1.邏輯迴歸相比線性迴歸,有何異同?
區別:
- 線性迴歸假設響應變量服從正態分佈,邏輯迴歸假設響應變量服從伯努利分佈
- 線性迴歸優化的目標函數是均方差(最小二乘法),而邏輯迴歸優化的是似然函數(交叉熵)
- 線性迴歸要求自變量與因變量呈線性關係,而邏輯迴歸研究的是因變量取值的概率與自變量的概率
- 邏輯迴歸處理的是分類問題,線性迴歸處理的是迴歸問題,這也導致了兩個模型的取值範圍不同:0-1和實數域
聯繫:
- 兩個都是線性模型,線性迴歸是普通線性模型,邏輯迴歸是廣義線性模型
- 表達形式上,邏輯迴歸是線性迴歸套上了一個Sigmoid函數



5.邏輯迴歸處理多標籤分類問題時,一般怎麼做?
第一種方式:從類別入手
- OVO (one vs one)
某個分類算法有N類,將某一類和另一類比較作為二分類問題,總共可分為種不同的二分類模型,給定一個新的樣本點,求出每種二分類對應的概率,概率最高的一類作為新樣本的預測結果。
- OVR(One vs Rest)
某個分類算法有N類,將某一類和剩餘的類比較作為二分類問題,N個類別進行N次分類,得到N個二分類模型,給定一個新的樣本點,求出每種二分類對應的概率,概率最高的一類作為新樣本的預測結果。
第二種方法:從算法入手
第二種方式是修改logistic迴歸的損失函數,讓其適應多分類問題。這個損失函數不再籠統地只考慮二分類非1就0的損失,而是具體考慮每個樣本標記的損失。這種方法叫做softmax迴歸,即logistic迴歸的多分類版本。
附加題
- LSTM為什麼能緩解梯度消失/爆炸的問題?
- 首先我們來看兩個模塊:加法門與乘法門
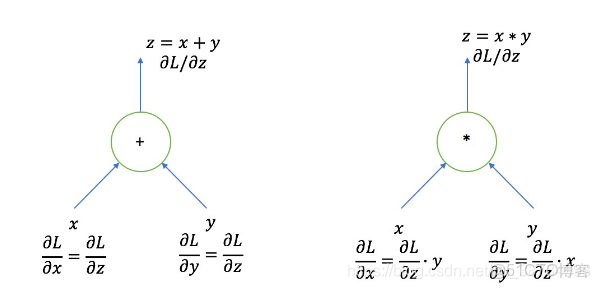
在計算圖中,前向是輸入信息到輸出的傳遞過程,反向是計算梯度,也就是根據輸出的cost來對變量進行調整的過程。上圖裏第一行表示變量,即前向傳播的信息,第二行表示損失函數對該變量的導數,也即調整用的信息。
加法門:從前向的觀點看,是信息的加法,x和y同權地反應到了輸出z中。從反向的觀點看,z的調整信息(即
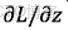
)不多不少地傳播給了x和y的調整信息。
乘法門:從前向的觀點看,是信息的乘法,因此其中一個變量,比如y可以用來控制另一個變量,比如x的表達。y如果是0,那麼x無論是什麼值,輸出z都是0,因此信息完全被阻斷;y如果是1,那麼x的值會直接拷貝到輸出,因此信息被完整表達。y如果是其他值,則是帶scaling的信息表達,這種表達可能在網絡的後續部分與其他不同來源、不同scaling的信息混合,作為最終表達。從反向的觀點看,乘法門具有調整信息的阻斷/放行的作用:y如果是0,由於x的信息被阻斷,因此輸出z的調整完全不應該被反應到x上(即x此時不對輸出負責)。類似的,若y非零,那麼調整信息會被傳播到x上,只是帶有y這個scaling因子,而且y的符號也影響了最終的調整方向。
於是簡化來看,加法門可以認為是兩組信息的疊加,乘法門可以看做一組控制信號對另一組信息的控制。
現在來考慮序列的問題。給定一組輸入序列,我們考慮隱狀態轉移的序列。為了把輸入序列的信息反映到隱狀態裏,一個自然的選擇是利用加法門不斷把輸入向量加到隱狀態裏。而最簡單的輸出,則是直接把隱狀態輸出。於是我們就得到下面這個最簡單的模型:

如果輸入I在每一步的scale是O(1)的,那麼隱狀態S的增長就是O(T)的,因此不會爆炸也不會消散。且不論最終得到的隱狀態是否靠譜,至少隱狀態含有了過去所有輸入的信息,因此任何輸入至少是能在隱狀態和輸出力表達的,所以這也可以算作一個基本的序列模型。但是這種結構會出現梯度爆炸或消失。
那麼如何改進該模型?可以有以下幾個出發點:
1. 每一個輸入可能並不應該完全同權地被表達,因此我們可以在輸入端加入一個乘法門以及一個控制信號,來限制某些時刻輸入的表達。
2. 同理,每一個輸出也可能不應該完全同權的被表達,甚至有些輸出就不應該表達、傳輸到之後的網絡裏。因此輸出也可以加入一個乘法門以及一個控制信號,來限制某些時刻輸出的表達。
3. 有些時候狀態本身也應該被重置,所以在狀態到狀態的通路直接我們也可以加入一個乘法門和一個控制信號,來限制某一時刻狀態到下一時刻狀態的表達。
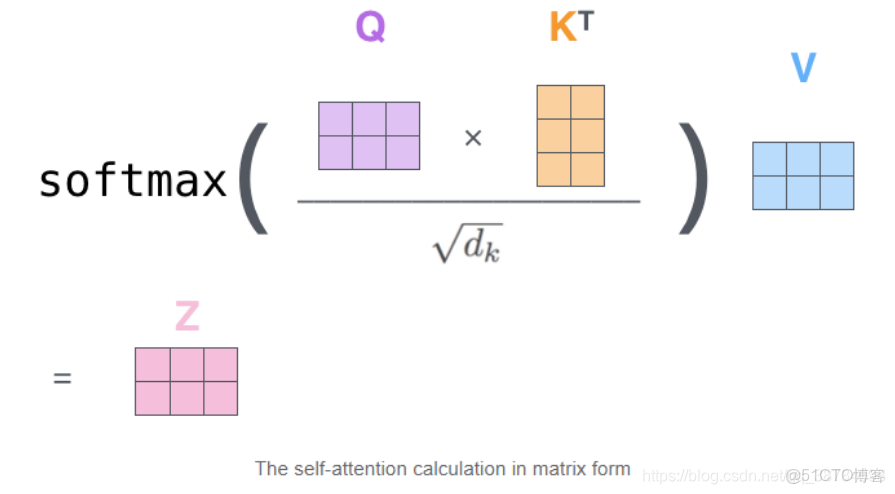
- Attention中self-attention的時間複雜度
Self-Attention 時間複雜度:這裏,n 是序列的長度,d是 embedding 的維度,不考慮 batch 維。Self-Attention 包括三個步驟:相似度計算,softmax 和加權平均。

- 推薦系統中為什麼要有召回?在召回和排序中使用的深度學習算法有什麼異同?
現代移動互聯網充斥着各種各樣的信息,如購物、新聞,短視頻,直播等等,經常使用户迷失在海量的信息中,無法找到真正感興趣的內容。
因此推薦算法應運而生,應用於各大領域:“吃”有美團、餓了麼等;“穿”有淘寶等;“住”有蛋殼、自如等;“行”有汽車之家等;“娛樂”有抖音、快手等;“旅行”有攜程、去哪兒等。
當你打開App,就會有各種的推薦場景映入眼簾,例如:猜你喜歡、為你推薦等。推薦主要是根據用户的歷史行為、相似用户、及相似物品等信息,進一步分析用户的消費點進而觸達用户。
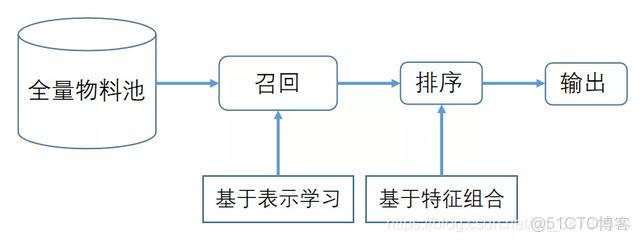
在工業推薦系統中,推薦系統包含兩個步驟:召回和排序。
(1)召回環節:主要根據用户部分特徵,從海量的物品庫裏,快速找回一小部分用户潛在感興趣的物品。此環節要求速度快。
(2)排序環節:排序環節可以融入較多特徵,使用複雜的模型,精準地做個性化推薦。此環節要求精度高。