎為0!!!舉個例子,我們又有一句話 “王妃很漂亮” 那麼在這基礎上,我們可以把這句話表示為
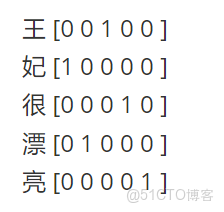
目前對於大模型而言,無法將兩者再關聯一起。但從表達上而言,王妃跟公主其實是有很大關係的,公主是國王的女兒,王妃是國王的妃子,可以從“國王”這個詞進行關聯上;公主住在宮裏,王妃住在宮裏,可以從“宮裏”這個詞關聯上;公主是女的,王妃也是女的,可以從“女”這個字關聯上。
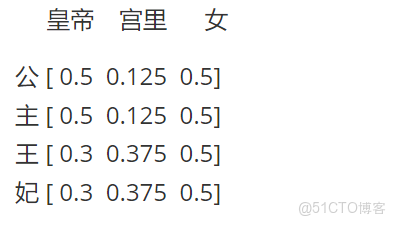
既然,通過剛才的假設關聯,我們關聯出了“皇帝”、“宮裏”和“女”三個詞,那我們嘗試這麼去定義公主和王妃
公主一定是皇帝的女兒,我們假設她跟皇帝的關係相似度為1.0;公主從一出生就住在宮裏,直到20歲才嫁到府上,活了80歲,我們假設她跟宮裏的關係相似度為0.25;公主一定是女的,跟女的關係相似度為1.0;
王妃是皇帝的妃子,沒有親緣關係,但是有存在着某種關係,我們就假設她跟皇帝的關係相似度為0.6吧;妃子從20歲就住在宮裏,活了80歲,我們假設她跟宮裏的關係相似度為0.75;王妃一定是女的,跟女的關係相似度為1.0;於是公主王妃四個字我們可以這麼表示:
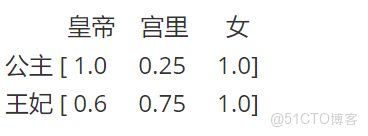
這樣我們就把公主和王妃兩個詞,跟皇帝、宮裏、女這幾個字(特徵)關聯起來了,我們可以認為:

或者我們假設每個詞的每個字都是對等(注意:只是假設,為了方便解釋),則公主(2個字)和王妃(2個字)的表示為:
這樣,我們就把一些詞甚至一個字,用三個特徵給表徵出來了。於是乎,我們把文字的one-hot編碼,從稀疏態變成了密集態,並且讓相互獨立向量變成了有內在聯繫的關係向量。
所以,embedding層做了個什麼呢?它把我們的稀疏矩陣,通過某種變換將其變成了一個密集矩陣,這個密集矩陣用了N(例子中N=3,皇帝、公里和女)個特徵來表徵所有的文字,在這個密集矩陣中,表象上代表着密集矩陣跟單個字的一一對應關係,實際上還藴含了大量的字與字之間,詞與詞之間甚至句子與句子之間的內在關係。他們之間的關係,用的是嵌入層學習來的參數進行表徵。從稀疏矩陣到密集矩陣的過程,叫做embedding。
三維文字序列
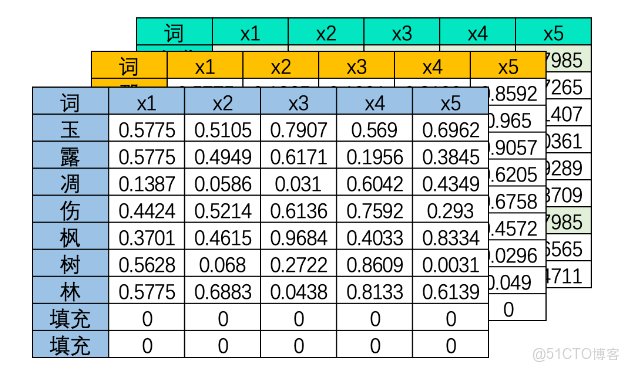
上圖是一個三維矩陣,其中batch_size是樣本量,也就是一共有多少個二維文字序列表單。
RNN循環神經網絡
RNN概述
循環神經網絡(Recurrent Neural Network)是自然語言處理領域的入門級深度學習算法,也是序列數據處理方法的經典代表作,它開創了“記憶”方式、讓神經網絡可以學習樣本之間的關聯、它可以處理時間、文字、音頻數據,也可以執行NLP領域最為經典的情感分析、機器翻譯等工作。
RNN基本架構
如果你去找尋網絡上的各種資源,你會驚訝地發現循環神經網絡有各種各樣複雜的公式表示和圖像表示方法。然而,光從網絡架構來説,循環神經網絡與深度神經網絡是完全一致的。
首先,循環神經網絡由輸入層、隱藏層和輸出層構成,輸入層的神經元個數由輸入數據的特徵數量決定,隱藏層數量和隱藏層上神經元的個數都可自己設置,而輸出層的神經元數量則需要根據輸出的任務目標進行設置。假如,現在我們將每個單詞都編碼成了5個特徵構成的詞向量,因此輸入層就會需要5個神經元,我們將該文字數據輸入循環神經網絡執行三分類的“情感分類”任務(三分類分別是[積極,消極,中性]),那輸出層就會需要三個神經元。假設有一個隱藏層,而隱藏層上有2個神經元,一個最為簡單的循環網絡的網絡結構如下:
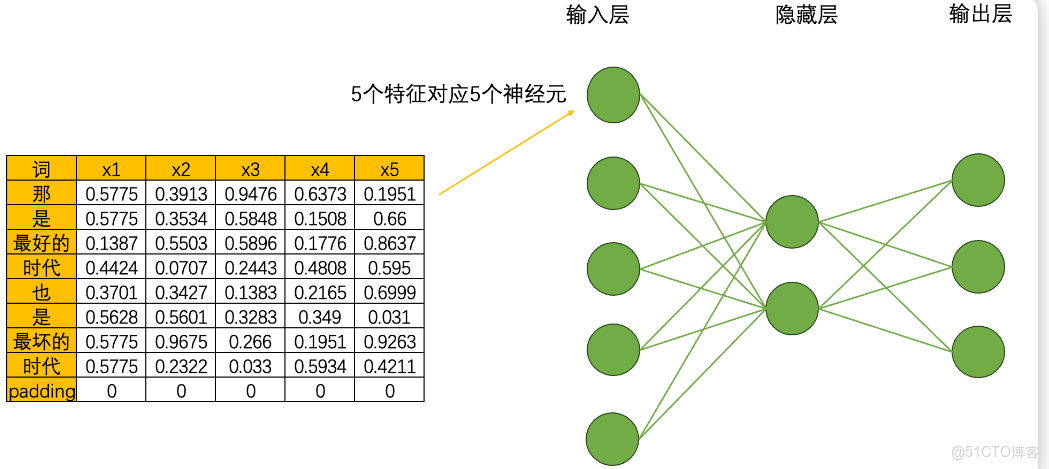
在這個結構中,激活函數的設置、神經元的連接方式等都與深度神經網絡一致,因此循環神經網絡在網絡構建方面沒有太多可以深究的內容,循環網絡真正精彩的地方在於其創造了全新的數據流。
RNN數據流
當我們將數據輸入到循環神經網絡時,一個神經元一次性只會處理一個單詞的一個數據,5個神經元會覆蓋當前單詞的5個特徵,在一次正向傳播中,循環神經網絡只會接觸到一個單詞的全部信息。
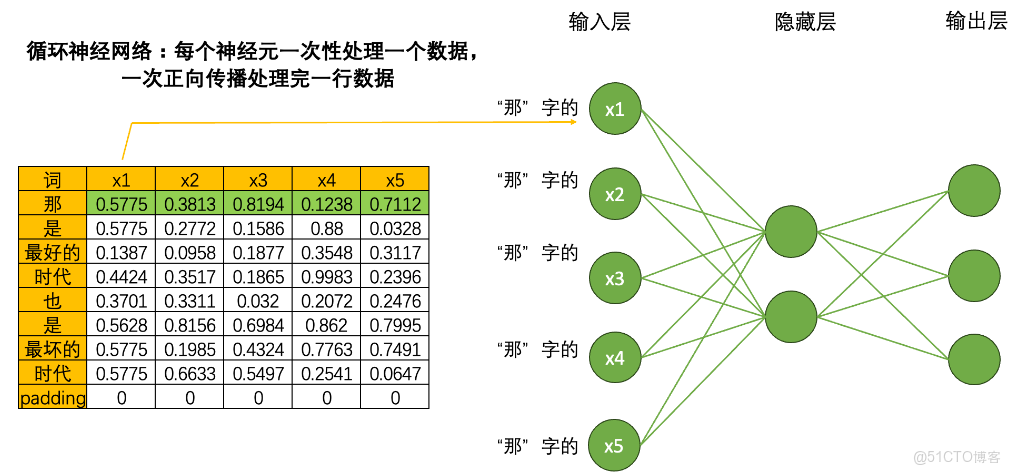
由此得知,這一句話若要用其訓練,就要一行一行處理數據。雖然非常顛覆神經網絡當中對效率的根本追求,但循環神經網絡是一個單詞、一個單詞處理文本數據,一個時間點、一個時間點處理時序數據的。具體過程如下:



如果一次正向傳播只處理一行數據,那對於結構為(vocab_size,input_dimension)的文字數據來説,就需要在同一個網絡上進行vocab_size次正向傳播。同樣的,對於結構為(time_step,input_dimension)的時間序列數據來説,就需要在同一個網絡上進行time_step次正向傳播。在循環神經網絡中,vocab_size和time_step這個維度可以統稱為sequence_length,同時還有一個更常見的名字叫做時間步,對任意數據來説,循環神經網絡都需要進行時間步次正向傳播,而每個時間步上是一個單詞或一個時間點的數據。
基於這樣的數據流設置,循環神經網絡構建了自己的靈魂結構:循環數據流。在多次進行正向傳播的過程中,循環神經網絡會將每個單詞的信息向下傳遞給下一個單詞,從而讓網絡在處理下一個單詞時還能夠“記得”上一個單詞的信息。循環網絡在不同時間步的隱藏層之間建立了鏈接。
如下圖所示,在Tt-1時間步上時,循環網絡處理了一個單詞,此時隱藏層上輸出的中間變量Ht-1會走向兩條數據流,一條數據流是繼續向輸出層的方向正向傳播,另一條則流向了下一個時間步的隱藏層。在T時間步時,隱藏層會結合當前正向傳播的輸入層傳入的Xt和上個時間步的隱藏層傳來的中間變量Ht-1共同計算當前隱藏層的輸出Ht。如此,Ht當中就包含了上一個單詞的信息。
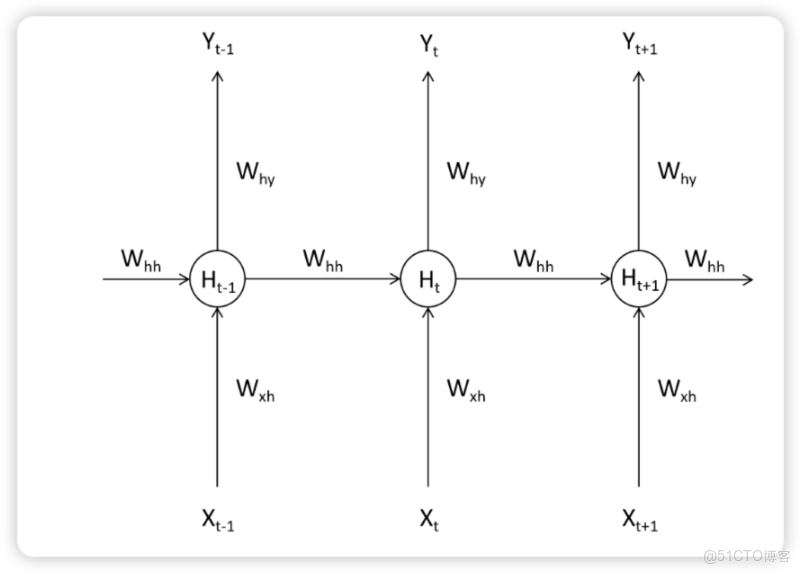
假設當前時間步是t-1,當前時間步上的輸入特徵為𝑋𝑡−1,輸入層與隱藏層之間的的權重為𝑊xh,隱藏層與輸出層之間的權重為𝑊hy,當𝑋𝑡−1進入神經網絡後時,權重𝑊xh將與輸入信息𝑋𝑡−1共同計算,構成中間變量𝐻𝑡−1,這一中間變量被稱之為是“隱藏狀態”,代表在隱藏層上輸出的值。
在深度神經網絡中,𝐻𝑡−1將會被傳導向輸出層,與𝑤hy共同計算後構成輸出層上的輸出,但在循環神經網絡中,𝐻𝑡−1除了被傳導向輸出層之外,還會被傳導向下一個時間步,與𝑋t一起,共同構建𝐻t。
使用架構圖表示,則可表示如下:
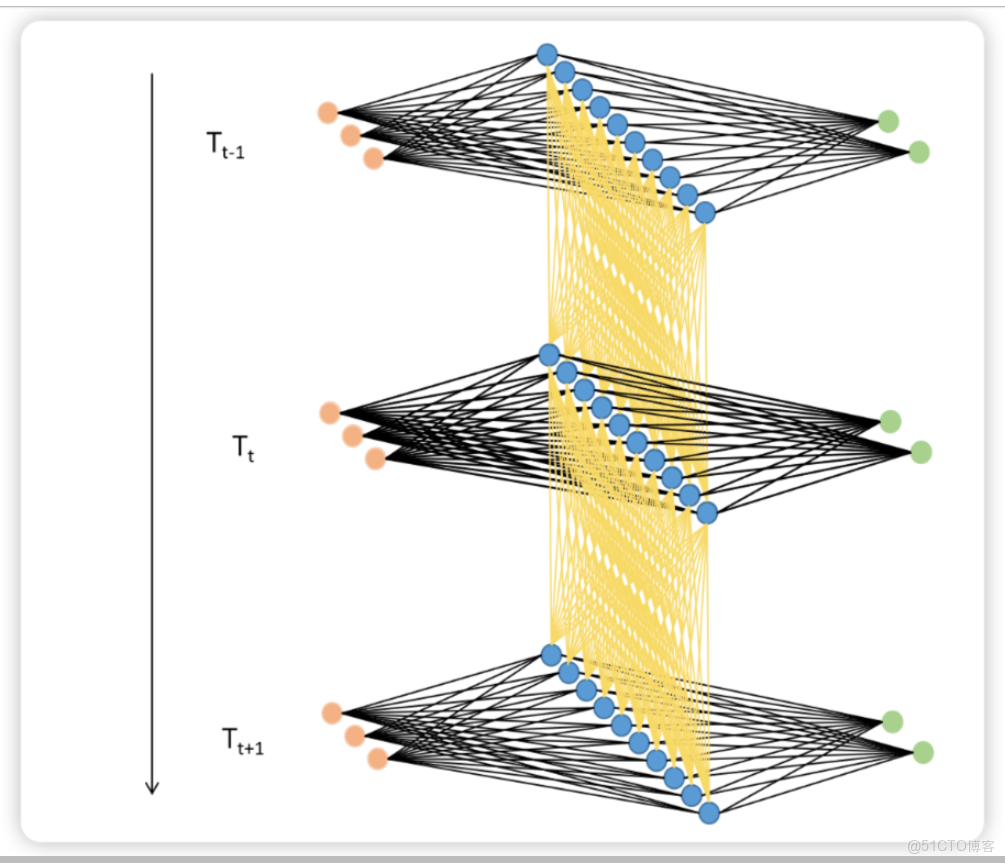
利用這種方式,只要進行vocal_size次向前傳播,並且每次都將上一個時間步中隱藏層上誕生的中間變量傳遞給下一個時間步的隱藏層,整個網絡就能在全部的正向傳播完成後獲得整個句子上的全部信息。在這個過程中,我們在同一個網絡上不斷運行正向傳播,此過程在神經網絡結構上是循環,在數學邏輯上是遞歸,這也是循環神經網絡名稱的由來。
RNN的權值共享
現在已經知道循環網絡的數據流和基本結構了,但我們還面臨一個巨大的問題——效率。剛才我們以一張表為例講解了循環神經網絡的迭代過程,但循環網絡在實際應用時可能面臨batch_size張表單,如果每張表單都需要一行一行進行向前傳播的話,那循環神經網絡運行一次需要(batch_size * sequence_length)次向前傳播,這樣整個網絡的運行效率必然是非常非常低的。
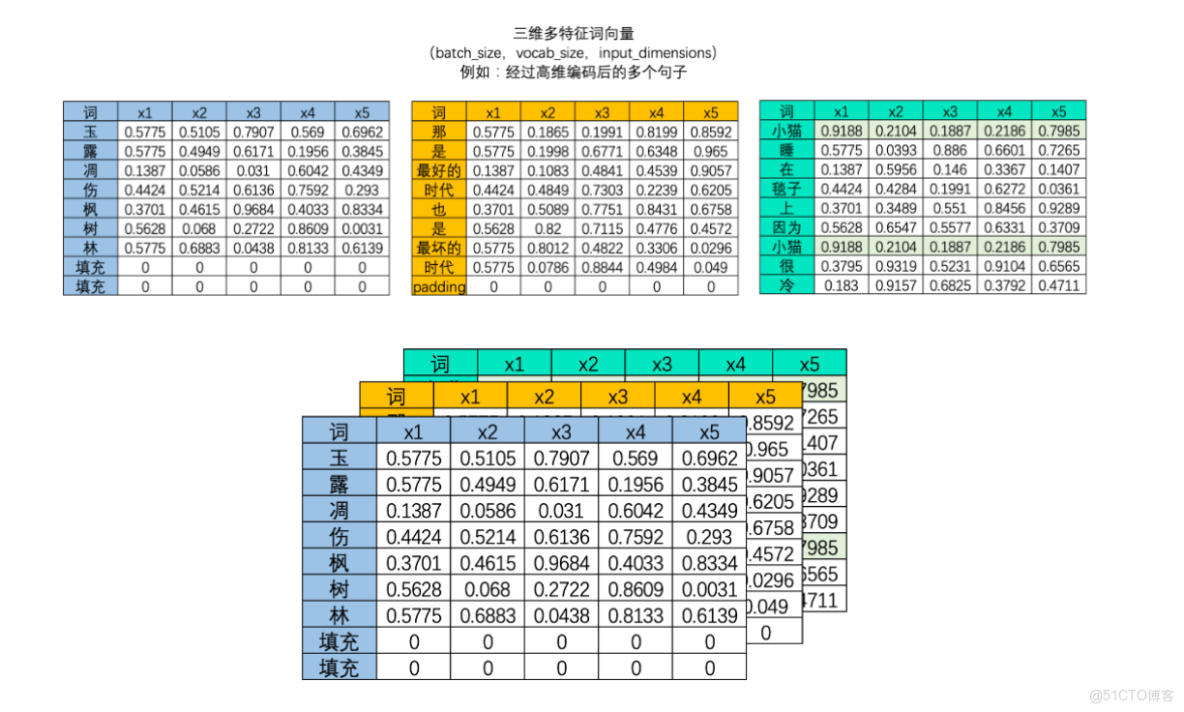
事實上這個問題並不存在。在現實中使用循環神經網絡的時候,我們所使用的輸入數據結構往往是三維時間或三維文字數據,也就是説數據中大概率會包括不止一張時序二維表、會包括不止一個句子或一個段落。之前我們提到過,循環神經網絡要順利運行的前提是所有的句子/時間序列被處理成同等的長度,因此實際上每張二維表需要循環的時間步數量是相等的,因此在實際訓練的時候循環神經網絡是會一次性將所有的batch_size張二維表的第一行數據都放入神經元進行處理,故而RNN並不需要對每張表單一一處理,而是對全部表單的每一行進行一一處理,所以最終循環神經網絡只會進行sequence_length次向前傳播,所有的batch是共享權重的。
如果將三維數據看作是一個立方體,那循環神經網絡就是一次性處理位於最上層的一整個平面的數據,因此循環神經網絡一次性處理的數據結構與深度神經網絡一樣都是二維的,只不過這個二維數據不是(vocal_size,input_dimension)結構,而是(batch_size,input_dimension)結構罷了。
通俗理解:三個錶行數不一致,先將三個錶行數統一,對於行數不足的表,填充與行數最多的表一致。之後數據餵給大模型訓練時,是三張表的第一行一起餵給RNN網絡,直到循環至最後一行。