
背景
我們的日常使用大模型,就像是在不同模型間打補丁:“這個模型會看圖,但不會講故事;那個模型能生成視頻,但不懂視頻在表達什麼。” 於是乎,大致像這樣,想用圖像模型,就得跑去找midjourney;想做視頻模型,又得等 Sora;想讓模型理解視頻劇情,還得靠那些半懂不懂的“視覺語言拼接模型”;想讓模型讀情緒,甚至還得給它加一堆“情緒標籤的模板提示詞”。
而就在昨天,我看完百度文心 5.0 的發佈會,突然有種久違的感覺:——國產大模型的世界觀,好像真的變了。

文心 5.0 :“都別吵,你們其實是同一種 token”
發展
我饒有興致的去搜了下文心5.0的相關“實力”,原來在 11 月 8 日的 LMArena 更新中,全新的 ERNIE-5.0-Preview-1022 排在文本榜全球並列第二的位置,在國內模型中排名第一,在創意寫作、複雜長問題理解、指令遵循等維度都有較明顯的優勢,整體分數超過了多款國內外的主流模型。
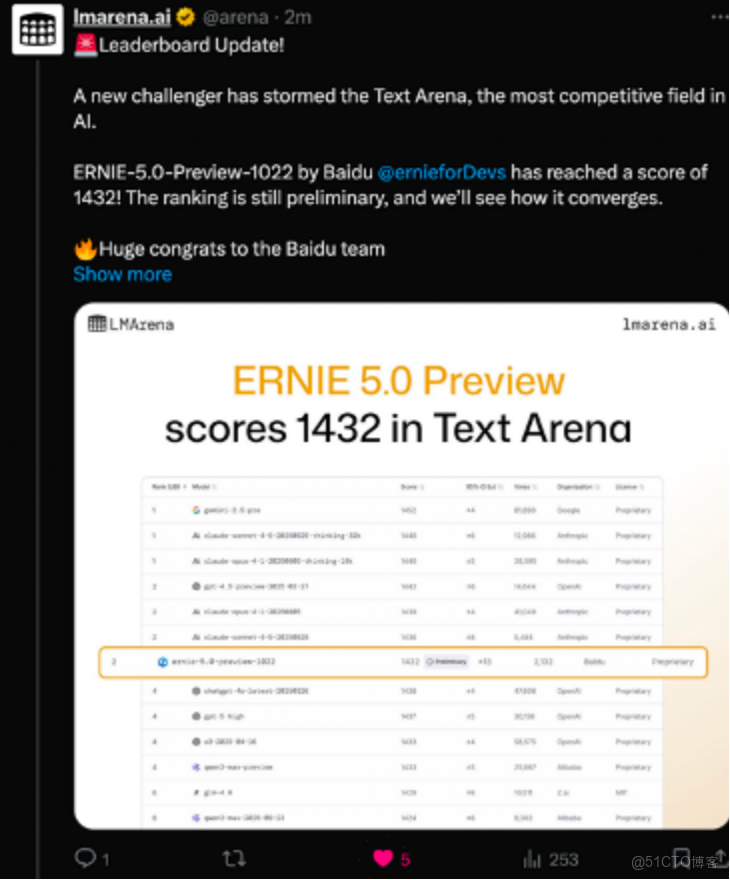
媒體也做了不少實測。11 月 12 日,百度開源了多模態思考模型 ERNIE-4.5-VL-28B-A3B-Thinking,這個模型在 HuggingFace 多模態趨勢榜上線 24 小時就升至全球第一。公開基準顯示,在多模態理解和複雜推理任務上,其性能在僅 3B 激活參數的情況下已經接近 GPT-5-High 和 Gemini-2.5-Pro。這個模型引入了“圖像思考”(Thinking with Images)的方法,使模型能夠在圖像層面構建更具結構性的推理鏈路,同時提升場景定位、細節捕捉與指令遵循的穩定性。因此在許多需要多模態統一理解的任務中,它的表現更接近人類的處理方式。
整體來看,從文本到多模態,這一系列數據至少説明:文心 5.0 的能力已經不再停留在發佈會描述,而是在公開評測中有相對穩定、可復現的表現。
實測
eg1
我專門讓文心 5.0 生成了一張“馬斯克和朱迪警官握手”的畫面,想看看它在構圖和細節上到底理解了多少“人類場面話”。
有意思的是,它並不是隨便拼出兩個站在一起的人,而是把整個社交場景都一起建出來了:馬斯克的微笑是收着的,像是在釋放善意;朱迪警官的握手姿態偏正式,身體保持直立,和馬斯克之間留出一個剛剛好的社交距離。背景不是雜亂的街景,而是乾淨、偏官方的佈景,燈光集中在兩人身上,旁邊略微虛化,明顯是在強調“公開場合的禮貌互動”這種氛圍。
從這張“生成出來的合影”裏,你能感覺到的是:文心 5.0 不只是會把“兩個人 + 握手”拼在一起,而是對“這應該是什麼場合、兩個人應當呈現什麼狀態”有一套自己的判斷。它畫出來的不是一張靜態姿勢圖,而是一種關係感——這已經超出“我看懂了物體”,更接近“我理解了場面”。
eg2
第二個測試我選了一個更偏“結構推理”的場景:讓文心 5.0 去生成一段“太陽系 3D 運行模擬”的小動畫,看它能不能不靠死記硬背,而是真正理解軌道、光影、節奏這些物理關係。結果比我預期的要好:

它生成的不是那種“行星繞着太陽轉一圈就完事”的廉價演示,而是真的把軌道速度的差異、光照方向的變化、遮擋關係的前後順序統統兑到了畫面裏。內行星轉得快、外行星轉得慢,明暗分界線和光源方向一致,甚至連一些行星的輕微橢圓偏心都表現得挺自然。更關鍵的是,它不會把“軌道運動”做成機械循環,而是通過視角變化、光照過渡,讓你感覺到這是一套真正的天體運行系統,而不是簡單堆模型貼圖。這種能力背後依賴的是模型對動態結構 + 物理一致性 + 時序節奏的統一理解。
eg3
後一個測試,是我最想看的——影視劇情節、時序與情緒的綜合分析。我直接讓它基於無間道“”指定片段重建一個“帶敍事理解”的畫面,看它的鏡頭語言、人物關係、節奏把握會不會生硬。

傳統模型在這種任務下幾乎只會描述動作:誰轉頭、誰説話、誰沉默。但文心 5.0 的生成結果明顯更像是“帶着理解在畫”。人物的停頓不是被誤畫成僵直的姿勢,而是處理成“猶豫”“壓抑”“欲言又止”的身體狀態;鏡頭的遠近關係也不是隨機挑選,而是和角色當下的心理距離保持一致;背景裏的光影變化、色調微差、空間層次也都跟劇情情緒走向對得上。有意思的地方在於,它並不只是在“復現畫面”,而是在試圖表達:在這一段情節裏,誰比誰更緊張、誰比誰更主動、誰在隱藏情緒、誰在試探對方。這是以前的拼接式多模態模型完全做不到的維度。那種“不是描述情緒,而是畫出情緒”的體驗,讓我第一次意識到:文心 5.0 的全模態統一推理,已經能觸碰到一種接近敍事語言的東西。
小結
所以,我感受到:文心 5.0 的推理鏈是統一的,它理解世界的方式是一種:token,而不是多種:文字、圖片、音視頻。不需要補丁、橋接、投影和“你説完我接着説”的拼裝邏輯。信息不再丟、推理不再斷、情緒不再淺表、敍事不再碎片。
還有,更微妙的變化在於:當模態統一之後,智能體能力會自然變強。因為一個能同時理解場景、動作、情緒、語言的模型,它去執行計劃時不會突然“忘記前因後果”。你讓它分析劇情,它能分析人物意圖;讓它生成腳本,它能把動作、表情、語氣、鏡頭邏輯一起規劃好。這種“行為一致性”是老式多模態模型無法提供的。
我猜測,如果未來的大模型架構真的會進入 2.0 時代,可能就是文心 5.0 這樣的全模態架構。